English
Willy
217 posts



DeepSeek-v4 now runs at ~23-26 tok/s on MLX! I made some custom kernels for the sinkhorn and it took gen speeds for 17 -> 26 tok/s. The weights are also significantly smaller thanks to @pcuenq tip about keeping the experts in MXFP4! Now you can use it to power your local coding agents (PI, Open code, Hermes agent or even CC) PR: github.com/ml-explore/mlx…
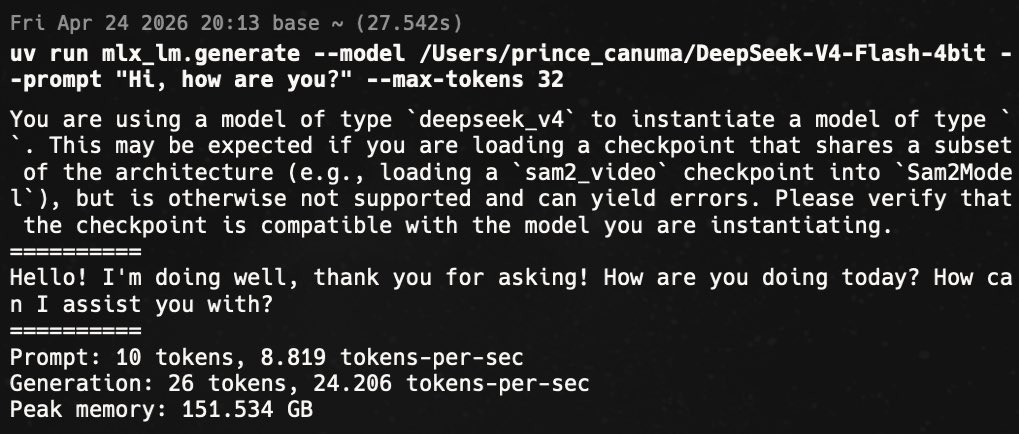
DeepSeek-V4 running on M3 Ultra 🚀 Don't mind the speed, that's gonna improve soon.






Marc Andreessen: AI will weaken the manager class, help innovators beat dull managerial systems & force big incumbent firms to innovate fast or collapse. "The innovators need to figure out how to leverage AI to actually do this."




We saved our customers over $1.3 Billion in 2025 alone. That value has helped @Airwallex reach $1.2 Billion in ARR, growing 85% YoY. @Deel, @McLarenF1 , @boltapp and 200,000+ other customers trust us because legacy banking wasn't meant for global businesses: • Opening a bank account in a new country takes weeks • SWIFT transfers take 3-5 days • Other platforms convert your money even when you don't want to But with Airwallex you can: 1. Open an account and get paid like a local in 70 countries Most platforms force you to convert your money into your currency and charge you a conversion fee to do it. With Airwallex, your UK client pays you in GBP and it sits in your GBP balance. Your Australian client pays in AUD and it sits in your AUD balance. When you need to pay a UK vendor or run Australian payroll, you can simply pay from the same currency in your Airwallex account which leads to zero conversion fees. 2. Send and receive money on the same day SWIFT takes 3–5 days and hits you with unpredictable fees on every transfer. But over 90% of Airwallex transactions happen on the same day. Since Airwallex uses local rails to move your money, it also happens at near-zero cost. 3. Issue multi-currency cards instantly Airwallex helps you issue multi-currency cards to your employees across the entire world. And every transaction is automatically synced to your accounting system in real-time. 4. Integrate Airwallex in your product SaaS platforms and marketplaces can also use our APIs to offer these financial services to their customers. In fact, many companies are doing it already. But this is just a glimpse of what Airwallex can do. We’re building the all-in-one financial stack your company will ever need. If you're doing $50M+ in revenue, you could save up to $500k in fees. And that's money back into your business. Sign up for a demo here: airwallex.com/offer/airwalle…

Yann LeCun (@ylecun ) explains why LLMs are so limited in terms of real-world intelligence. Says the biggest LLM is trained on about 30 trillion words, which is roughly 10 to the power 14 bytes of text. That sounds huge, but a 4 year old who has been awake about 16,000 hours has also taken in about 10 to the power 14 bytes through the eyes alone. So a small child has already seen as much raw data as the largest LLM has read. But the child’s data is visual, continuous, noisy, and tied to actions: gravity, objects falling, hands grabbing, people moving, cause and effect. From this, the child builds an internal “world model” and intuitive physics, and can learn new tasks like loading a dishwasher from a handful of demonstrations. LLMs only see disconnected text and are trained just to predict the next token. So they get very good at symbol patterns, exams, and code, but they lack grounded physical understanding, real common sense, and efficient learning from a few messy real-world experiences. --- From 'Pioneer Works' YT channel (link in comment)