Binhang Yuan retweetledi
Binhang Yuan
59 posts

Binhang Yuan
@Hades317
Asst. Prof.@HKUST, Postdoc.@ETH, Ph.D.@RiceUniversity, ML Systems, fan of @LFC.
Hong Kong Katılım Şubat 2014
403 Takip Edilen227 Takipçiler

Binhang Yuan retweetledi

📘 Holiday read! From Software Engineer to AI Environment Architect
🚀 Tldr of our blog: We see an exciting future where engineers 👩💻 won’t stop coding — but the highest leverage shifts to designing the environments 🛝 where AI can think, build, and evolve.
🎬 Demo: Inspired by opinions from @karpathy @RichardSSutton, our newly built framework Vortex shows this in a concrete action: by architecting the right environment in LLM serving systems, an agent from @OpenHandsDev can generate and implement new Sparse Attention algorithms on @sgl_project in a single run and deliver up to 4× ⏩ gains — work that normally takes an ML-systems engineer weeks.
- In the short term, these environments let AI agents contribute meaningfully to real engineering work today.
- In the long term, they become the playgrounds where future agents learn to surpass today’s limitations 💖.
Get too excited by the demo, write a blogpost before the holidays with my great students @chenzhuoming911 @IronSteveZhou who built it:
infini-ai-lab.github.io/ai-environment…
Vortex code: github.com/Infini-AI-Lab/…
Vortex doc: infini-ai-lab.github.io/vortex_torch
#MLOps #AIAgents #SystemsEngineering #AIInfrastructure #OpenSourceAI #AIOps #AIFrameworks #SparseAttention #AIResearch
English
Binhang Yuan retweetledi

Sorry for a typo in my previous post. The correct arxiv paper link is: arxiv.org/pdf/2508.07976…
Yi Wu@jxwuyi
🔍We introduce ASearcher, a search agent trained by end2end RL Large-scale (up to 128 turns) RL with AReaL unlocks Long-Horizon Agentic Search (+20.8/+46.7% on GAIA/xBench) 💻Data, Code&Model: github.com/inclusionAI/AS… 📄Paper: arxiv.org/abs/2508.07976v #Agent #OpenSource #LLM #AGI
English
Binhang Yuan retweetledi
Tired intricate system code for RL training? 🤯
We release AReaL-lite – A lightweight AReaL version for AI researchers! 🚀#opensource
✨ Algorithm-first design & APIs🎉
✨ 80% less code w. 90% AReaL's full efficiency 🎉
✨ Customizable agentic RL🎉
🔗 github.com/inclusionAI/AR…

English
Binhang Yuan retweetledi
🥳
Infini-AI-Lab@InfiniAILab
Huge thanks to @tinytitans_icml for an amazing workshop — see you next year! Honored to receive a Best Paper Award 🏆 Let’s unlock the potential of sparsity! Next up: scaling to hundreds/thousands of rollouts? Or making powerful R1/K2-level LLMs (not just 8B 4-bit models) run on edge devices? Big kudos to @RJ_Sadhukhan, @chenzhuoming911, @haizhong_zheng, @IronSteveZhou, collaborator Emma Strubell, and our advisor @BeidiChen!
ART
Binhang Yuan retweetledi

🔥 We introduce Multiverse, a new generative modeling framework for adaptive and lossless parallel generation.
🚀 Multiverse is the first open-source non-AR model to achieve AIME24 and AIME25 scores of 54% and 46%
🌐 Website: multiverse4fm.github.io
🧵 1/n
GIF
English
Binhang Yuan retweetledi
We release fully async RL system AReaL-boba² for LLM & SOTA code RL w. Qwen3-14B! @Alibaba_Qwen #opensource
🚀system&algorithm co-design → 2.77x faster
✅ 69.1 on LiveCodeBench
🔥 multi-turn RL ready
🔗 Project: github.com/inclusionAI/AR…
📄 Paper: arxiv.org/pdf/2505.24298
1/3👇

English

Binhang Yuan retweetledi

Another angle: What I always encourage people is to believe there is no barrier on whatever you want to work on. Whatever training or inference, nothing is really hard if you spent time and focus. They are all paper tigers. The secret is to just ignore people who told you it’s too late/hard and only listen to people who’d like to help you achieve your goal.
Stas Bekman@StasBekman
Future ML specialization: Inference or Training? Very soon training LLMs will become a domain of a few companies and there will be very little need in experts in LLM training. Especially when LLMs will be at the level of CV cats-vs-dogs quality. Inference expertise on the other hand has a tiny barrier to entry, so it'll become commoditized in no time. It'd be very difficult to compete with others and differentiate one self doing inference work. I suppose finetuning/RAG is going to be somewhat needing experts for some years to come - until foundational models will have all that provided out of the box. And then what? Where do you feel one still could be an ML expert 5-10 years from now? I worked though the dot com bubble and this ML bubble feels too too similar. Hence the asking. Thank you for your insights.
English
Binhang Yuan retweetledi

We are recruiting! Applications including 1) a cover letter, 2) a full curriculum vitae, 3) names and contact information of at least three referees, 4) a research statement, and 5) a teaching statement should be submitted via facrecruit.hkust.edu.hk.

