Andrew retweetet
Andrew
1.3K posts


Andrew retweetet

This dude mastered the art of “reverse walking.”
English
Andrew retweetet

Google Calculator - it's a feature, not a bug 🫠
Thanks to chandrashekar316 for sharing
English
Andrew retweetet

🐇На охоте собака бежит за зайцем по запаху и не смотрит по сторонам. Заяц, понимая это, делает вот такой «финт ушами» и мастерски уходит от погони.
Русский
Andrew retweetet


Andrew retweetet

Andrew retweetet

Andrew retweetet

can YouTube FUCK OFF with this auto translation bullshit nobody fucking asked for
I set my language to English, I even fucking set my REGION to United Kingdom, and it STILL translates random video titles and descriptions for NO FUCKING REASON
look at the channel. this is a TechRax video. HE DOES NOT MAKE GERMAN VIDEOS
and it’s not even every video title that does this it’s just randomly fucking selected and for WHAT
JUST LEAVE THE FUCKING VIDEOS ALONE AND SERVE THEM THE WAY THE CREATORS WANTED GOOGLE FFS

English
Andrew retweetet

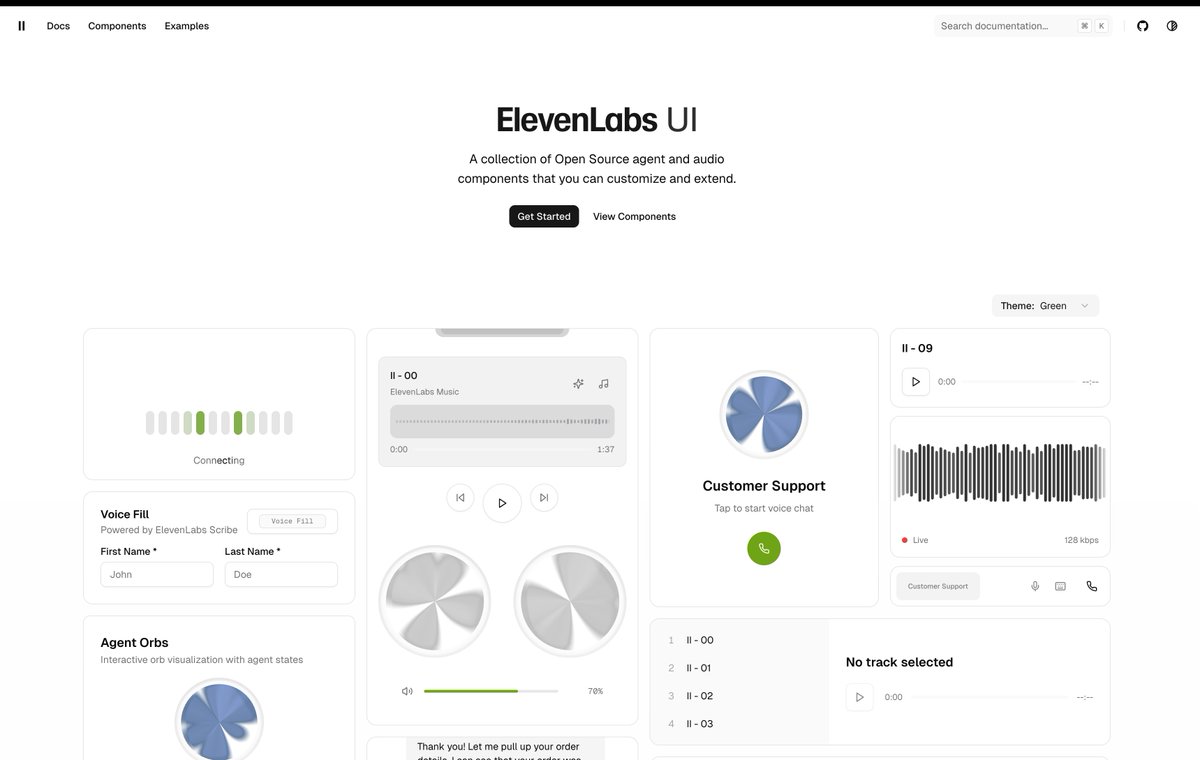
Elevenlabs just open sourced a bunch of their audio UI components. These look really good.
Link on the thread
English
Andrew retweetet

