ButterZ ☕️ أُعيد تغريده

구글이 공개한 AI 에이전트
1. AI 에이전트 기본 구조
bit.ly/4c6dDcg
2. 외부 연계 프로토콜
bit.ly/4tFN4AC
3. 컨텍스트 엔지니어링
bit.ly/3Q1P6N6
4. AI 에이전트 평가·테스트
bit.ly/4mneIQg
5. 프로덕션 운용 설계 지침
bit.ly/4spRLxe
한국어
ButterZ ☕️
13.7K posts

@softroom
오늘은 어제의 내일이 아니다. #WISENUT #NFT #CRYPTO @BinkiesNFT






🚨 Someone just open-sourced a tool that converts pdfs to markdown at 100 pages per second. It's called OpenDataLoader. It runs entirely on CPU and handles complex layouts, tables, and nested structures like a senior dev 100% Free.





원격으로 @OctopusET 님과 협업해 3시간 걸렸던 legalize-kr 빌드 과정을 21초로, 500배 빠르게 만들었습니다!! ✨🐸👍✨ github.com/legalize-kr/co… 병렬화, 해시 기반 delta 최적화, alloc 튜닝, git을 완전히 bypass하고 git fast-import/index-pack 을 러스트로 재구현 등 엄청난 해커톤이었습니다!
legalize.kr @junghwan 님께서 한국 법을 모두 git repo로 옮겨주셨다! 한국법령정보 MCP보다 얘가 훨씬 빠르고 편하다!!!! 코드 : github.com/9bow/legalize-… 이거 예전부터 하고싶었지만 은근히 까다로운 처리가 필요해서 미뤘던건데, 시간지나니 다 해주셨다 와와와와






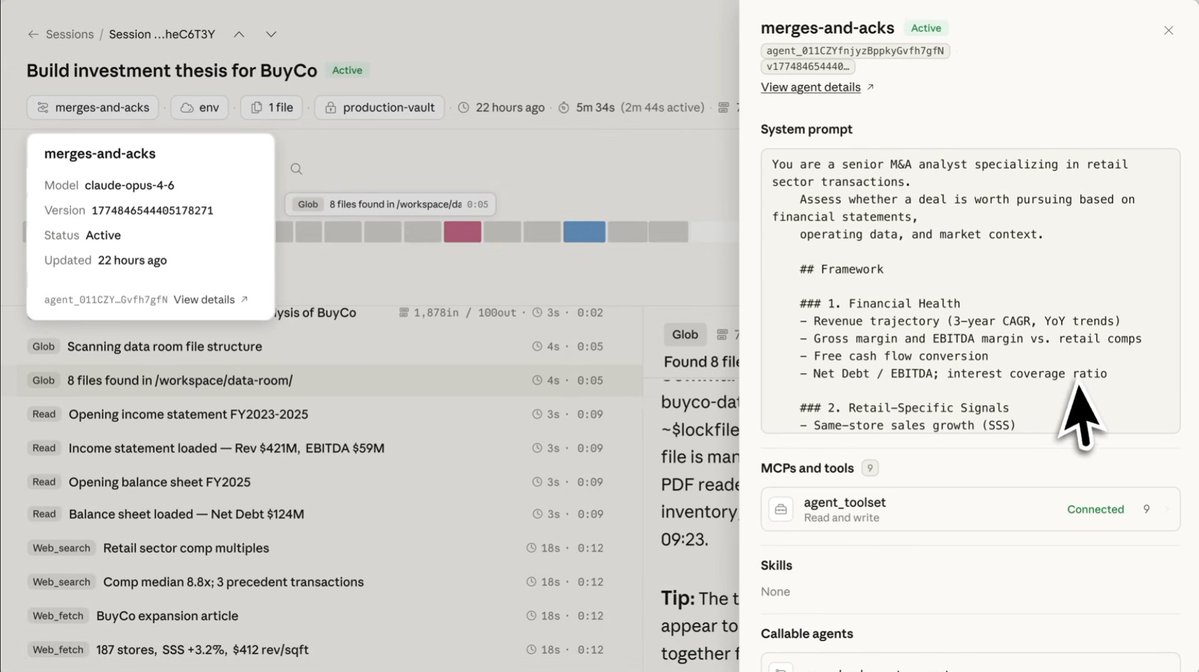