English
Binhang Yuan retweetledi

1/ 🌟 Excited to announce #Model-#GLUE (#neurips2024 D&B), a new framework designed by an extensive team from UNC, UMD, UT Austin, HKUST, Google, and CMU to #scale pre-trained LLMs efficiently!
🚀 Tackling the challenge of #aggregating disparate pre-trained LLM, we introduce a holistic guideline and benchmarking if you have a large, diverse model zoo "in the wild"! #LLM #AIresearch
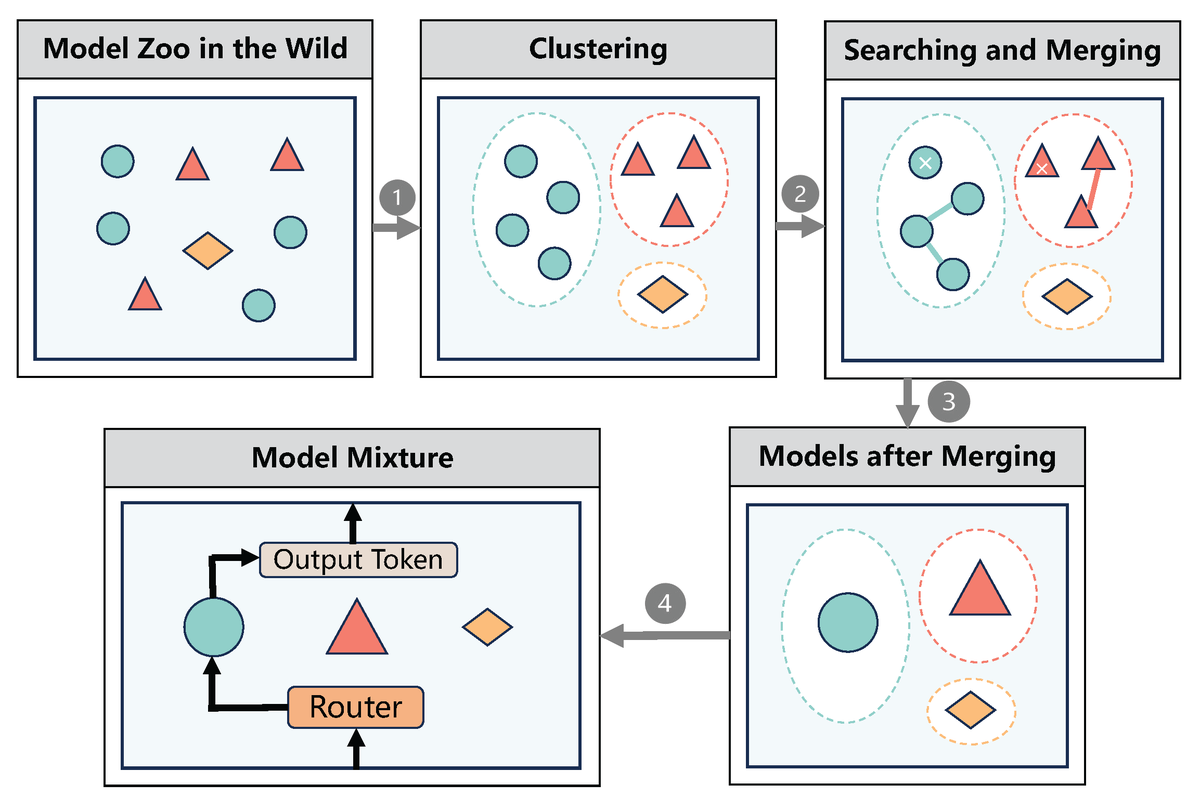
English
Binhang Yuan retweetledi

🚀 Big news! We’re thrilled to announce the launch of Llama 3.2 Vision Models & Llama Stack on Together AI.
🎉 Free access to Llama 3.2 Vision Model for developers to build and innovate with open source AI. api.together.ai/playground/cha…
➡️ Learn more in the blog together.ai/blog/llama-3-2…

English
Binhang Yuan retweetledi
🚀 NVIDIA H200 and the Together Kernel Collection (TKC) are coming to Together GPU Clusters: delivering accelerated performance, efficiency, and scalability for AI training, fine-tuning, and inference workloads. ⚡
🔗 Read the blog post together.ai/blog/nvidia-h2…
GIF
English
Binhang Yuan retweetledi

#MLSys2025 call for papers is out! The conference will be led by the general chair @matei_zaharia , PC chairs @CelineLinatGT, and Gauri Joshi. Consider submitting and bringing your latest works in AI and systems—more details at mlsys.org.

English
Binhang Yuan retweetledi

Binhang Yuan retweetledi
Today we are thrilled to share that we’ve raised $106M in a new round led by @SalesforceVC with participation from @coatuemgmt and our existing investors.
Our vision is to rapidly bring innovations from research to production and to ultimately build the best platform we can for developers, startups, and enterprises to run generative AI applications built on open-source models at production scale.
together.ai/blog/series-a2

English
Binhang Yuan retweetledi
📢 Announcing our new speculative decoding framework Sequoia ❗️❗️❗️
It can now serve Llama2-70B on one RTX4090 with half-second/token latency (exact❗️no approximation)
🤔Sounds slow as a sloth 🦥🦥🦥???
Fun fact😛:
DeepSpeed -> 5.3s / token;
8 x A100: 25ms / token (costs 8 x $18,000 = $140,000+ but an RTX4090 is $1000+😉)
You can serve with your 2080Ti too! Curious how? Check it out 👇
Website: infini-ai-lab.github.io/Sequoia-Page
Paper: arxiv.org/abs/2402.12374
Code: github.com/Infini-AI-Lab/…
GIF
English
Binhang Yuan retweetledi

We are excited to announce this year’s keynote speakers for #MLSys2024: Jeff Dean @JeffDean, Zico Kolter @zicokolter, and Yejin Choi @YejinChoinka! MLSys this year will be held in Santa Clara on May 13–16. More details at mlsys.org.
English