Dwarkesh Patel@dwarkesh_sp
New blackboard lecture w @ericjang11
He walks through how to build AlphaGo from scratch, but with modern AI tools.
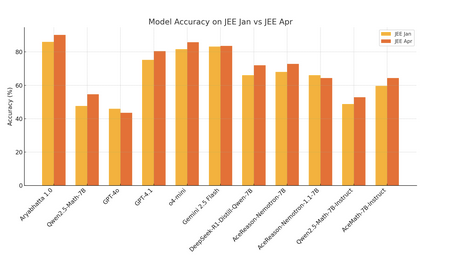
Sometimes you understand the future better by stepping backward. AlphaGo is still the cleanest worked example of the primitives of intelligence: search, learning from experience, and self-play. You have to go back to 2017 to get insight into how the more general AIs of the future might learn.
Once he explained how AlphaGo works, it gave us the context to have a discussion about how RL works in LLMs and how it could work better – naive policy gradient RL has to figure out which of the 100k+ tokens in your trajectory actually got you the right answer, while AlphaGo’s MCTS suggests a strictly better action every single move, giving you a training target that sidesteps the credit assignment problem. The way humans learn is surely closer to the second.
Eric also kickstarted an Autoresearch loop on his project. And it was very interesting to discuss which parts of AI research LLMs can already automate pretty well (implementing and running experiments, optimizing hyperparameters) and which they still struggle with (choosing the right question to investigate next, escaping research dead ends). Informative to all the recent discussion about when we should expect an intelligence explosion, and what it would look like from the inside.
Timestamps:
0:00:00 – Basics of Go
0:08:06 – Monte Carlo Tree Search
0:31:53 – What the neural network does
1:00:22 – Self-play
1:25:27 – Alternative RL approaches
1:45:36 – Why doesn’t MCTS work for LLMs
2:00:58 – Off-policy training
2:11:51 – RL is even more information inefficient than you thought
2:22:05 – Automated AI researchers