Thinktank를 만들었으니, 어떻게 사용하는지 보여드리겠습니다. 🧩① 수집 관심가는 글 보이면 봇에게 공유. URL, X 아티클, PDF, 이미지 다 됨. 봇이 크롤링 → 4단계 검증 → 토픽 분류까지 자동. 🧩② 탐색 DB에 저장된 가공된 정보들을 BOT 에게 명령해서 네트워크 그래프로 비주얼라이징 나도 몰랐던 관심사 패턴이 보여서 인지하기 좋음. 🧩③ 체득하기 하나의 생각으로 엮어보기 위해 필요한 관련 분석들 포워딩 → 3단계 귀납적 추론이 별개의 뉴스를 하나의 흐름으로 엮어줌. 🧩④ 글쓰기 (기존 사용하던 클로드 프로젝트) 3단계에서 가공한 자료를 바탕으로 초안 작성 🧩⑤ 결과물 아래는 봇의 추론 엔진을 가공해 실제로 뽑아낸 초안. (확인 용도로 스크롤만 내려보셔도 무방합니다) x.com/Spacepilot77/s… 수정 없이 그대로 공유합니다. Think Tank가 대필 작가는 아닙니다. 나를 분석하는 어시스턴트에 가깝습니다. 내가 관심있었던 지식들과의 상호작용이 나에게 어떠한 영향을 미쳤는지 스스로 정리할 수 없었지만 Think Tank가 도와줬습니다. 오늘 내 뇌에서 무엇을 받아들였는지 인지했으니, 내 관점을 더해 생각해보는건 가능합니다. 소수의 선구자들이 보여줬던 인사이트를 따라가기엔 많이 부족하지만 AI 와 함께, 조금은 더 생각하는 연습을 할 수 있습니다. 오늘도 Claude를 괴롭혀 봅니다 "해줘"

비개발자가 개인 AI 싱크탱크를 만들었습니다 @Bugi952 님과 @Spacepilot77 님이 링크 하나를 보내면 4단계가 자동으로 돌아가는 시스템을 만들었습니다. 출처 검증, 근거 태깅, 반박 시나리오, 본인 포트폴리오 적용성까지. 코드 한 줄 모르는 분이, 월 $4.59짜리 서버 위에서 만들었다고 합니다 "클로드에게 '해줘'만 반복했더니 개인 AI 싱크탱크가 만들어졌다." 이 말이 거짓이 아닌 세상으로 변하가는 것 같습니다. 저는 OpenClaw를 이야기하기 시작했을 때부터 쭉 봐왔습니다. 그때 관심 가진 분들 중 지금 진짜로 시스템을 만들고, 업무가 바뀌고, 하루가 바뀌고 있는 분들이 나오고 있습니다. 저는 그 흐름을 먼저 보고 정리해서 전달하는 역할을 하고 싶습니다. 물론 도움이 되는 에이전트 기술도 함께요 전 세계 능력자들이 아낌없이 재능을 공유하는 X에서, 저도 능력은 없지만 X에서 그 역할을 하겠습니다.


