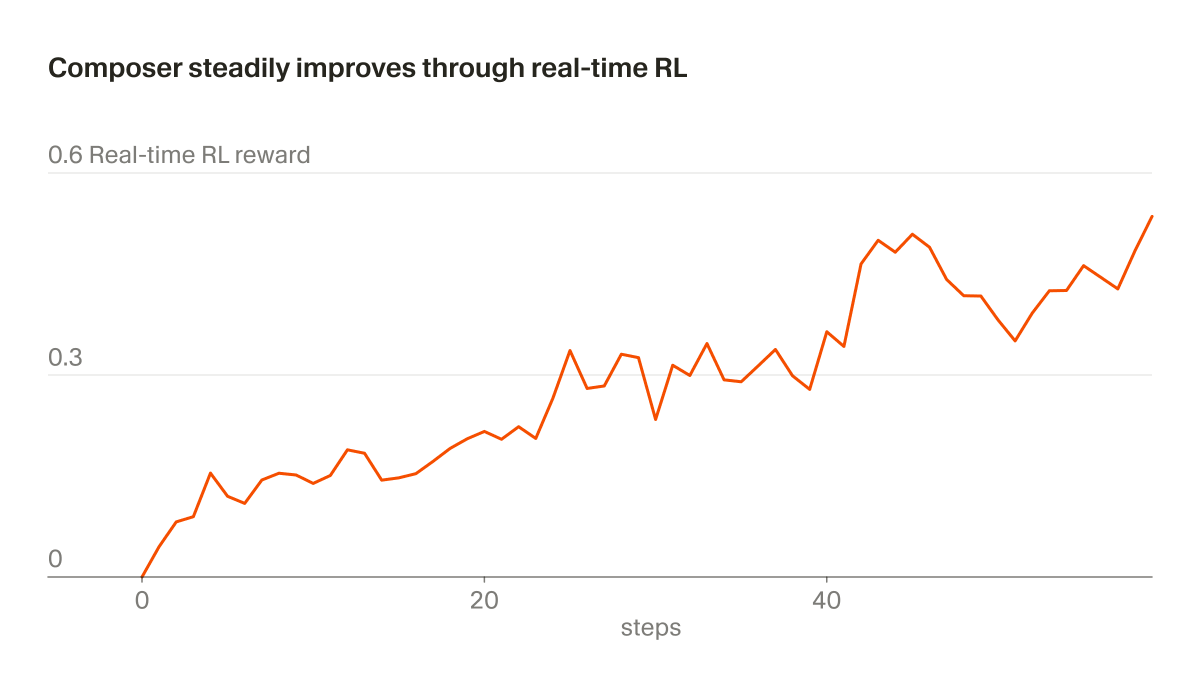
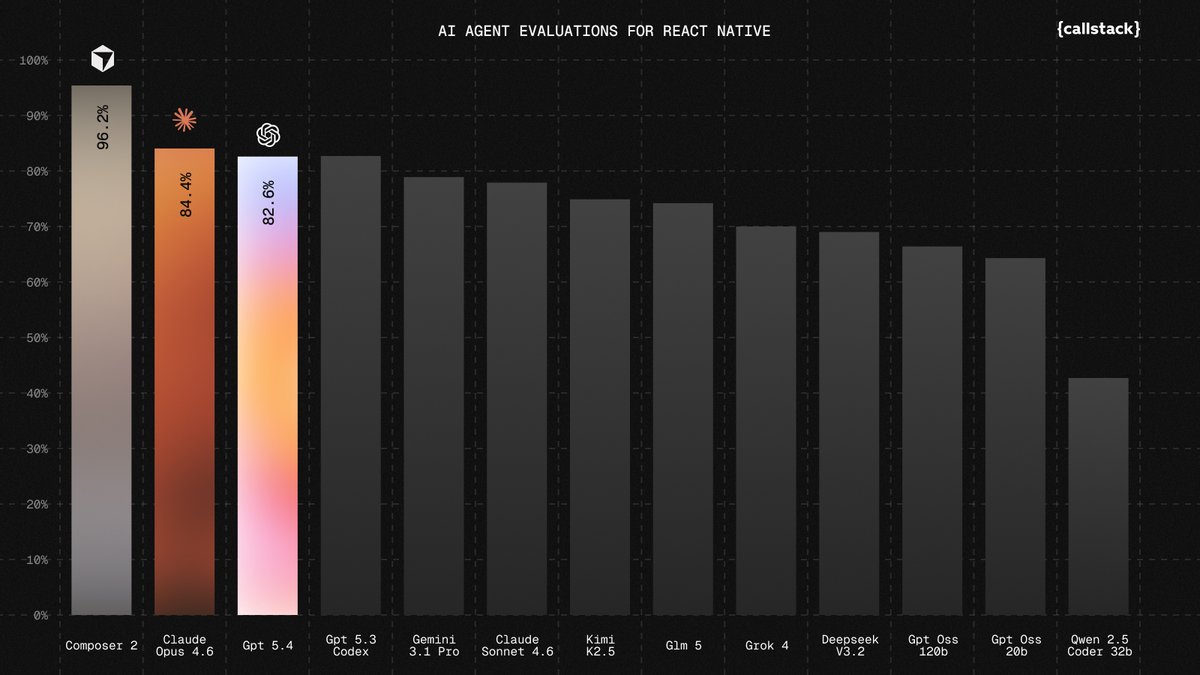
Cursor's new Composer 2.5 takes third on the Artificial Analysis Coding Agent Index and is ~10-60x lower cost than the higher-effort Opus 4.7 and GPT-5.5 variants above it. This release puts Composer among the leading coding agent models, something that wasn’t clear for past releases @cursor_ai has released Composer 2.5, the latest model in its Composer line. Composer 2.5 scored 62 on our Coding Agent Index, a 14 point gain over Composer 2 (48). This puts it in third place of our tested agents, behind only Claude Opus 4.7 (max) in Claude Code (66) and GPT-5.5 (xhigh reasoning) in Codex (65). These cost $4.10 and $4.82 per task respectively, ~10x the cost of Composer 2.5 Fast ($0.44) and ~60x the cost of Composer 2.5 standard ($0.07). Key results for Composer 2.5 in Cursor CLI: ➤ Cost-quality Pareto frontier: At $0.07 (standard) and $0.44 (Fast) per task, Composer 2.5 is cheaper than every other agent scoring above 60 on the Index. Medium-effort peers cost $1.24–$2.21 per task; higher-effort variants land 3-4 points above at $4.10–$4.82 ➤ Per-benchmark gains vs Composer 2: +35 points on SWE-Bench-Pro-Hard-AA (12% → 47%), +2 points on