@0xRemakw @thsottiaux Yes, I have been using codex for long now. It definitely feels like the limit is bit decreased as previously I was not able to use 100%.
English
SupermanSpace 𝕏
2.2K posts

@superman_space
Tech Researcher - Gamer - Open Searcher 😎 ||Fun Fact|| 📊Numbers leads to 👀 Bias.




Introducing YourGPT Campaigns 🚀


why does every AI client handle MCP config differently?? cursor here, vscode there, windsurf somewhere else… i just want ONE place





LIVE at 10:30am PT: The future of OpenAI and Q&A with @sama and @merettm Bring your questions. openai.com/live


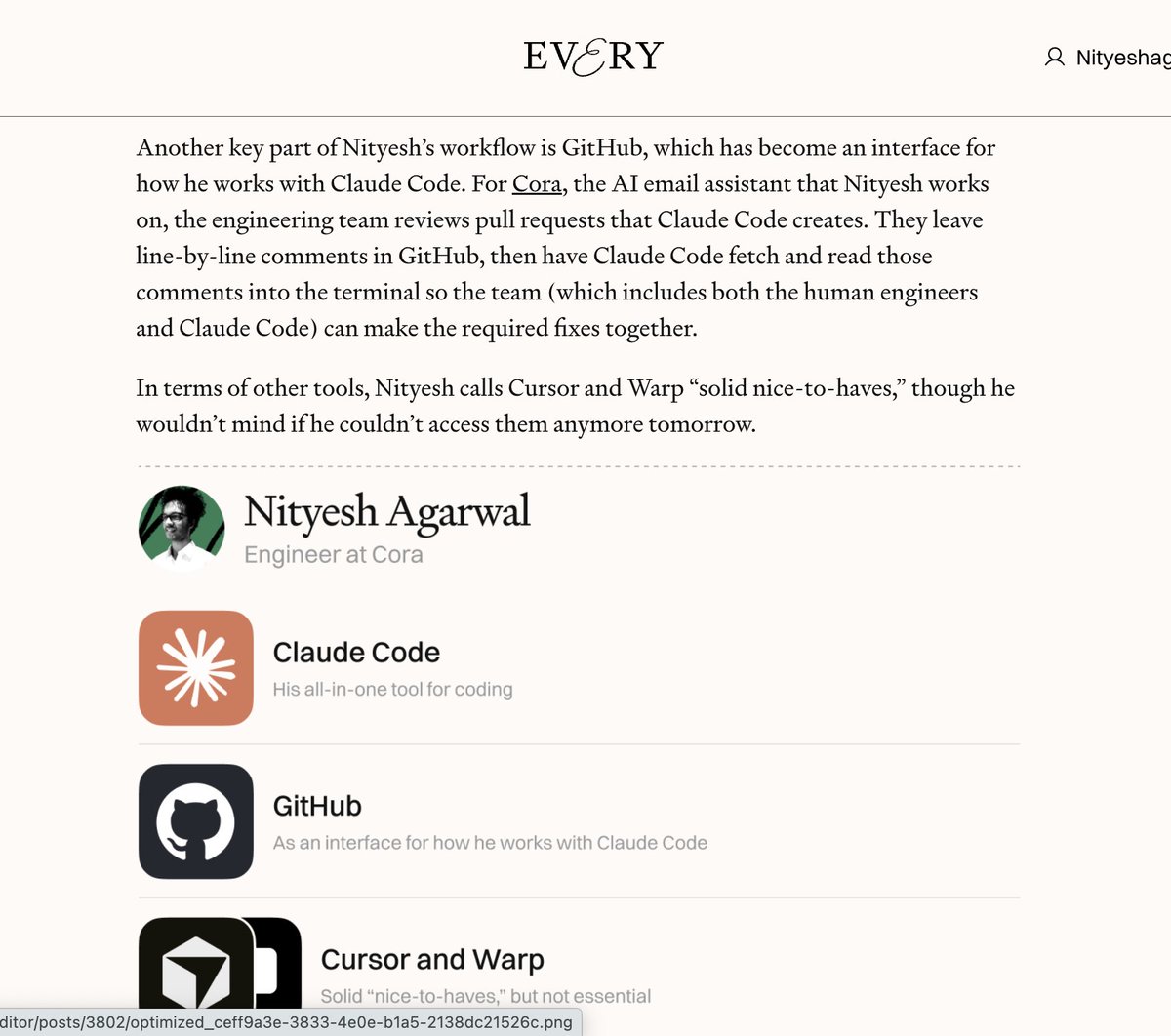
absolute must read every.to/source-code/in…