Jonathan Herzig がリツイート

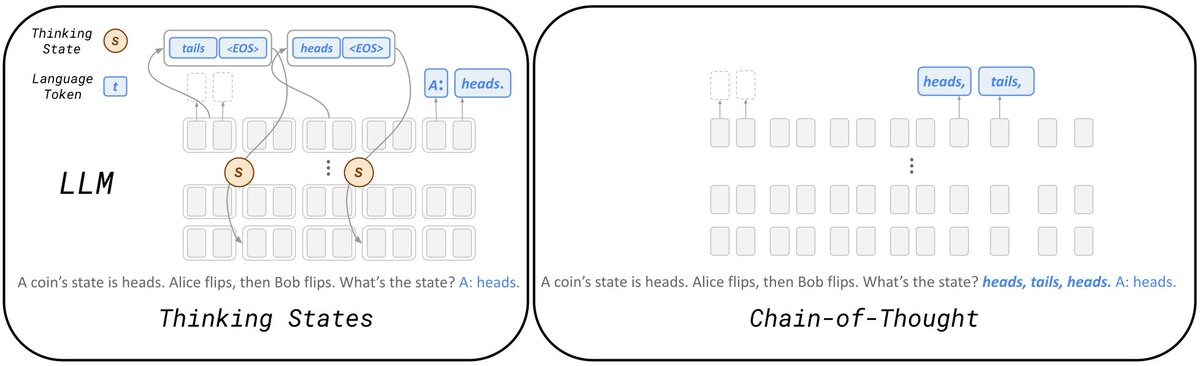
Thinking to Recall
How Reasoning Unlocks Parametric Knowledge in LLMs
paper: huggingface.co/papers/2603.09…

English
Jonathan Herzig
93 posts









I'll be at #EMNLP2024 next week to give an oral presentation on our work about how fine-tuning with new knowledge affects hallucinations 😵💫 📅 Nov 12 (Tue) 11:00-12:30, Language Modeling 1 Hope to see you there. If you're interested in factuality, let’s talk!

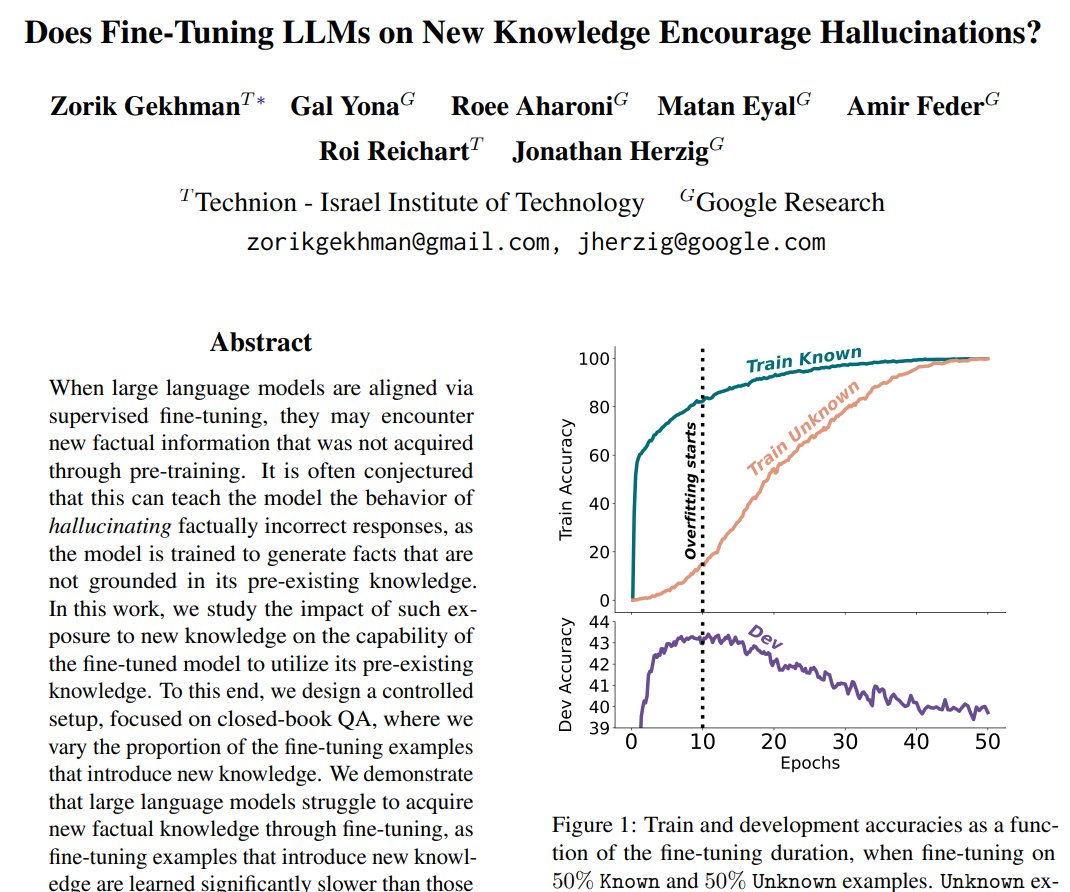
Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? New preprint!📣 - LLMs struggle to integrate new factual knowledge through fine-tuning - As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫 📜arxiv.org/pdf/2405.05904 🧵1/12👇











