
Sabitlenmiş Tweet

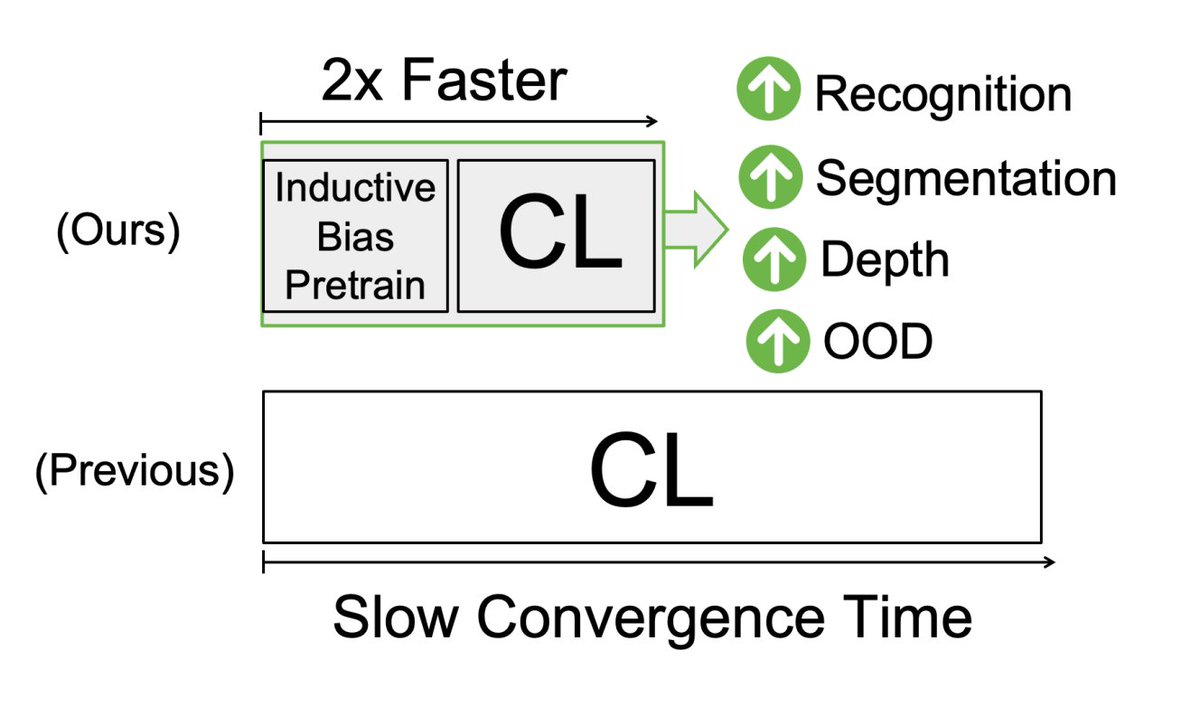
Thrilled to share our new CVPR 2025 paper “Perceptual Inductive Bias Is What You Need Before Contrastive Learning”! Inspired by David Marr's theory, we show that injecting object shape & surface cues before self-supervised pre-training leads to:
• 2× faster convergence in total pre-training time (Big Save on $$ ! )
• +2 mIoU on ADE20K & Cityscapes
• Stronger depth & OOD robustness
• Human‐level shape bias across 17 benchmarks
📖 Read our paper on arXiv:
arxiv.org/abs/2506.01201…
#ComputerVision #SelfSupervisedLearning #CVPR2025 #ShapeBias
English



