Terminal-Bench v2 (64% → 66%), and +3 points on SWE-Atlas-QnA (69% → 72%). At 47%, Composer 2.5's score on SWE-Bench-Pro-Hard-AA is comparable to Claude Opus 4.7 (max) in Claude Code ➤ Among the fastest coding agents: Composer 2.5 Fast runs at an average wall time of 6.7 minutes per task, the third-fastest agent on the Artificial Analysis Coding Agent Index, behind only Claude Opus 4.7 (medium) in Claude Code (5.8m) and GPT-5.5 (medium) in Cursor CLI (6.2m) ➤ Fast mode enables better responsiveness at 6x pricing: Fast runs 30% faster than standard Composer 2.5, but is ~6x the cost per task ($0.44 vs $0.07). Token pricing is 6x higher for Fast: $3.00/$15.00 vs $0.50/$2.50 per million input/output tokens Model details: ➤ Base model: Continued training on @Kimi_Moonshot's open weights Kimi K2.5 as with Composer 2, with Cursor reporting ~85% of total compute from its own additional training and reinforcement learning ➤ Pricing: $0.50/$2.50 per million input/output tokens for the standard variant; $3.00/$15.00 for the Fast variant (the default in Cursor) ➤ Available exclusively in Cursor: both Cursor IDE and Cursor CLI, an externally accessible API is not available Congratulations @cursor_ai and @mntruell on the impressive release!