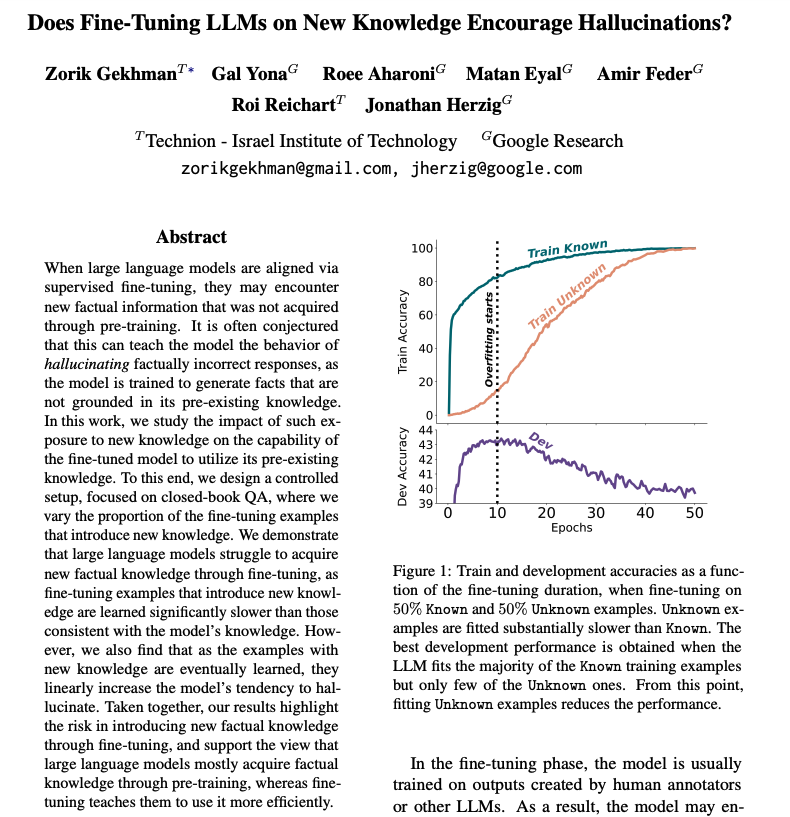

Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? New preprint!📣 - LLMs struggle to integrate new factual knowledge through fine-tuning - As the model eventually learns new knowledge, it becomes more prone to hallucinations😵💫 📜arxiv.org/pdf/2405.05904 🧵1/12👇
Google presents Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations? Highlights the risk in introducing new factual knowledge through fine-tuning, which leads to hallucinations arxiv.org/abs/2405.05904