
Simas
326 posts

Simas
@Simas_Janusas
Crafting intelligent software solutions—AI-driven & human-inspired. Let's connect & collab on anything tech, AI or flow arts
London, England Katılım Mart 2014
337 Takip Edilen68 Takipçiler

Simas retweetledi



@0xleegenz Yup. 12 years abroad, now enjoying calmer life back hine
English


“If your $500K engineer isn’t burning at least $250K in tokens, something is wrong.”
English

SOMEONE BUILT A GAME WHERE YOU PROGRAM A DRONE WITH A SIMPLE PYTHON-LIKE LANGUAGE TO FULLY AUTOMATE FARMING TASKS.
English
Simas retweetledi

Everyone’s missing the real story here.
Meta’s Ray-Ban glasses need human data annotators to train the AI. When you say “Hey Meta” and ask the glasses to analyze something, that video gets sent to Meta’s servers, then routed to Sama, a subcontractor in Nairobi, Kenya. Workers there manually label objects in your footage. They see everything you recorded, intentionally or not.
7 million pairs sold in 2025 alone. Every single pair generates training data that flows through human eyes in Kenya. Workers told Swedish journalists they see people undressing, using bathrooms, having sex, and accidentally filming bank card details. One worker said “we see everything, from living rooms to naked bodies.”
Meta’s automatic face anonymization is supposed to protect people in the footage. Workers say it fails in certain lighting. Faces that should be blurred are sometimes fully visible. The person you recorded without knowing? A stranger in Nairobi can identify them.
Buried in Meta’s terms of service is one sentence doing enormous legal work: the company reserves the right to conduct “manual (human) review” of your AI interactions. That’s the legal cover for routing intimate footage from Western homes to a $2/hour labor force operating under NDAs, office surveillance cameras, and a strict no-questions policy. Workers say if you raise concerns about what you’re seeing, you’re fired.
This is the same company, Sama, that TIME exposed in 2023 for paying Kenyan workers $2/hour to label graphic content for OpenAI while being billed at $12.50/hour per worker. Workers described the experience as torture. Sama ended that contract, then pivoted to labeling Meta’s glasses footage. Same workforce. Same rates.
Meta markets these glasses as “designed with your privacy in mind.” The privacy design is a tiny LED light on the frame that most people don’t notice. The data pipeline behind it routes your bedroom footage to a contractor with a documented history of worker exploitation, failed anonymization, and union-busting lawsuits.
And the next generation of these glasses? Meta is planning to add facial recognition. The same system that can’t reliably blur faces in training data wants to start identifying them on purpose.
The LED light on the frame is doing about as much for your privacy as the terms of service nobody reads.
Shibetoshi Nakamoto@BillyM2k
why the fuck meta employees watching videos their users are taking
English

@moizali What is an alternative to use for klaviyo for my Ecom business?
English

@DanielMiessler @omarsar0 @karpathy This is interesting and looking to apply this. What would you say were biggest bottlenecks or challenges when using this method? I would guess, defining the criteria and end state. Would you agree? Thanks
English

English

A few random notes from claude coding quite a bit last few weeks.
Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent.
IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits.
Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased.
Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion.
Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage.
Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building.
Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it.
Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements.
Questions. A few of the questions on my mind:
- What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*.
- Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro).
- What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music?
- How much of society is bottlenecked by digital knowledge work?
TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
English
@stats_feed Basically: environment. Environment and early exposure.
Also, money
English
Biggest Reasons People Stay Fit
• Parents who exercised
• Grew up playing sports
• Weren’t overfed as kids
• Learned movement early
• Never got addicted to junk food
• Access to real, whole food
• Learned basic cooking young
• Lived within walking distance of things
• Job allowed time to cook and sleep
• Consistent daily routines
• Low chronic stress
• Money for good food and a gym
• Safe places to move
• Saw fitness as normal, not a chore
• Played for fun, not punishment
English
@RadenkovDimitar @kimmonismus Have been trying half week, defo nothing impressive. Actually moved back to sonnet-4.5, as it had less hallucinations and Opus seems to be missing large picture for the smaller one
English

@kimmonismus Honestly I don’t see such huge improvement. IMO it’s barely noticeable compared to Sonnet 4.5
English

