Sabitlenmiş Tweet

7年区块链老人,为什么还在crypto里玩耍?
我是在2018年才知道btc的, 那时候在刚来互联网公司上班,也才研究生毕业没两年, 组里有人组织了外部人员的区块链分享, 我当时完全不知道是个啥,什么账本,什么挖坑
但我隐隐感觉它是个有意思的东西, 尤其我我听到不可篡改的公共账本,还有数据主权,个人绝对所有权等,我立即就被击中了
当天就决定我要买入, 找到同事了解到了火币交易所,然后果然开户尝试买入第一笔100人民币的,然后开始学习研究,学习了两个月后,我知道btc的全部逻辑,也被它货币主权的叙事深深吸引,然后对于“至少拥有一个btc”的说法很认可,
那时候我简直找到了一个新的人生方向, 我天生反感集体主义,厌恶扼杀个性而强调集体的花束, 我也厌恶所谓有一个权威可以依赖,或者所谓让渡自己的权利去换取一些安全和保障,或者把自己的命运交给一个更大的掌舵着…等等诸如此类的,都是我嗤之以鼻,我认为每个人都应该为自己负责,甚至如果觉得每个人都自私一点,都只为自己考虑,放下那些助人之心, 放下所谓关爱,所谓“为你好”… 这个世界或许会更加让人舒适(不是美好,而是舒适)
在这样的一个自我个性下,我1000%的 buy in 区块链的叙事,且愿意投入自己的财富去压住, 所以我当时用蚂蚁借呗借款了30万以差不多9000美金的价格买入了3-4个btc, 我当时坚信这是一笔值得投入的资金,且就算30万亏逛逛,就当我一点上班白干了, 也无妨, 我还年轻。。
在这样的信念下,我一直对区块链充满期望,甚至在2021年从辞职创业,试图使用区块链技术打造一个去中心化数据库,以实现更便利的个人数据主权(当然很快就证明了这个伪命题)
跟大部分炒币人都经历过的一样,在这7-8年里,我的资产达到了财富自由的峰值然后又跌入破产, 在一个一个叙事中犀利,一开始充满信念,然后破碎,发现那只是一个故事,我们只是那些讲述故事的人的流动性,
回头来看,我几乎将我这上边8年来的全部资产和精力都投入到了区块链, hold, 合约,meme, 开发工具,投资,搞基金, 爆仓,赔钱,现货跌99%...
直到25年初,我意识到,我的财富在别人的故事和自己的无知中流失殆尽, 我本不是投资人, 对任何项目和他们的团队都一无所知,靠着道听途说的3手信息,去投资hold,( 甚至一度自我洗脑,认为这是web3的伟大,普通人都能参与任何一个项目的最开始种子轮融资,陪着项目一起成长,而不用像传统上市公司,我们能交易股票都是经历了N轮之后的残羹剩饭, 是的,我的认知只有指甲盖那么大,却在主动为这个行业规划构建一个摩天大厦)
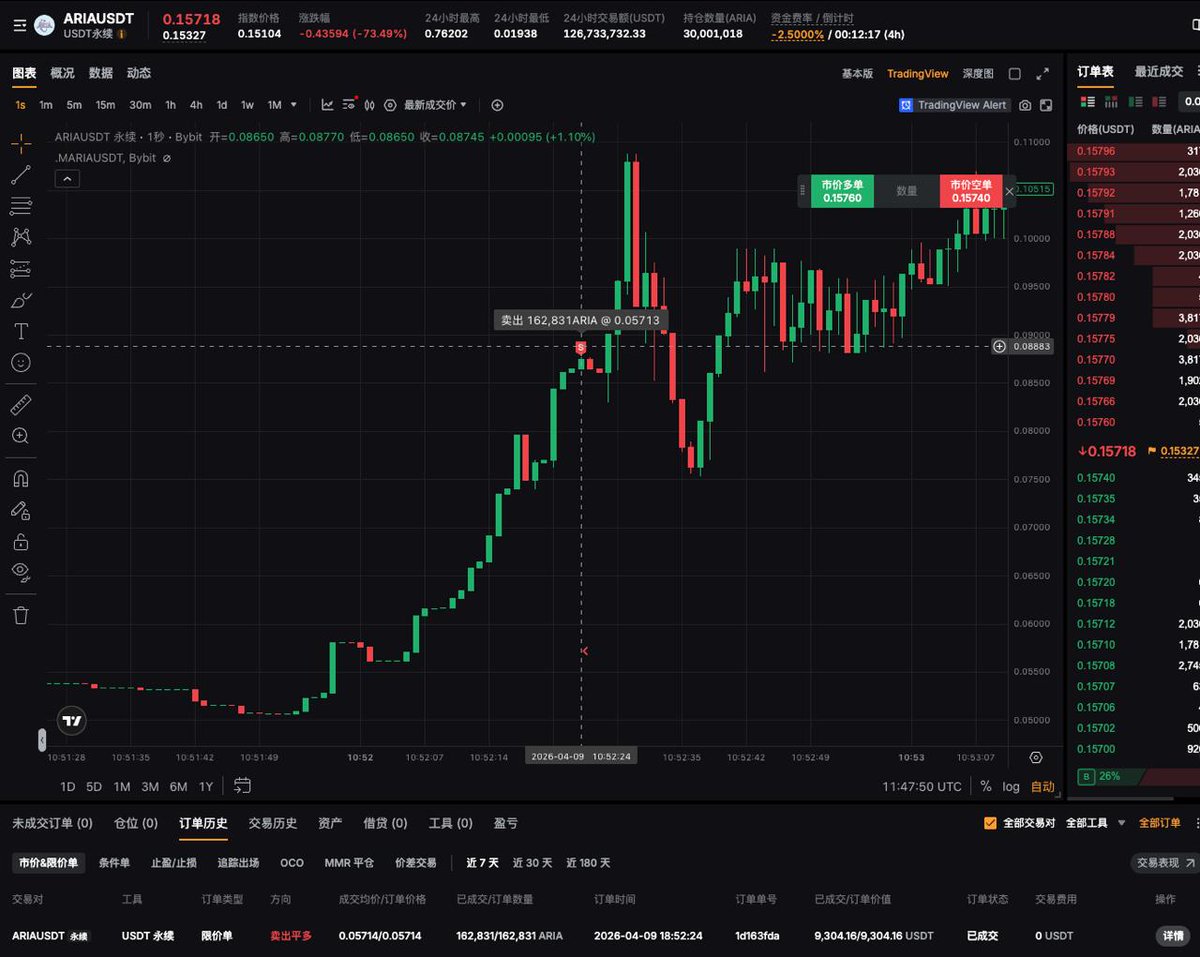
