
VidyaData
76 posts

VidyaData
@VidyaData
Data enthusiast? Follow us to accelerate your Data Science journey. VidyaData is your go to guide for resources on #ML, #AI & the vast #DataScience landscape.
Katılım Ağustos 2023
138 Takip Edilen19 Takipçiler




@shakeeelll @sickaqua When they killed homelander, they killed his dream. And coudlnt live with knowing his dream ll nvr be reality
English



Coming soon: How to build Claude Code from scratch 😄
Andrej Karpathy@karpathy
Personal update: I've joined Anthropic. I think the next few years at the frontier of LLMs will be especially formative. I am very excited to join the team here and get back to R&D. I remain deeply passionate about education and plan to resume my work on it in time.
English
@peamceout Co he has scored a boundary and won us a match in similar fashion in Eng😄
English

@hwchase17 @Hacubu Research agent using structures data as well unstructured data
English

I’m going to build a bunch of deepagents examples (using deepagent deploy) over the next few days
What examples would people want to see?
English
@toisports Clickbait! Some pakistani guys commented it. Dont read the article
English
VidyaData retweetledi

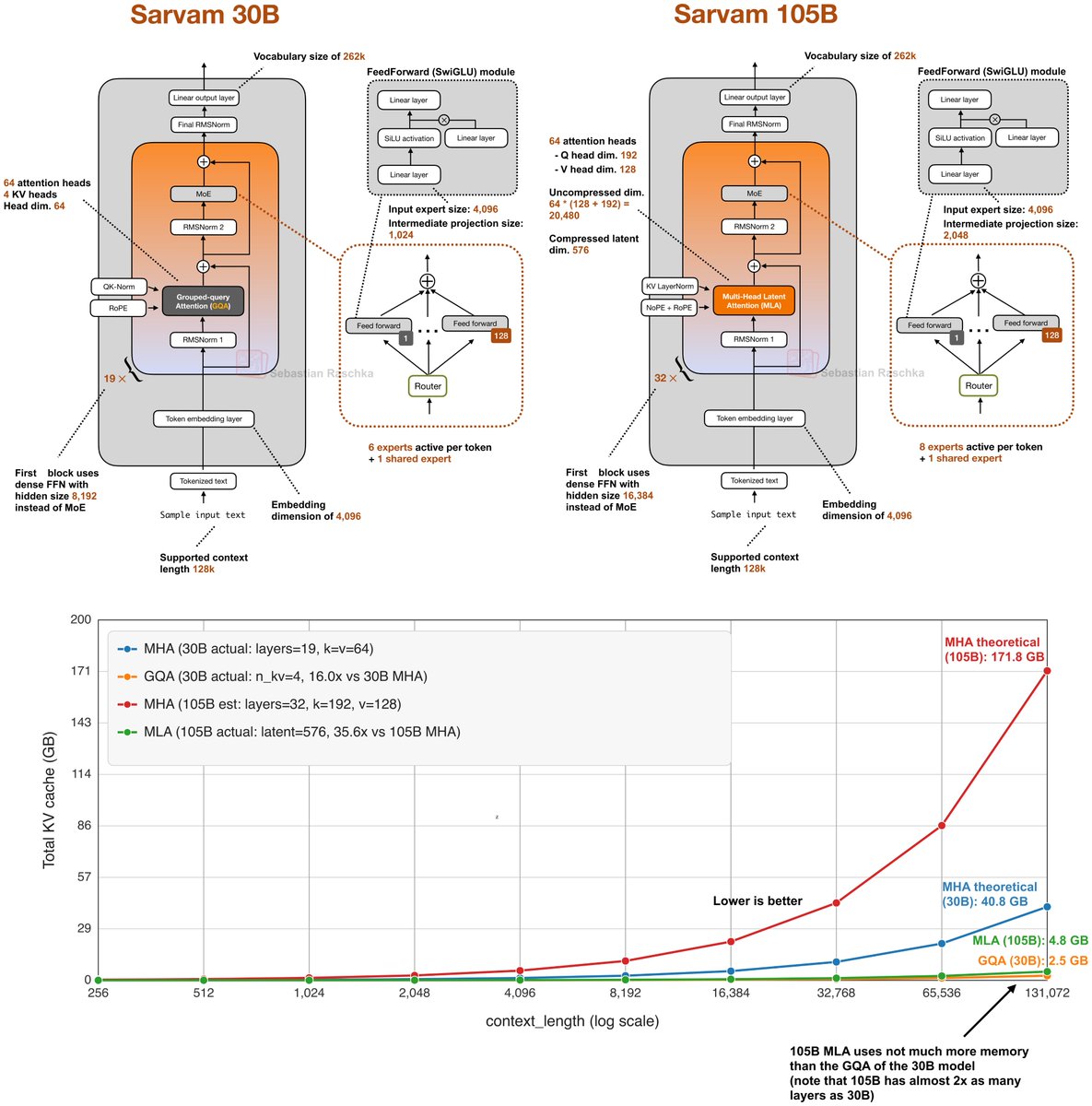
While waiting for DeepSeek V4 we got two very strong open-weight LLMs from India yesterday.
There are two size flavors, Sarvam 30B and Sarvam 105B model (both reasoning models).
Interestingly, the smaller 30B model uses “classic” Grouped Query Attention (GQA), whereas the larger 105B variant switched to DeepSeek-style Multi-Head Latent Attention (MLA).
As I wrote about in my analyses before, both are popular attention variants to reduce KV cache size (the longer the context, the more you save compared to regular attention).
MLA is more complicated to implement, but it can give you better modeling performance if we go by the ablation studies in the 2024 DeepSeek V2 paper (as far as I know, this is still the most recent apples-to-apples comparison).
