Sabitlenmiş Tweet
Josh
158 posts


Josh
@_joshwong
buildingcoolsh*t @0xrandomlabs
San Francisco, CA Katılım Mart 2024
254 Takip Edilen166 Takipçiler
Josh retweetledi

We've been hard at work improving the Slate CLI
Today we're releasing V.1.0.34 which includes:
- A fully rebuilt agent
- A brand new tui built in OpenTUI
- And much more
We're now able to support many of the features you've all been asking for!
English
Josh retweetledi

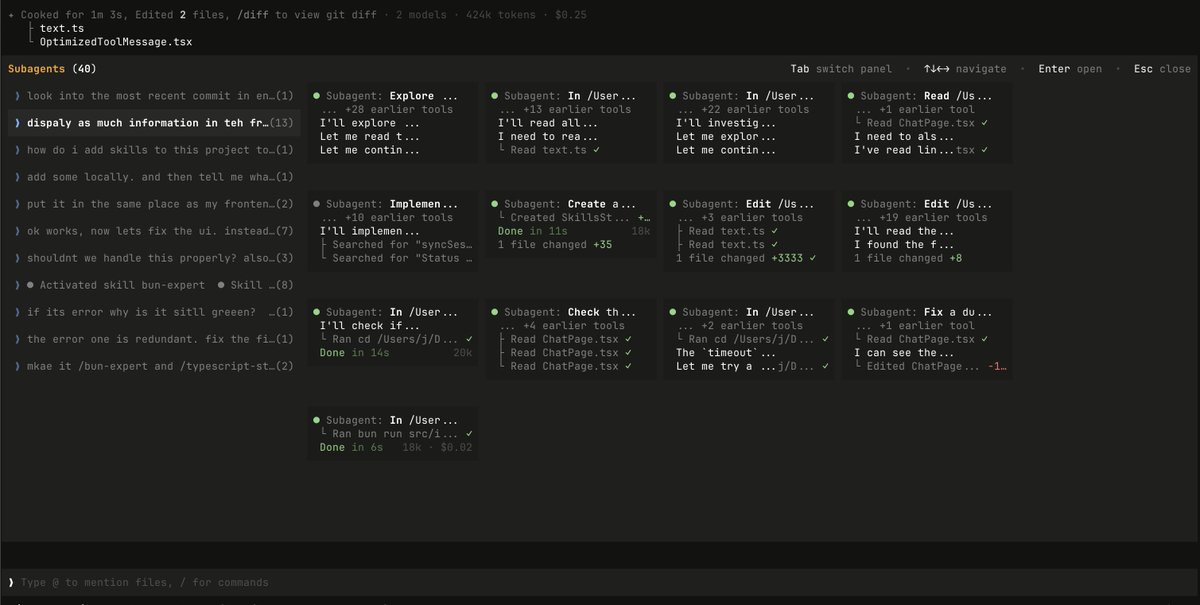
This current view’s purpose is for navigating through (what could be) hundreds of subagent sessions in a given session
It lets the user jump into any subagent session and view the full chat history.
Progressive disclosure is important here; the main view is good for knowing that “stuff is happening” but doesn’t give much info other than surfacing any edits that happen in the main chat history and the status of each agent + minimal tool history.
The orchestrator in Slate can actually reuse subagents with follow up messages or new tasks, so session information can become non-trivial
Also, when a user jumps into a subagent session, they can interact with with subagents directly.. then pop back up into the main session
Subagents can also be assigned skills by the orchestrator, so you can get the full skill use details with the same method mentioned above
English

@_joshwong @0xrandomlabs Why do you expect users to review each subsession / have such detailed overview?
English
peek: currently working on better ux for subagent navigation for sessions with 50+ subagents
long-running sessions can build up over 100 subagent sessions total. a flat grid of 100 subagent boxes is hard to navigate, and at some point, not even renderable bc of screen space
trying rn to make it slightly more scalable by:
> grouping by user message turn,
> labeled by the user message
> only shows the subagent sessions that were created/used in that turn
the idea is that each turn has way less subagents than if you were to show the entire set from the session
English
Josh retweetledi

Slate is one of the more ambitious projects out there right now. Find myself consistently agreeing with the direction they are taking. Really smart team. Bullish!
akira@realmcore_
English
Josh retweetledi





Josh retweetledi

Josh retweetledi

I kept saving design AI agents/skills across 10 different places, so i built one place for all of them.
Anyone interested?
English
Josh retweetledi

nobody talks about the ux problem with agent swarms
i've been running multi-agent setups and the terminal experience is genuinely awful. you spin up 3-4 agents and you're just reading interleaved stdout trying to figure out which one is hallucinating and which one actually found something useful.
saw @realmcore_ building slate, lets you run opus 4.6 and gpt 5.4 side by side in the same terminal. said making it intuitive took a ton of work. i believe it.
most agent frameworks right now treat the human as an afterthought. you kick off a swarm and pray. zero visibility into what's working and what's just burning tokens.
the agent layer is moving fast but the interface between you and a swarm of them is still basically tail -f and vibes.
English
Josh retweetledi
Josh retweetledi

