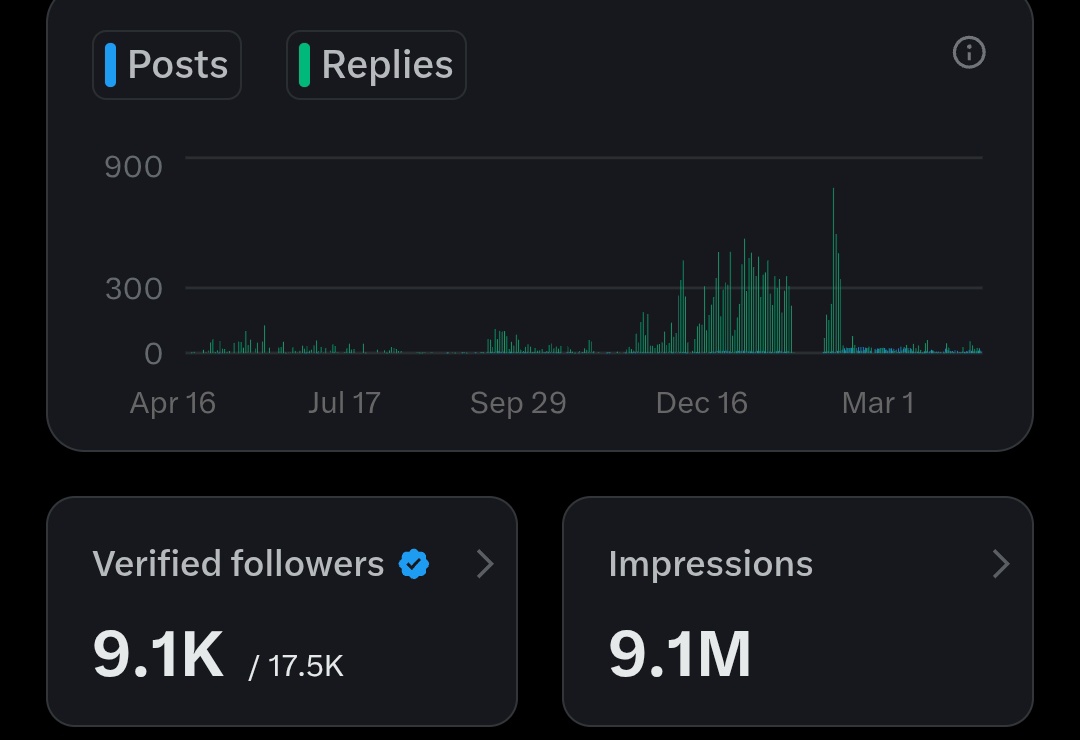
Sabitlenmiş Tweet

I run 5 social media accounts. I post every single day. I spend less than 30 minutes on content.
Here's the AI automation system I built to do it:
English
thedangerousAIsoure
108 posts

@ThedangerousAI
⚠️ We track the rise of artificial intelligence — and its dangers. 🧠 The source for everything they won’t tell you. #TheDangerousAISource