Zhiyang (Frank) Dou@frankzydou
Excited to share our latest work on 🎧spatial audio-driven human motion generation.
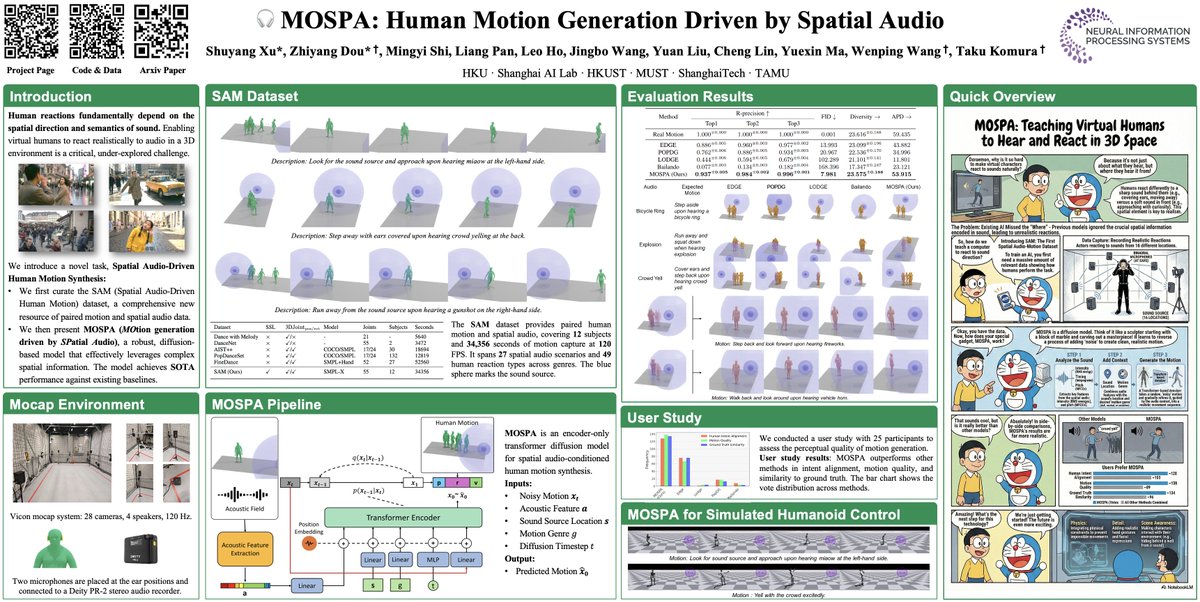
We aim to tackle a largely underexplored yet important problem of enabling virtual humans to move naturally in response to spatial audio—capturing not just what is heard, but also where the sound is coming from.
To this end, we introduce the Spatial Audio-Driven Human Motion (SAM) dataset—the first comprehensive dataset featuring paired high-quality human motion and spatial audio recordings.
For benchmarking, we develop a generative framework for human MOtion generation driven by SPAtial audio, termed MOSPA, which learns to synthesize realistic and diverse human motions conditioned on spatial audio input. We hope this research could provide a foundation for future research in spatial perception, virtual characters, and embodied AI.
The dataset and model will be open-sourced soon.
A big thank you to our intern, Shuyang Xu, for the wonderful collaboration! Congratulations, Shuyang!
Project page: frank-zy-dou.github.io/projects/MOSPA…
Paper: arxiv.org/abs/2507.11949
Video: youtu.be/p_xwTDA-K0g
#Animation #CG #CV #AIGC #DL #Deeplearning #Motion #Graphics #AI #GenerativeAI