Sabitlenmiş Tweet
Mesh
3.9K posts


Mesh
@Meshrhm
Husband | Entrepreneur & Investor | Bitcoin since 2016 | AGI & Contrarian Political Insights | 🇨🇦/acc | Civil Engineering | Currently tinkering in my home lab
Katılım Temmuz 2014
676 Takip Edilen1.8K Takipçiler

@globeandmail Yes, it’s not a political statement, it’s a way to show that you stand with all that has earned us our freedom. 🇨🇦
English

Should poppies be allowed in Canadian courts? theglobeandmail.com/canada/article…
English
@dian_arifiya Picking a lock is quite easy, I’d imagine it’s the first thing car thieves learn
English

@timeswmariana Ah is this the kink where people want to bang senior citizens?
English
@opengreenseas @Emilio2763 You have an insane misconception of overhead. If they have 7.8 mil remaining after lease and staff salaries, they are at a gross deficit.
English

I did a bit of research and I disagree . VEGAS is NOT finished and Bellagio is doing just fine 😎
From my research the following is approximate:
Bellagio ‘s monthly lease is $20.42 million
Bellagio’s monthly earnings is $38.1 million
Bellagio’s monthly cumulative staff payroll is about $10 million
They have a monthly surplus of about $7,680,000
😎
I ♥️@Bellagio
English


Im not going crazy right
Brady Penfield🇻🇦@brady_penfield
My name is Brady Penfield, I am 22 years old and a lifelong Wisconsinite. I come from a family of Dane County Democrats. However, I became a conservative during my junior year of high school in 2020 in the peak of the COVID lockdowns I recently graduated from the University of Wisconsin River Falls. Where I founded and led the UWRF College Republicans Chapter for two years. Last summer in 2024, I ran for state assembly while still in college and lost in the primary election by just .8% or 45 votes. Last month, I launched a Young Republican Chapter for St. Croix and Pierce Counties where I live. Now, I’ve been working with @tpaction for 10 months as the Badger Field Rep. I’ve been building permanent GOTV infrastructure across 39 counties in Western and Northern Wisconsin. I get things done, I don’t sit around and complain on social media, so it’s time for you all to do the same if you want to save this nation!
English

You know what really bothers me? And I don’t know if it was intentional or not.
But it bothers me a lot.

English
@Biotech2k1 What timeframe are you looking at for $SPRB and does their governance structure (lack of) concern you?
English

My open post. I haven't done one of these in a long time as you get 100 spam replies as soon as you do. I only let people I follow reply to post to avoid the bots and spam. If you want me to follow you so you can reply to my posts, just comment here and I will follow you.
English

the creator who's banking $47K monthly from TikTok asked me not to share this automation...
these brain-rot style videos are pulling 10M+ views consistently on TikTok and YouTube Shorts
faceless channels are banking $15K-$50K monthly from this exact format
here's what my n8n workflow does automatically:
- generates viral Peter Griffin & Stewie conversations
- clones their actual voices using AI
- overlays them on Minecraft parkour gameplay
- adds perfectly timed subtitles
- renders complete videos ready to upload
these videos exploit dopamine triggers
the background gameplay keeps viewers glued while the AI-generated dialogue delivers the actual content
it's psychological manipulation at its finest
I spent 40+ hours perfecting this:
- gathering rare audio samples for voice cloning
- training custom AI voice models for both characters
- building the complete automation workflow
- testing render quality and timing
the results speak for themselves
channels using this format are going from 0 to 100K followers in weeks
some are hitting 50M+ monthly views with zero effort after setup
the workflow handles everything:
-content ideation
-script generation
-voice synthesis
- video composition
- final rendering
you literally press one button and get viral-ready content
while everyone's still manually editing videos, smart creators are scaling with automation like this
the opportunity window is MASSIVE right now
these formats are exploding across all platforms
Comment "VIDEO" + repost this + follow me (MUST DO ALL) and I'll send you the complete JSON file plus setup guide
a lot of people will ingore this and last yet another occasion to finally make it
don't sleep on it.