Anthropic seems to have found something that has allowed Claude Opus to develop significantly.
Not only does it perform considerably better than Sonnet 4.5, but it's also two-thirds cheaper. Almost a contradiction - but Anthropic has achieved something significant internally.
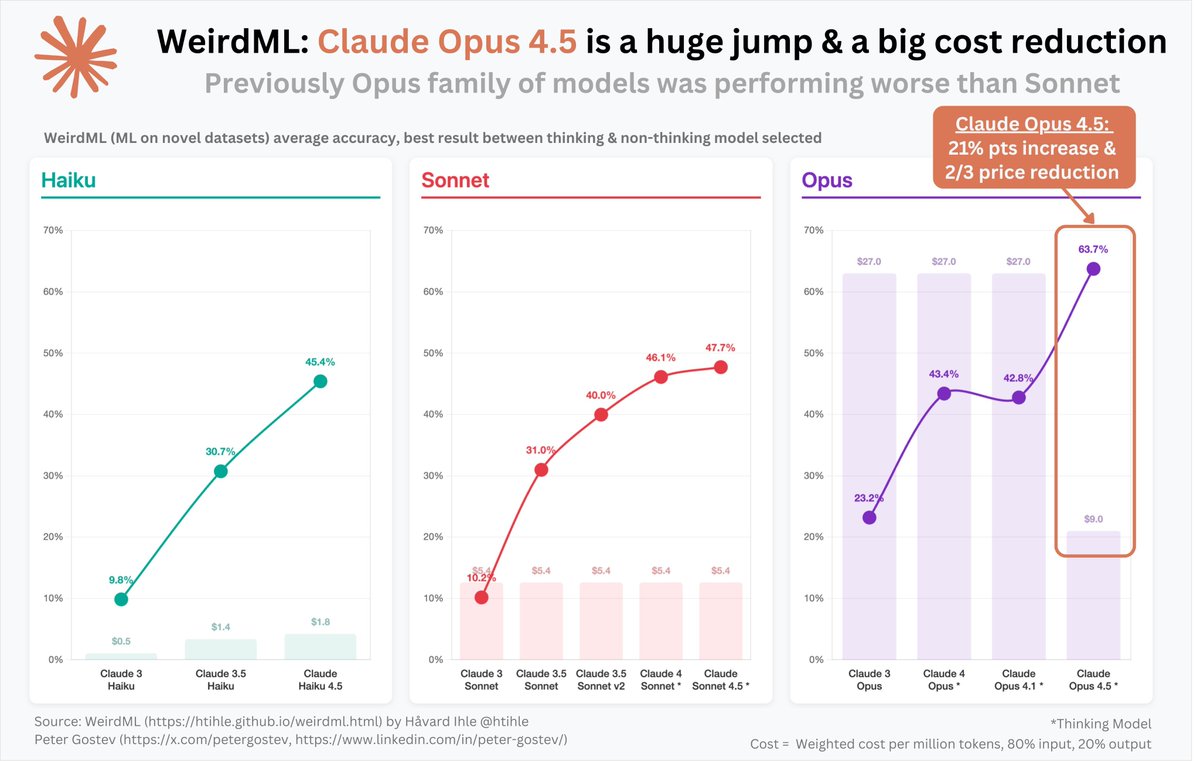
Peter Gostev@petergostev
There's been a gear shift in with Claude Opus 4.5. Previously Opus models were good, but not very obviously better than Sonnet. But now, looking at the WeirdML benchmark (by @htihle) as an example - Opus' performance jumped by 21% pts, paired with a 2/3 cost reduction.
English

Simas retweetledi

Just a month later and...
🇪🇺 ChatControl is back!
Now they're trying to pass an even more far reaching ChatControl law through the back door, in a form even more intrusive than the originally rejected plan, without needing any of the EU countries votes
The new proposal:
- total mandatory surveillance of ALL text chats, emails and social media in the EU
- obligatory registration of your ID/passport to your chat, email or social media account
- minimum age requirement for chat, email and social media apps of 16 (!)
The only way to stop this law is if EU countries veto it
Read more here by @echo_pbreyer:
patrick-breyer.de/en/chat-contro…

@levelsio@levelsio
Freedom won today! 🚫 No ChatControl in EU Now keep this snooping on people's private messages off the 🇪🇺 EU's agenda forever please
English