New paper 📜: Tiny Recursion Model (TRM) is a recursive reasoning approach with a tiny 7M parameters neural network that obtains 45% on ARC-AGI-1 and 8% on ARC-AGI-2, beating most LLMs.
Blog: alexiajm.github.io/2025/09/29/tin…
Code: github.com/SamsungSAILMon…
Paper: arxiv.org/abs/2510.04871
English
Andrew retweetet

Andrew retweetet

Andrew retweetet


Andrew retweetet

Andrew retweetet

Andrew retweetet

.@DemNikoArt presented his seven-part course on mechanical rigging in Blender on Gumroad.
Get the course: 80.lv/articles/3d-ar…
English
Andrew retweetet

Локальные LLM: Введение. Что происходит, когда вы запускаете LLM?
Нашел, офигел от плотности информации, перевел и адаптировал для вас. Ссылка на источник в следующем твите.
Работа модели по другому называется inference (вывод) или использование весов модели. Вывод — по сути предсказание следующего токена на основе вашего ввода и всех токенов сгенерированных на предыдущих шагах. Все это образует последовательность.
Токены — это не слова. Токены это кусочки обозначающие текст, который видит модель. В модели они представлены целыми числами или ID токенов. Токенизация — разбиение текста на токены. Распространенные алгоритмы: BPE (byte pair encoding), SentencePiece. Конкретные токены отличаются в разных моделях. Вот иллюстративный пример: “hello” \- может быть 1-3 токена, “internationalization” 5-8 токенов.
Контекстное окно \- максимальное количество токенов, которые может увидеть модель за раз. Чем больше context тем больше VRAM для KV кеша потребуется и тем медленнее будет декодировка.
В процессе вывода модель предсказывает следующий токен перемножая свои веса. Веса модели \- это миллиарды выученных параметров. Параметры модели \- миллиарды чисел или весов, которые модель усваивает в процессе обучения. Эти веса кодируют все что модель знает: шаблоны, язык, факты, “мышление”. Когда вы используете модель, она использует эти параметры, чтобы предугадать следующий наиболее вероятный токен. Один токен за раз. Шаг за шагом.
Т.е. модель не дает ответ, а выдает наиболее вероятные кусочки текста составляя их в цепочки пока не решит, что выдача завершена сгенерировав спец стоп токен \`\<|endoftext|\>\`
Получается цикл: модель получает ввод, выбирает следующий токен, добавляет его к выдаче и передает всю новую выдачу обратно себе на вход.
Но модель это чуть больше чем просто файл с весами:
* Архитектура нейросети: трансформер (слои, головы внимания heads, RoPE, MQA/GQA об этом ниже)
* Веса: миллиарды изученных чисел. Параметров, не токенов, но вычисленных из токенов
* Токенизатор: для кодирования текста в токены. BPE/SentencePiece
* Конфиг: метаданные, спец токены, лицензия и тд
* Иногда шаблоны чатов необходимые для chat/instruct моделей. Иначе эти модели выдают мусор
Модели отличаются по количеству параметров
* 7B означает 7 миллиардов чисел
* Чем модель больше тем она мощнее, но тем больше VRAM и вычислений требуется для ее работы
* Модели вычисляют вероятность следующего токена (гоняя softmax по своему словарю vocab) тут у модели будет несколько токенов на выбор
* Далее она выбирает один или с наиболее высокой вероятностью (greedy) или начинает креативить в зависимости от temperature, top-p и других настроек.
* Потом она добавляет этот один токен к тому что у нее уже есть и повторяет заново как я и описал выше.
* Все токены из текущей сессии находятся в KV кеше
Как модель выбирает токен (sampling):
* greedy \- выбирает самый вероятный как робот
* temperature: немного расслабляет вероятности и позволяет модели креативить
* top-k: выбирает из top k
* top-p: выбирает из самой маленькой группы с вероятностями ≥p
* Чтобы получить детерминированную выдачу \- устанавливаем seed и отключаем sampling
Больше там никакой магии нет.
Большинство современных моделей основаны на архитектуре Transformer. Они специально задизайнены для последовательных данных таких как наш язык. Трансформеры могут смотреть назад на предыдущие токены чтобы решить какие из них наиболее важны для следующего предсказания. Трансформер прогоняют вывод через множество слоев уточняя вывод, используют специальные механизмы “внимания” чтобы сфокусировать предсказание на важных частях ввода и контекста. Каждый новый токен проходит через весь этот пирог.