Speaking of modeling performance, the 105B model is on par with LLMs of similar size: gpt-oss 120B and Qwen3-Next (80B). Sarvam is better on some tasks and worse on others, but roughly the same on average.
It’s not the strongest coder in SWE-Bench Verified terms, but it is surprisingly good at agentic reasoning and task completion (Tau2). It’s even better than Deepseek R1 0528.
Considering the smaller Sarvam 30B, the perhaps most comparable model to the 30B model is Nemotron 3 Nano 30B, which is slightly ahead in coding per SWE-Bench Verified and agentic reasoning (Tau2) but slightly worse in some other aspects (Live Code Bench v6, BrowseComp).
Unfortunately, Qwen3-30B-A3B is missing in the benchmarks, which is, as far as I know, is the most popular model of that size class. Interestingly, though, the Sarvam team compared their 30B model to Qwen3-30B-A3B on a computational performance analysis, where they found that Sarvam gets 20-40% more tokens/sec throughput compared to Qwen3 due to code and kernel optimizations.
Anyways, one thing that is not captured by the benchmarks above is Sarvam’s good performance on Indian languages. According to a judge model, the Sarvam team found that their model is preferred 90% of the time compared to others when it comes to Indian texts. (Since they built and trained the tokenizer from scratch as well, Sarvam also comes with a 4 times higher token efficiency on Indian languages.
Pratyush Kumar@pratykumar
📢 Open-sourcing the Sarvam 30B and 105B models! Trained from scratch with all data, model research and inference optimisation done in-house, these models punch above their weight in most global benchmarks plus excel in Indian languages. Get the weights at Hugging Face and AIKosh. Thanks to the good folks at SGLang for day 0 support, vLLM support coming soon. Links, benchmark scores, examples, and more in our blog - sarvam.ai/blogs/sarvam-3…
English
VidyaData retweetledi

TOMORROW the Road to #NODESAI begins!
bit.ly/4rQjSGH
Register! 2-hour workshop about #GenerativeAI, Retrieval-Augmented Generation (RAG), and #GraphRAG
See you!