Repo: github.com/opendataloader… If you want more practical AI gems and use cases, join our free newsletter with daily tutorials and latest news in AI: simplifyingai.co
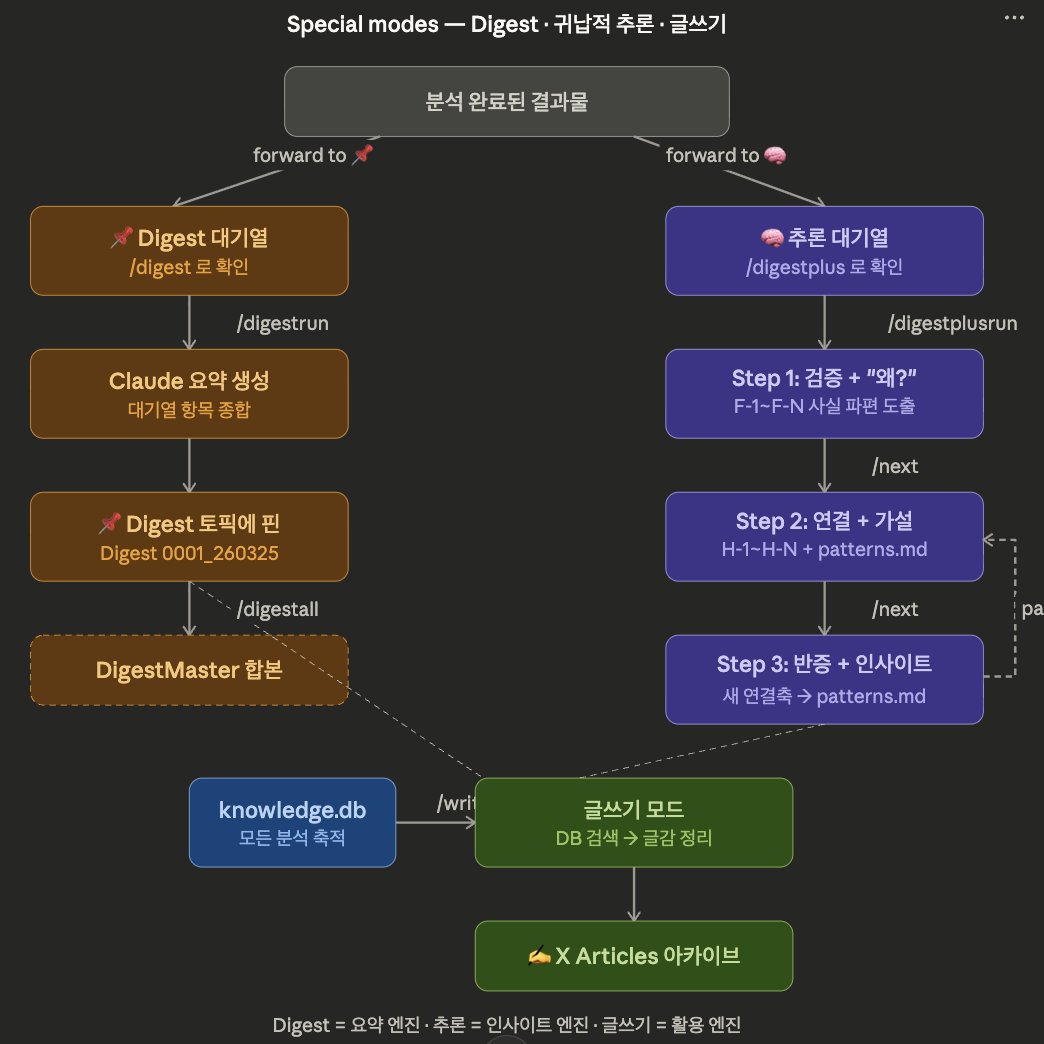
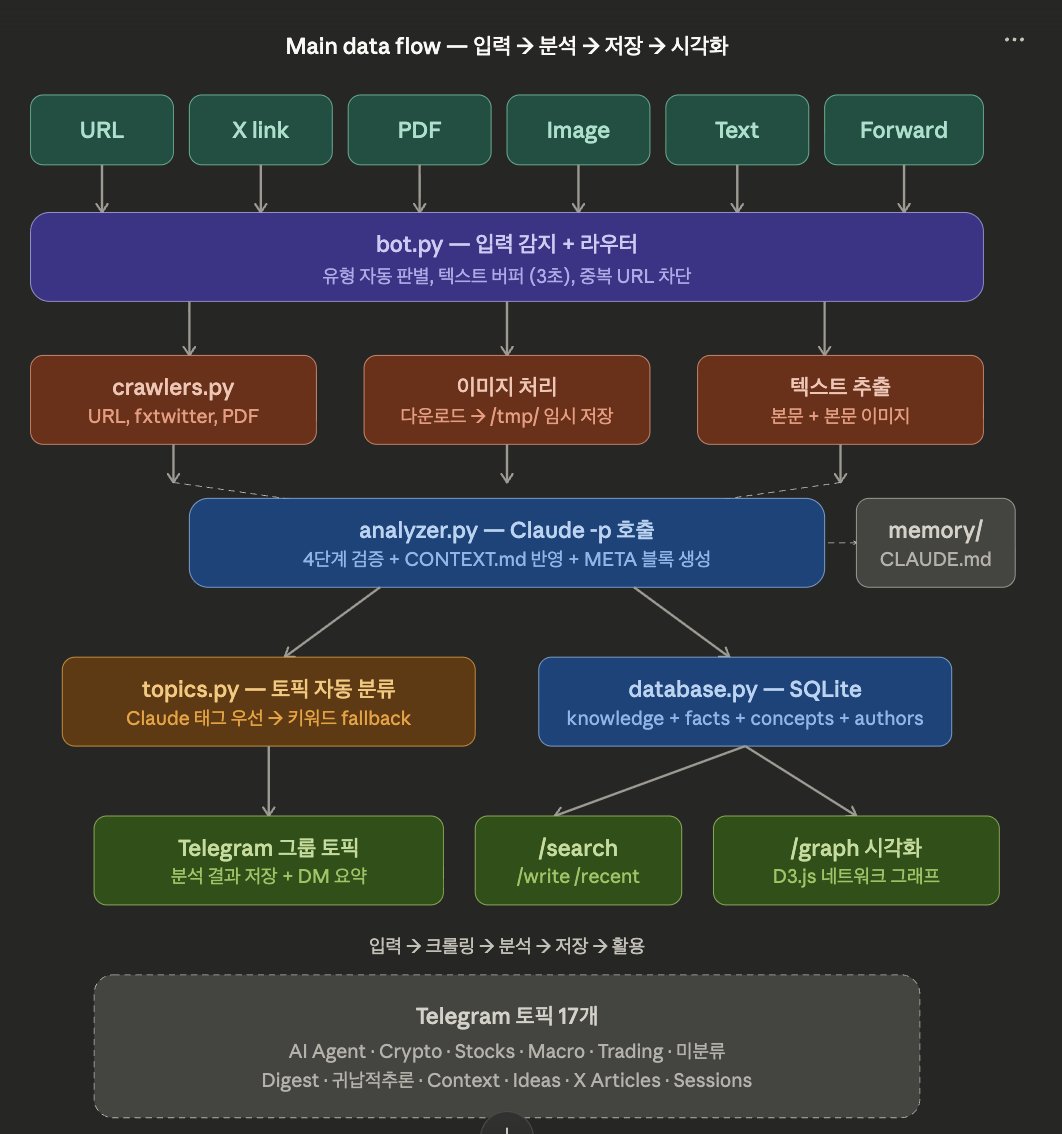
전체 빌드 과정을 기록으로 남깁니다. 3월 23일 오후 4시 ~ 24일 새벽 1시. 6번의 세션, 약 12시간. 코드는 한 줄도 직접 쓰지 않았습니다. ───────── ▸ 왜 만들었나 매일 수십 개의 기사, 트윗, PDF를 읽지만 "읽는 것"과 "아는 것"은 다릅니다. 규칙 하나를 세웠습니다. "그냥 받아들이지 않는다. 무조건 걸러서 넣는다." 모든 정보를 4단계로 검증하고, 내 포트폴리오와 관심사에 맞게 필터링해서, 텔레그램 봇으로 24시간 자동 운영. 도구: 1. Claude Code ( 기존 구독중인 모델은 Claude MAX ) 2. 월 $4.59 Hetzner서버 (Openclaw 글보고 덜컥 계약한 서버) 3. 텔레그램 토픽 기능 ───────── ▸ 타임라인 x.com/ralralbral/sta… @ralralbral 잔다르크님 글 참고 【세션 1】 설계 — 코드 0줄, 2시간 설계만 집중 • 4단계 검증 구조 설계 ① 출처 — 1차자료/전문가해석/2차요약 ② 근거 — 🟢사실/🟡해석/🟠추정/🔴의견 ③ 반대 시나리오 — 이게 틀리려면? ④ 적용성 — 나한테 영향이 있나? • 3중 기억 구조 설계 AI는 대화가 끝나면 다 잊으니까, memory/(서버내 Claude가 확인) + CONTEXT.md(현재 상태로 텔레그램 Topic 기능 활용) + sessions/(기록저장용) 세 겹으로 기억을 만들어줬습니다. x.com/Bugi952/status… @Bugi952 부기님 글 참고 【세션 2】 봇 기본 동작 + 자동 저장 • "✅ 수신 완료"만 답하는 코드에서 시작 • URL/X링크/PDF/명령어 자동 구분 • Claude -p 호출 연동 → 분석 결과를 텔레그램에 답장 • Claude 분석 → 토픽별 자동 저장 🔥 문제발생: 네이버 뉴스가 Claude 웹 접근 차단 → 봇이 대신 크롤링해서 텍스트로 전달하는 방식으로 우회 🧩 개입 ①: 이모지 태그 시스템 분석 결과가 텍스트 덩어리라 읽기 힘들었음. 