Каждый слой состоит из:
* Self-attention или внимание: определяет какие из токенов важны для текущего предсказания
* MLPs (multi layer perceptrons): чтобы добавить нелинейность и перчинку
* Стабилизация residual \+ norms чтобы это не развалилось и работало с глубокими сетями
* Позиционное кодирование (RoPE) чтобы модель знала где токен находится в последовательности и не путала кота и котастрофу :-)
Накладывая десятки и сотни таких слоев трансформер пытается “понять” ваш запрос, контекст и историю разговора. Чем больше слоев в голов внимания у модели тем умнее модель.
Чтобы работать с моделью ее надо вгрузить в VRAM. Количество должно позволить вгрузить 1\. Веса 2\. KV кеш. Примерные формулы: FP16 \- 2 байта на параметр (7B \- 14Gb), 4 бита \- уже 3.5Gb. Учитывайте еще 10-30% на оверхед. KV кеш стоит около 0.5 мег на токен и зависит от модели. Т.е. 4к токенов \- это еще 2 гига памяти. Некоторые рантаймы позволяют квантизировать и кеш в том числе позволяя экономить большое количество памяти.
Получается, что недостаточно просто впихнуть модель в память, надо чтобы она еще где\-то работала.
И чтобы она работала быстро пригодится Memory bandwidth \+ GPU FLOPs. Именно поэтому некоторые старые видюхи у которых шина пошире будут работать быстрее чем новые модели с более узкой шиной. Так NVIDIA RTX 2080 Ti (2018, 352-битная шина) имеет \~616 ГБ/с bandwidth и часто обходит RTX 4060/4070 (2023, 128/192-битные шины, \~288–504 ГБ/с) в LLM-задачах, несмотря на меньшее количество CUDA-ядер.
Вычисления можно переложить на CPU, но это существенно ощутимо болезненно медленнее.
Квантизация модели дает колоссальную экономию памяти зачастую при незначительной потере качества. 4-бит (NF4/GPTQ/AWQ) квантизация может быть оптимальной для потребительских GPU. Но нужно учитывать, что сложные мат задачи деградируют первыми: математика, логика и кодинг.
Рантаймы, где гонять
* pytorch \+ safetensors: гибко, стандартизовано, GPU/TPU/CPU
* GGUF (llama.cpp): CPU/GPU/portable лучший выбор для квантизации и для устройств “на крае”
* ONNX, TensorRT-LLM, MLC: для спец оборудования
* Избегайте bin по причинам безопасности
Компромиссы повсюду. Балансируйте компромиссы под свою задачу и бюджет.
Как раздавать
* vLLM для параллельных запросов
* llama.cpp server с OpenAI совместимым API
* EXLlama v2/v2 Tabby API с OpenAI совместимым API
* Просто как локальный скрипт через CLI
Локальная модель не значит Offline, а значит что работает на твоем железе. Твое железо может быть под столом, а может быть и в облаке.
Коротко о Fine Tuning
* Большинство задач можно решить через правильный промт \+ RAG
* Для файнтюнина необходимо раздобыть данные
* Делаем adapter layers на LoRA/ QLoRA на своем домашнем железе если сильно хочется
Наиболее частые проблемы
* OOM кончилась память. Квантизуем модель или сокращаем контекст
* Плохая выдача. Проверь chat template, temperature
* Медленно работает? Неправильные драйверы, нет FlashAttention, проверь свое железо CUDA/ROCm/Metal, влазит ли оно в память
* Небезопасно? Не используй bin модели от рандомов из интернета
Зачем все это?
Запуская модель на своем железе вы получаете все управление в свои руки: механизм выбора токена sampling, chat templates, декодирование, системные промпты, квантизацию, контекст. Больше не платите за каждый токен. Только за железо и электричество. Приватность. Отсутствие Network latency.
Русский
Andrew retweetet

Conflict 3049 is an amazing "Command & Conquer"-style game, in 3d, by a solo-developer, made with #raylib, in C#, in a single ~32000 locs file! ❤️
SOLID, take that! 😉
Михаил Сабольц ☭@c0d3rguy
Have you ever compiled a single source file named `game3d.cs` that was 32510 lines long. Me neither, until today! ``` $ wc game3d.cs -l 32510 game3d.cs ``` The game is matty77.itch.io/conflict-3049, and uses Raylib.
English
Andrew retweetet

Andrew retweetet

Have you ever compiled a single source file named `game3d.cs` that was 32510 lines long. Me neither, until today!
```
$ wc game3d.cs -l
32510 game3d.cs
```
The game is matty77.itch.io/conflict-3049, and uses Raylib.

English