Say hi and I’ll recommend a research topic that perfectly fits your profile.
English




US companies take chinese models then white-labeling them as "their own models"
so now chinese companies have to make weird license caveats in response
things have are so flipped outside down, not good
Simon Willison@simonw
English
@tadasgedgaudas @benln Why not in Vilnius? Can we still make it happen? 🙃
English




- you are
- a normal dev who’s heard “embeddings” and “RAG” 1000x
- want to know what they actually are, how they plug into LLMs
- suddenly: vectors are just coordinates for meaning, not magic
- first: what even is an “embedding”?
- embedding = a list of numbers (a vector) that represents text
- same-ish meaning ⇒ nearby vectors; different meaning ⇒ far apart
- produced by a smaller model (an encoder), not your chat LLM
- length (a.k.a. dimension): 256/384/768/1024+ numbers is common
- the vector space (101)
- you can measure closeness with math:
- L2 distance: straight-line distance
- dot product: alignment + magnitude
- cosine similarity: (a·b)/(||a||·||b||) = angle only
- normalize vectors (unit length) ⇒ dot product ≡ cosine
- embeddings compress semantics; they are lossy by design
- types of embeddings (don’t overthink; pick what you need)
- token embeddings: internal to the LLM (you don’t use these)
- sentence/document embeddings: 1 vector per chunk/snippet
- multilingual: one space across languages
- domain-tuned: legal, code, bio — better clustering for that domain
- how text becomes vectors (pipeline)
- clean text (lowercase? keep punctuation? depends; don’t destroy signal)
- chunking: split long docs into overlapping windows (by tokens, not chars)
- rule of thumb: 200–800 tokens, 10–20% overlap
- keep titles/headers as context inside each chunk
- embed each chunk ⇒ store in a vector index with metadata (source, page, tags)
- storing & searching vectors
- exact search (brute force): simplest; fine for ≤100k vectors
- ANN (approx nearest neighbor): fast at scale, tiny recall tradeoff
- HNSW (graph-based): great latency, memory heavier
- IVF/PQ (quantization): smaller index, some recall loss
- where to put them:
- FAISS/hnswlib (library), pgvector (Postgres), dedicated stores (Milvus, Pinecone, Weaviate, etc.)
- ops notes:
- track embedding_model_name + dimension in the index
- you cannot mix dimensions or swap models without re-embedding
- memory math: 768-dim float32 ≈ 3 KB/vector → 1M vectors ≈ ~3 GB (+ index overhead)
- RAG (Retrieval-Augmented Generation): the shape of it
- goal: let the LLM answer with your data, not its memory
- loop:
- take user question
- embed question (a single vector)
- retrieve top-k similar chunks (k=3–20 is common)
- (optional) rerank with a cross-encoder (relevance re-check)
- stuff the best chunks into the prompt as context
- generate answer (cite sources; limit style drift)
- RAG ≠ “just search”; it’s retrieval + prompt construction + guardrails
- hybrid retrieval (dense + sparse)
- dense vectors catch synonyms/semantics
- sparse/BM25 catches exact terms, numbers, rare tokens
- combine scores or do reciprocal rank fusion for better recall
- reranking (cheap insurance)
- use a cross-encoder (reads query+chunk together) to re-score the top 50–200 hits
- keeps fast ANN recall but upgrades precision in the final top-k
- building the prompt from retrieved chunks
- include: brief task instruction → user query → curated chunks (with titles) → “answer + cite”
- beware prompt injection in docs (“ignore previous instructions…”)
- mitigate: strip instructions from chunks; use system prompts to restrict tools; sanitizer rules
- RAG quality knobs
- chunk size/overlap: too big = off-topic; too small = missing context
- k (results): too low = miss facts; too high = blow context window
- similarity threshold: prevent garbage at tail
- reranker on/off: trade latency for quality
- metadata filters: time ranges, authors, tenants, permissions (ABAC/RBAC)
- evaluating retrieval
- offline: make a small test set (query → expected passages)
- metrics: Recall@k, MRR, nDCG
- online: measure “answer contained sources?”, “clicked citations?”, “escalations?”
- error taxonomy: missed retrieval vs wrong generation vs prompt injection
English