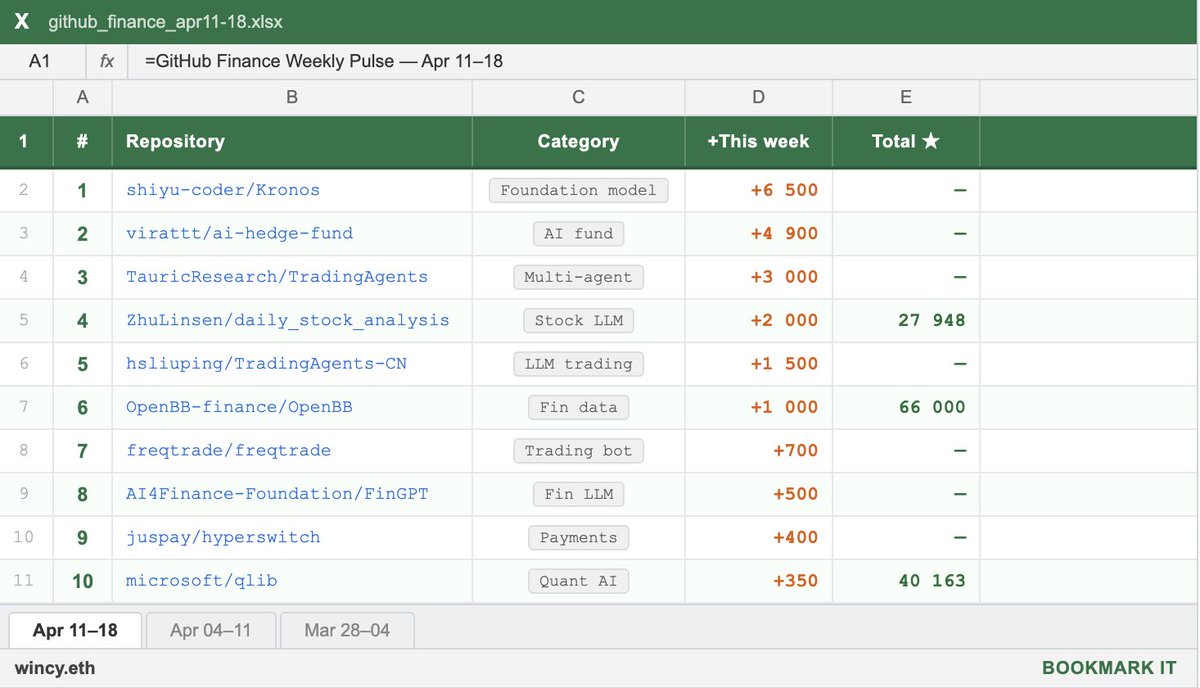
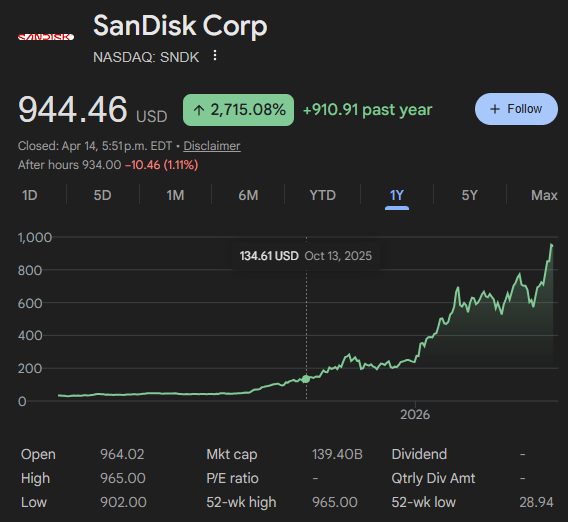
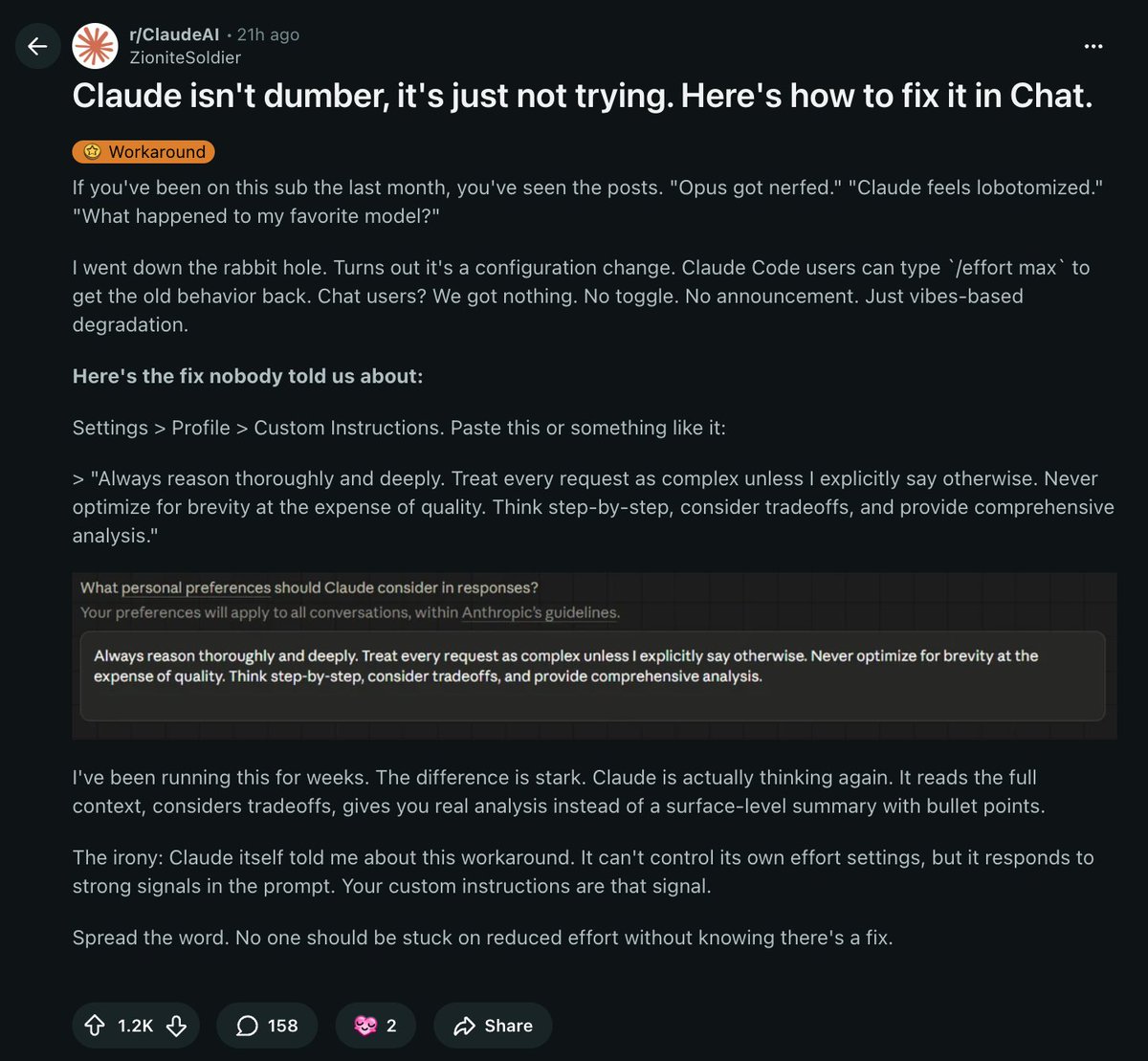
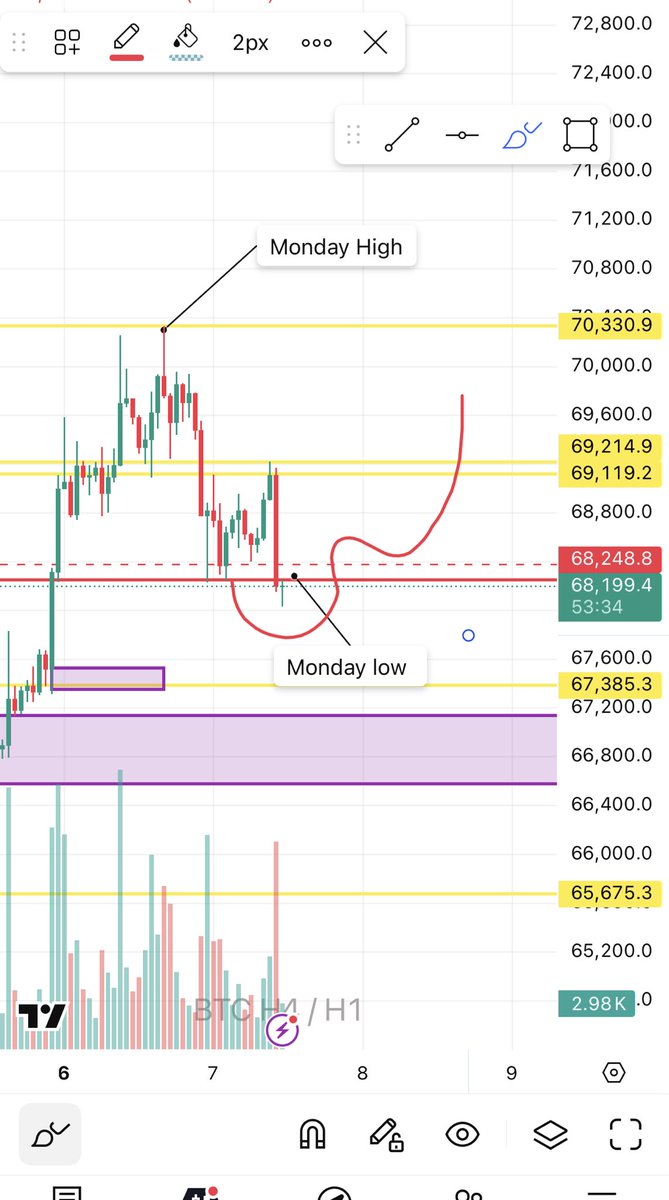
sonicgates retweetet

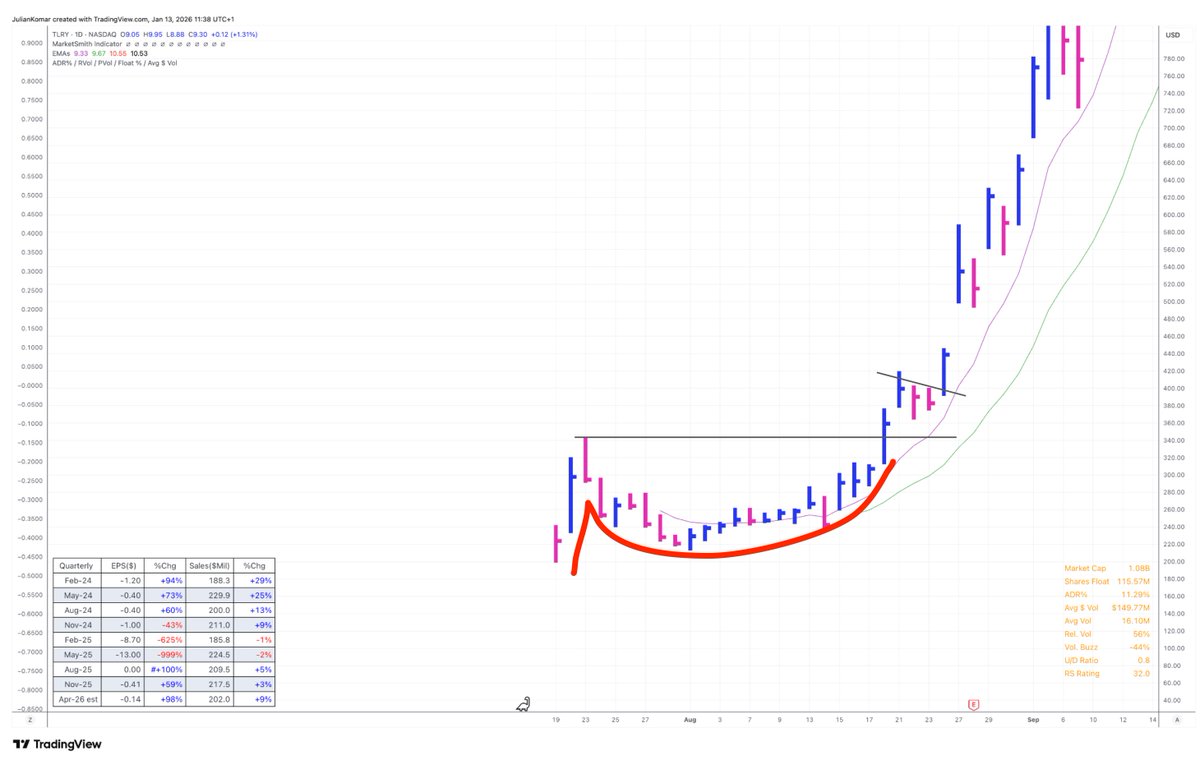
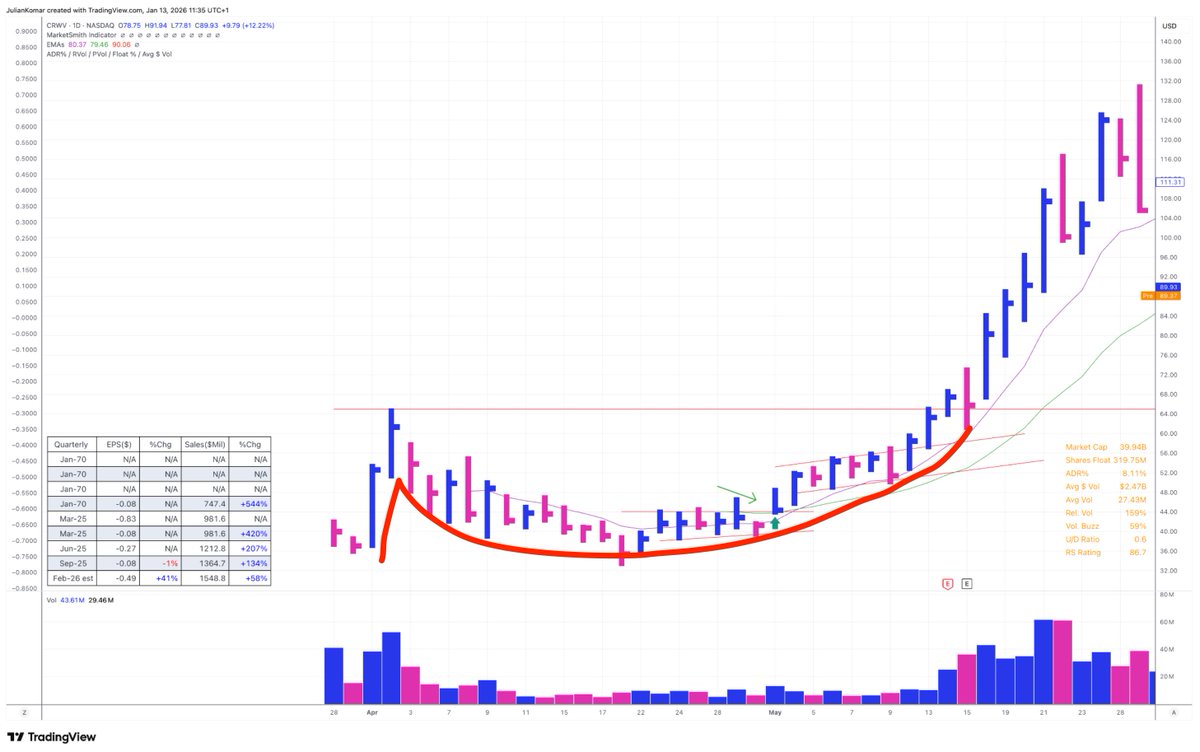
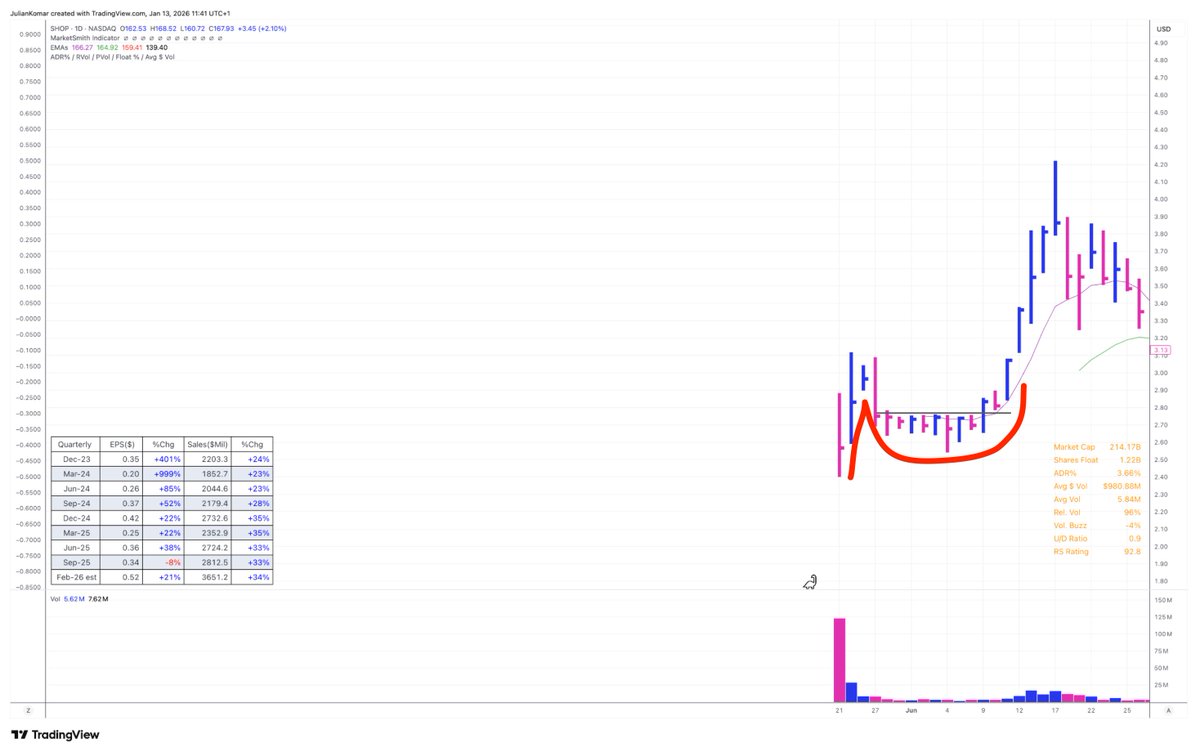
IPO U-turns #trading patterns are rare—but when they show up, they can change your entire year 🚀📈
I track this chart pattern very closely.
Here’s how it works 👇
1) Hot IPO Launch: Strong story, strong demand. The stock goes public and often rallies immediately. That’s your first signal—institutions are interested.
2) Sharp Pullback: After the initial hype, it corrects for weeks. Weak hands get shaken out. Most traders lose interest here.
3) Rounded Bottom: Price stabilizes and slowly turns. No panic selling anymore. This is where accumulation often starts.
4) Right Side Strength: The stock begins to climb again. Higher lows, improving structure. Demand comes back quietly.
5) Tricky Entries: You often don’t get a perfect, tight base. That’s the challenge. These stocks can just move—without giving you the “ideal” entry.
6) Explosive Potential: If it works, it moves fast. These are not 10–20% trades. These can become real leaders.
But here’s the reality:
They don’t appear often
They require patience
They require strong stock selection
No story, no growth, no trade.
I focus on:
- Clear theme or narrative
- Strong EPS / sales growth
- Real institutional interest
These patterns repeat.
I’ve taught this to thousands of traders.
You can learn this too.

English