⌀ phantom.ctx retweeté

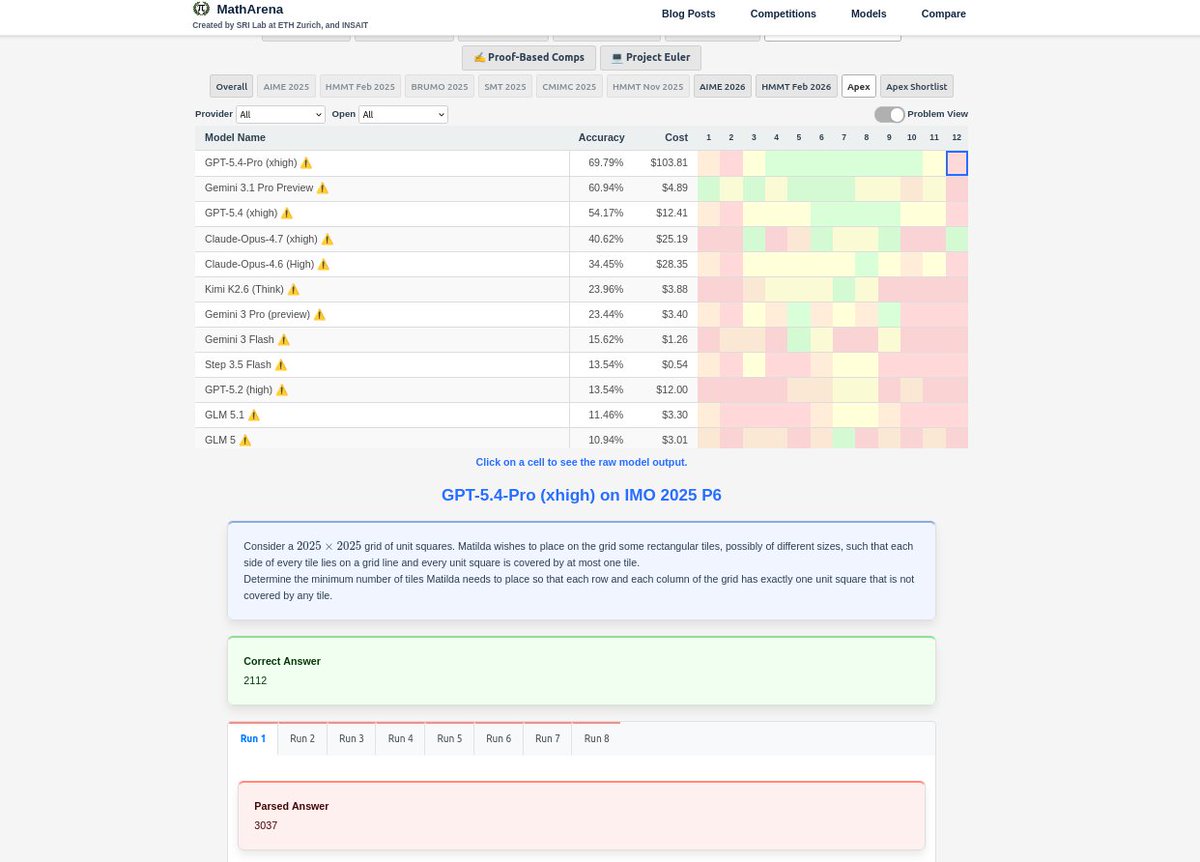
xAI has launched grok-voice-think-fast-1.0, its new flagship voice model. The release brings a major upgrade to voice AI for real business use. The system is now available through the @xai API and powers voice features in Grok across web, iOS, Android, and X.
The model handles complex, multi-step tasks with ease. It manages ambiguous requests, high-volume tool calls, and precise data collection in areas such as customer support and sales.
Real-time reasoning runs in the background with zero added latency, keeping conversations fast and natural.
Performance stays strong even in tough conditions. It copes with background noise, heavy accents, interruptions, and quick speech while supporting more than 25 languages. These traits make it ready for global enterprise deployments.
English