Agents perform better the closer they are to the source of truth
> you're debugging something.
> you say "its still not working. the ___ is still broken"
> this happens two or three more times.
> sometimes it feels like progress, sometimes it just feels like rerolling. you go two steps forward, one step back.
this is the "working loop". you're the one stuck working. it feels low confidence, tedious.
What helps is to stop for a bit, think, and ask. what do i need to do to make this more observable for the agent?
What facts is it missing to actually see what's wrong?
There are two things to close the gap on:
1) Intent - this is more like a prerequisite. you need to make sure you and the agent are aligned on what you're trying to do. align on the expected outcome. If you're not sure, ask it. Not being aligned on intent means you're both working toward different directions and no amount of effort on the second point will solve it. Sometimes you won't even realize it until after you've wasted a bunch of time
2) Evidence - the concrete facts the agent can use to verify. Most of the time it knows what the right answer looks like. What you're trying to do is present the environment clearly enough that it can compare *what it is now* to *what it should be*
Once you give it a way to spot the gap, let it take action to make meaningful progress on its own.
Your job in the loop isn't to paste it logs.
Your job is to remove ambiguity and let the agent take over the loop to close the gap itself
English
some things i haven't fully thought out yet:
- for the left panel, is it more intuitive to lay out the list in the order of chat history? oldest (top) to -> latest (bottom), or most recent first (or selected) since older chats matter less and latest chats matter more
- what if in a *turn*, there are 100 subagents? probably rarer to come across this for now, unless you're having slate one-shot a big task
- more navigation interactions
English
Josh retweetledi
At Random Labs,
We mostly care about one thing: making ai actually work for software engineering. If this sounds interesting, contact us at team@randomlabs.ai
Anyways here's a hardstyle edit of a support ticket on our discord because one of our mods thought it would go hard
English
Josh retweetledi
Josh retweetledi

The company that actually builds the agent-first code factory is going to be worth hundreds of billions of dollars.
No one has cracked it yet.
It can't be the model labs because then you're tied to one model.
I'm hoping a company like @linear will do this.
I'd happily pay thousands of dollars a month for that (+ the token cost).
Basically, we need SDLC 2.0 for the agent age.
(Also, the right solution can't rely on gh - we need whoever does this to completely replace it as well.)
English
Josh retweetledi

Slate で Claude Opus 4.6 と GPT‑5.4 を、1つのターミナル上で同時に回せるようになったらしい。
エージェント群をここまで素直に扱えるツールって、たしかに他にあまり見ない。
「どのモデルが最強か」じゃなくて、「得意分野の違うモデルをどう並列運用してワークフローを組むか」が本格的にUI付きで扱える段階に入ってきた感じ。
Opus 4.6 に戦略や推論を任せつつ、GPT‑5.4 に実装やAPI叩きを投げる…みたいな構成を、ターミナル1枚で試せるのはかなり良さそう。
──────────────────────
▼ 補足情報
元ポストで言及されている Claude Opus 4.6 は、Anthropic の最上位モデルで、複雑なコーディングやエージェント構築、長文コンテキスト処理に強い位置づけのモデルです。
Google Cloud の Vertex AI でも提供されており、ベンチマークでは Terminal-Bench 2.0 や SWE‑bench などのコーディング系テストで高スコアを出していて、「エージェント的にツールを呼び分ける」タスクに最適化されています。DIA-SOURCE
一方 GPT‑5.4 は OpenAI の最新世代モデルで、OpenAI API から利用可能なほか、Codex 系(開発用)の設定ではバックエンド実装やロジック生成が得意という評価が多く、Reddit などでも「フロントエンドは Opus 4.6 が空間把握に強いが、バックエンドは GPT‑5.4(Codex)が安定」という声が上がっています。
こうしたモデル特性の違いを踏まえて、「プランニング・レビューを Opus、実装を GPT‑5.4」など役割分担させるマルチモデル運用は、すでに Reddit や技術ブログでも多くの事例が出ており、Slate のように1ターミナルで同時実行・管理できるUIは、そのワークフローを簡単に試せる環境として位置づけられます。
0xMarioNawfal@RoundtableSpace
Slate lets you run Opus 4.6 and GPT 5.4 at the exact same time in one terminal. No other tool handles agent swarms like this. The multi-model workflow just got a proper UI.
日本語