English
VidyaData retweetledi

LangChain Community Spotlight: sklearn-diagnose 🔍🤖
Python library that diagnoses ML model failures via LLM analysis. Uses three LangChain agents to detect failure modes and generate fixes. New chatbot enables conversational exploration of diagnosis results.
Explore the project: github.com/leockl/sklearn…

English
VidyaData retweetledi

Today, we’re releasing a significant upgrade to our specialized reasoning mode, Gemini 3 Deep Think.
Deep Think is built to drive practical applications, enabling researchers to interpret complex data and engineers to model physical systems through code.
With the updated Deep Think, you can turn a sketch into a 3D-printable reality. Deep Think analyzes the drawing, builds the complex shape, and generates a file so you can create the physical object with 3D printing.
This is rolling out now to Google AI Ultra subscribers. Select the "Deep Think" option in the tools menu to get started.
Learn more here: goo.gle/3MoiifF
English
VidyaData retweetledi

I (Rasmita Sahoo) am a distressed mother seeking urgent help. My son Cadet Sarthak Mohapatra has gone missing while on board vessel M.V. EA Jersey on 3rd Feb 2026 during sailing. @CMO_Odisha @PMOIndia @dgshipping_IN @angloeasterngrp @MEAIndia @DrSJaishankar @IndianDiplomacy



English
VidyaData retweetledi

🇮🇳 Good morning India! A lot of you asked for full-length mock JEE Main tests in @GeminiApp at no cost - done! Good luck on your prep!
Last week, SAT. This week, JEE.
What other global exams would be most helpful?
English

@ArmanHezarkhani Using karpathy’s picture for your own benefit is engagement bait
English

If you get through all of this material, you'll be an ML Engineer (MLE)
I'm thinking of leading a study group through this content
If you're interested in joining, comment "MLE" below
Arman Hezarkhani@ArmanHezarkhani
English
VidyaData retweetledi

The #NobelPeacePrize medal.
It measures 6.6 cm in diameter, weighs 196 grams and is struck in gold. On its face, a portrait of Alfred Nobel and on its reverse, three naked men holding around each other’s shoulders as a sign of brotherhood. A design unchanged for 120 years.
Did you know that some Nobel Peace Prize medals have been passed on after the award was given? A well‑known case is Dmitry Muratov’s medal, which was auctioned for over USD 100 million to support refugees from the war in Ukraine.
And the medal displayed at the Nobel Peace Center is actually on loan and originally belonged to Christian Lous Lange, Norway’s first Peace Prize laureate.
But one truth remains. As the Norwegian Nobel Committee states: “Once a Nobel Prize is announced, it cannot be revoked, shared, or transferred to others. The decision is final and stands for all time.”
A medal can change owners, but the title of a Nobel Peace Prize laureate cannot.

English
VidyaData retweetledi

Can somebody explain what Mira Murati is good at?
I'm not trying to be mean, I'm asking genuinely.
Like what is her main expertise or skill?
Her time at OpenAI seemed less than stellar, she appeared not fully prepared for several high-profile media interviews (including the famous Sora one)
She leaves to found Thinking Machines and raises huge sums of money (billions) based on........ what, exactly?
It was widely reported that they provided no clear product plan and only vague financials.
Have not shipped anything of substance (only aware of a very lightweight API tool Tinker)
And now everyone is leaving, she can't keep people and it appears to be a sinking ship
So I'm genuinely asking, what were investors betting billions of dollars on here? What was the selling point?
English
VidyaData retweetledi

Excited to welcome Barret Zoph, Luke Metz, and Sam Schoenholz back to OpenAI! This has been in the works for several weeks, and we’re thrilled to have them join the team. Barret will report to me; Luke and Sam will report into Barret. More to come on what they’ll focus on soon!
English
VidyaData retweetledi

We have parted ways with Barret Zoph.
Soumith Chintala will be the new CTO of Thinking Machines. He is a brilliant and seasoned leader who has made important contributions to the AI field for over a decade, and he’s been a major contributor to our team. We could not be more excited to have him take on this new responsibility.
English

VidyaData retweetledi

The iPad may be the most useless piece of hardware but we gotta appreciate how well it ages with time. This is an 8-year-old iPad and still runs like butter ❤️
English