English



Three weeks ago we launched Manus in closed beta and we've been humbled by the love for Manus. Today, we want to share some updates about our beta testing with the Manus community.
1. Manus mobile app: manus.onelink.me/2Tdk/g6ttrj4c
2. Longer context and better multimodal capabilities
3. Manus will be powered by Claude 3.7 for all tasks (no fallback to 3.5 - big thanks to @AnthropicAI @googlecloud @awscloud)
4. A more stable sandbox (big thanks to @e2b)
5. Premium subscription plan beta test while maintaining limited free access
While we're working hard around the clock to scale our infrastructure and accommodate everyone, we've had to temporarily limit access to Manus during our this development phase. We are also working on optimizing our current usage rates to provide better value for our users.
We're incredibly grateful for your patience and continuous feedback during this beta phase which allows us to continue building a better Manus for everyone.❤️
English
Makes a lot of sense why @sama is working on blocking Chinese models in the US
Baidu Inc.@Baidu_Inc
We've just unveiled ERNIE 4.5 & X1! 🚀 As a deep-thinking reasoning model with multimodal capabilities, ERNIE X1 delivers performance on par with DeepSeek R1 at only half the price. Meanwhile, ERNIE 4.5 is our latest foundation model and new-generation native multimodal model. Plus, our AI chatbot ERNIE Bot has now been made free to individual users ahead of schedule. Both models are now freely accessible to all ERNIE Bot users via its official website: yiyan.baidu.com.
English
A 32B model supposedly on par with a 671B model? Impressive!
Qwen@Alibaba_Qwen
Today, we release QwQ-32B, our new reasoning model with only 32 billion parameters that rivals cutting-edge reasoning model, e.g., DeepSeek-R1. Blog: qwenlm.github.io/blog/qwq-32b HF: huggingface.co/Qwen/QwQ-32B ModelScope: modelscope.cn/models/Qwen/Qw… Demo: huggingface.co/spaces/Qwen/Qw… Qwen Chat: chat.qwen.ai This time, we investigate recipes for scaling RL and have achieved some impressive results based on our Qwen2.5-32B. We find that RL training con continuously improve the performance especially in math and coding, and we observe that the continous scaling of RL can help a medium-size model achieve competitieve performance against gigantic MoE model. Feel free to chat with our new models and provide us feedback!
English
Mistral Small 3 is on par with Llama 3.3 70B Instruct, while being 3x faster on the same hardware (24B!). We’re experiencing something amazing, smaller models that have the same capabilities as larger models are coming.
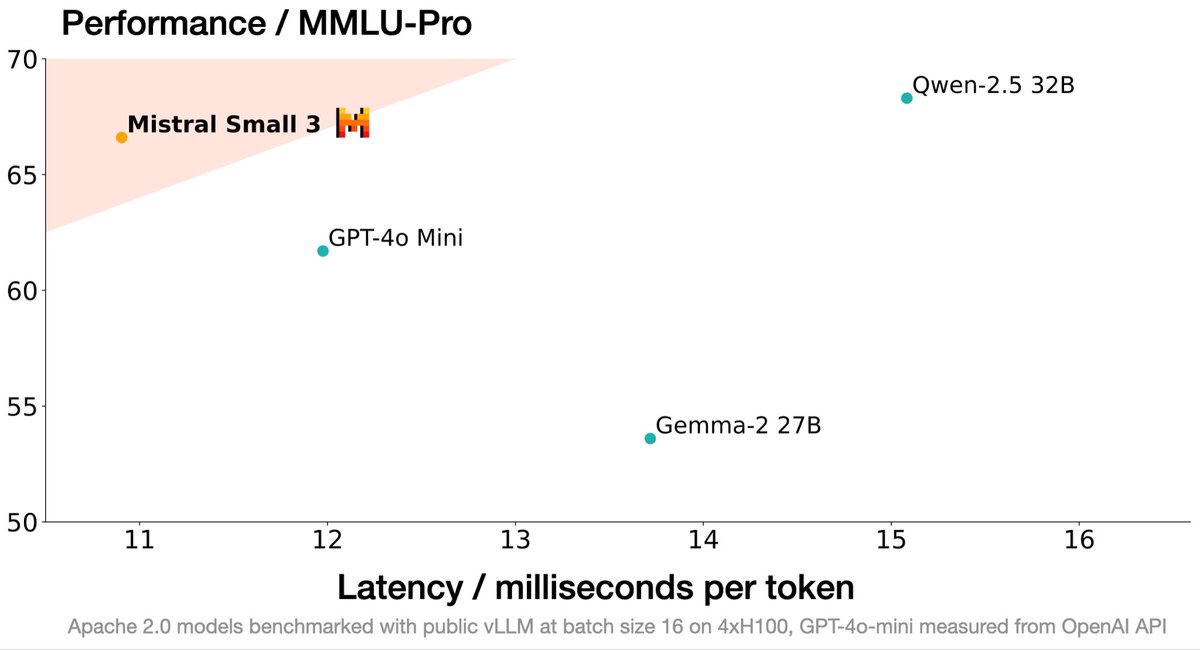
Mistral AI@MistralAI
Introducing Small 3, our most efficient and versatile model yet! Pre-trained and instructed version, Apache 2.0, 24B, 81% MMLU, 150 tok/s. No synthetic data so great base for anything reasoning - happy building! mistral.ai/news/mistral-s…
English

BREAKING: Donald Trump has ordered a communications blackout at America's federal health agencies, per WaPo.
The CDC, FDA, HHS and NIH have all been told to pause external communications, including publishing scientific reports, updating websites or issuing health advisories.
English


Announcing The Stargate Project
The Stargate Project is a new company which intends to invest $500 billion over the next four years building new AI infrastructure for OpenAI in the United States. We will begin deploying $100 billion immediately. This infrastructure will secure American leadership in AI, create hundreds of thousands of American jobs, and generate massive economic benefit for the entire world. This project will not only support the re-industrialization of the United States but also provide a strategic capability to protect the national security of America and its allies.
The initial equity funders in Stargate are SoftBank, OpenAI, Oracle, and MGX. SoftBank and OpenAI are the lead partners for Stargate, with SoftBank having financial responsibility and OpenAI having operational responsibility. Masayoshi Son will be the chairman.
Arm, Microsoft, NVIDIA, Oracle, and OpenAI are the key initial technology partners. The buildout is currently underway, starting in Texas, and we are evaluating potential sites across the country for more campuses as we finalize definitive agreements.
As part of Stargate, Oracle, NVIDIA, and OpenAI will closely collaborate to build and operate this computing system. This builds on a deep collaboration between OpenAI and NVIDIA going back to 2016 and a newer partnership between OpenAI and Oracle.
This also builds on the existing OpenAI partnership with Microsoft. OpenAI will continue to increase its consumption of Azure as OpenAI continues its work with Microsoft with this additional compute to train leading models and deliver great products and services.
All of us look forward to continuing to build and develop AI—and in particular AGI—for the benefit of all of humanity. We believe that this new step is critical on the path, and will enable creative people to figure out how to use AI to elevate humanity.
English

