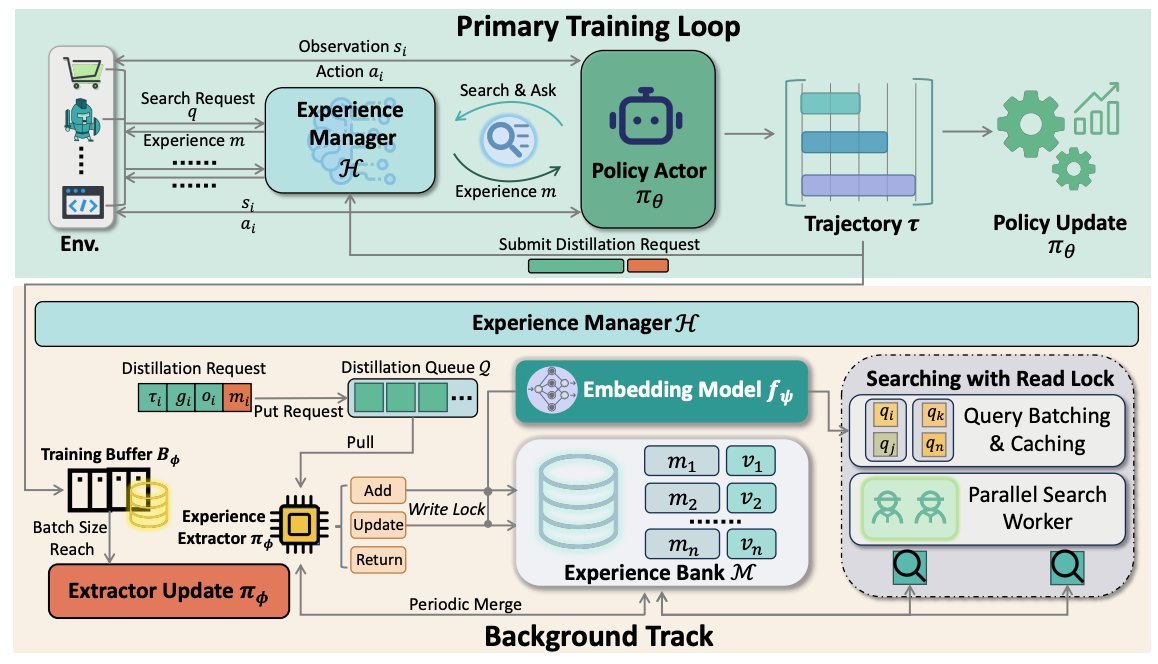
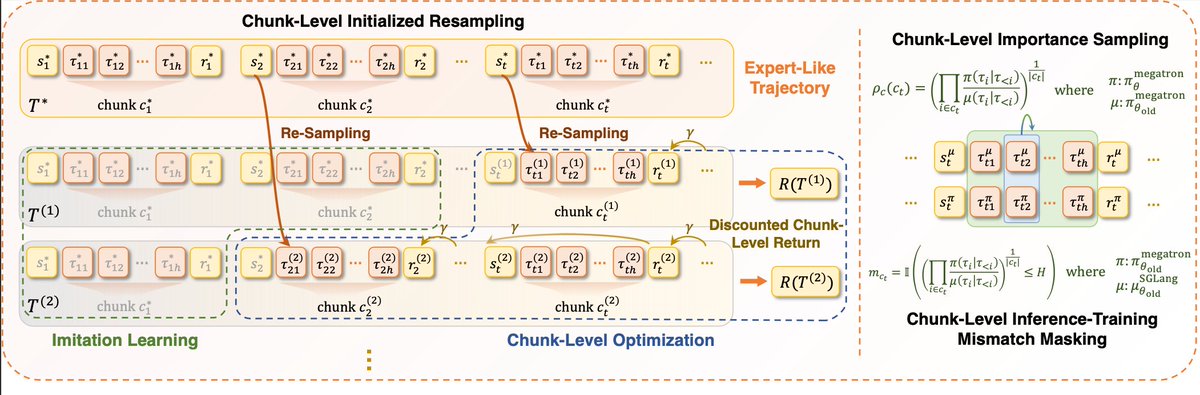
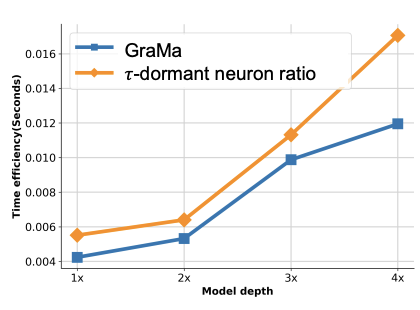
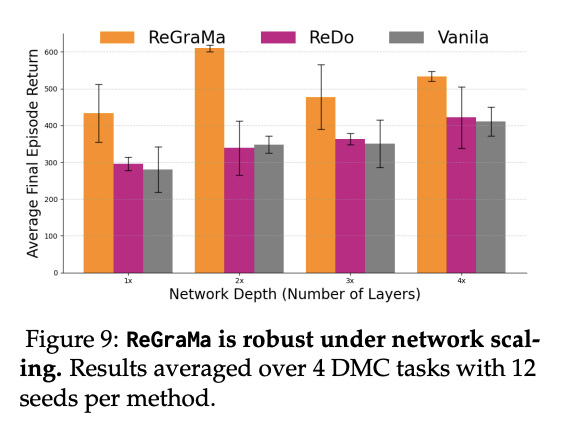
Sabitlenmiş Tweet

Excited to share our #RL_for_LLM paper: "Part I: Tricks or Traps? A Deep Dive into RL for LLM Reasoning"
We conducted a comprehensive analysis of RL techniques in LLM domain!🥳
Surprisingly, we found that using only 2 techniques can unlock the learning capability of LLMs.😮

English