모든 판단에 이모지 태그를 붙이자고 제안. 가독성이 완전히 달라졌습니다. 🧩 개입 ②: 처리 큐 4GB RAM 서버에서 Claude 동시 호출하면 터짐. 한 번에 하나씩, 대기 중 알림 표시. 【세션 3】 코드 분리 + X링크 + PDF 🧩 내 개입 ③: 500줄 넘어가자 수정할 때 자꾸 깨짐. Claude를 제지 시켜야했음. •기능별 6개 파일로 분리 요청. config.py — 설정값 utils.py — 유틸리티 crawlers.py — 크롤링 (URL, X링크, PDF) analyzer.py — Claude 호출 topics.py — 토픽 분류·저장 bot.py — 메인 실행 • X 트윗: fxtwitter API로 텍스트+이미지+인용 추출 • PDF: 213페이지 회사 매뉴얼, 22초 만에 처리 OpenDataLoader 채택 — Claude 추천 도구보다 속도 100배 이상 차이 (4.7초 vs 수 분). x.com/AI_bot_manager… @AI_bot_manager 봇트레이더매니저님 글 참고 【세션 4】 이미지 분석 + 24시간 운영 🔥 문제발생: Claude가 이미지를 못 읽음 3가지 방법 시도 후 전부 실패. → @파일경로 참조 방식 발견으로 해결. 🧩 개입 ④: 인용 트윗의 원문 이미지도 분석에 포함시켜라. 차트가 포함된 트윗을 인용한 경우, 원문의 차트도 봐야 맥락이 완성되기 때문(주로 트레이딩 관련) • systemd 등록 → 24시간 자동 운영, 죽으면 5초 후 재시작. 【세션 5】 PDF 챕터 분리 + 기능 기각 🧩 개입 ⑤: "이미지 개수가 아니라 챕터 맥락으로 쪼개줘" Claude는 이미지 50개씩 나누자고 했으나 거부. 내용 맥락이 깨지면 안됨. → 헤딩 기준 챕터 분리로 변경. 분석 품질 확실히 향상. 🧩 개입 ⑥: /study 모드 기각 Claude가 PDF 학습 모드를 제안. 