也就是这时候,随着我的资产在此归零,我也开始从零构建我的套利系统,直到这个时候,我才意识到,自己手中的这点usdt是多么的宝贵,它是你真正的生成资料,它是具备将1块钱变成1.1的能力的, 或者是说,我自己是有能力将它从1块钱变成1.1块的, 而不是扔到一个莫名其妙的项目里祈祷,祈祷背后某个力量能帮我打工,何其愚蠢至极。 当我的套利机器第一次开始盈利的时候,我意识到,只有自己才是那个人,只有自己才能依赖, 你需要的是非常专注,非常深入的投入,为自己投入的那1USDT注入力量,让它变成1.1, 1.2.., 唯有自己!!
从那时候之后,我不在buyin 任何故事了, 包括btc的故事,ETH的故事, 对我来说,他们的故事是什么都不再重要, 我只关注自己是不是能将1USDT变成1.1USDT,如果不是依赖自己力量,而是依赖一个故事,祈祷某个资产涨,那都是痴人说梦,它今天能涨,明天也能跌,而且,我不认为在任何一个领域,你不做任何的智力或脑力的投入,简单所谓的hold就就能得到长期的财富,永远不可能。
说到这里,我为区块链感到一丝丝悲哀,像我这样的,一个过去如此“信仰” 区块链,btc的人,也开始质疑,这不得不说是区块链的一大损失, 损失了一个这样忠实的信徒,我想这样的人应该不仅仅只有我一个。 当然,这样的表述也许有误,失败的是那些宣传故事,宣传信仰的人,btc从一开始就没变过,它并没有宣传任何信仰,任何叙事,它只是一套规则,自顾自的运转在那里, 信与不信,它都在这里。
而我为什么现在还是在玩区块链,我开发量化系统,未来会基于它开发应用,开发产品等等。我的那个人主权的自我从来没有变过,比如,直到现在我依然不会把钱存在银行里, 也不会投资第三方托管的理财, 甚至都不会购买保险。 可以确定的是,未来10年时间里,我投入依然是围绕区块链,及时做ai产品( 我现在在一个ai公司上班,每天都在做ai相关的工作,从底层训练调度,到模型微调,到agent,开发应用) , 作为一个同时深入了解两个领域的程序员,及时目前我发现貌似ai带来的金钱收益远大于区块链给我带来的收益,我依然很热爱这个行业,应为它的开放性,它的黑暗森林,它的弱肉强食, 它的自我为主体性,让我觉得舒适。
过去很长时间,我是陷入迷茫的状态, 在各种叙事的起起伏伏,生生死死的找不到方向,而现在我内心非常安定, 现在不在关注故事,不在关注宏观趋势,不在关注经济指标,不在关注涨跌, 这些统统都跟我无关了, 我选在区块链里主动玩耍而不是被玩耍, 我只在乎一件事情,区块链是否还会继续存在… hope so ..
(此文在半个多小时内一次写完,格式混乱请见谅)
中文