여기서부터 슬슬 환각증세가 오는 것 같았음. "이 봇의 목적은 필터링을 통한 가공이지 학습이 아니다. Study 목적이면 NotebookLM이 더 잘한다. " → 코드 기각. →"이건 안 한다" 를 정하는게 점점 더 중요하다 느꼈습니다. 【세션 6】 텔레그램 완전 관리 🧩 개입 ⑦: Context 토픽 CONTEXT.md 수정하려면 SSH 접속 필요 → 귀찮음. 텔레그램에 🧠Context 토픽 만들고, 핀 고정하면 자동으로 CONTEXT.md 업데이트. 이제 텔레그램만으로 봇 설정 관리. 🧩 개입 ⑧: General 토픽에서만 분석 봇이 모든 토픽에서 분석을 시작해버리는 문제 발생함. → "분석은 General에서만. 나머지는 저장 전용." 안 잡았으면 자기가 저장한 걸 또 분석하는 무한루프. 🧩 개입 ⑨: 기사 본문 이미지 분석 BIS 달러 펀딩 체인 다이어그램이 기사에 있었는데 봇이 텍스트만 크롤링하고 이미지 무시. → 본문 이미지 추출 추가. 분석 품질 눈에 띄게 향상. ───────── ▸ 비개발자가 실제로 한 것 vs 안 한 것 내가 한 것: • 시스템의 목적과 철학 설계 • 4단계 검증 구조 설계 • 모든 기능의 필요성 판단 • 문제 발생 시 방향 제시 • 사용성 개선 아이디어 • "이건 안 한다" 기각 결정 내가 안 한 것: • 코드 작성 (0줄) • 라이브러리 선택 • 디버깅 • 서버 설정 ───────── ▸ 실제 비용 서버 추가 비용: 월 $4.59 Claude MAX 구독료: 월 ($0, $19, $110, $220~) (이미 쓰고 있던 것으로 본인의 사용량에 맞춰 사용하면 됨) 가장 큰 비용인 Claude MAX($110+/월)은 가변적인 전제 조건입니다. MAX 를 다른 용도로 구입했었고 취소하려던 참이었는데, 남은 기간이 아까워서 최대한 사용하고 싶었습니다. 어떠한 형태라도 Claude 구독 중이라면, 추가 비용은 $4.59 + 입니다. ▸ 서버 12시간 후 사용량 RAM 10% | 디스크 8% | CPU 거의 유휴 $4.59짜리 서버의 10%도 안 씀. ───────── 코드를 몰라도, 시스템은 설계할 수 있습니다. "뭘 만들 것인가"와 "어떻게 만들 것인가"는 다른 능력입니다. 상상한 뒤 말합시다. "해줘"