Aidan
82 posts


Aidan
@AidanGior
Always building. Usually somewhere between accounting tech, automation, AI agents, market intel, and business software.








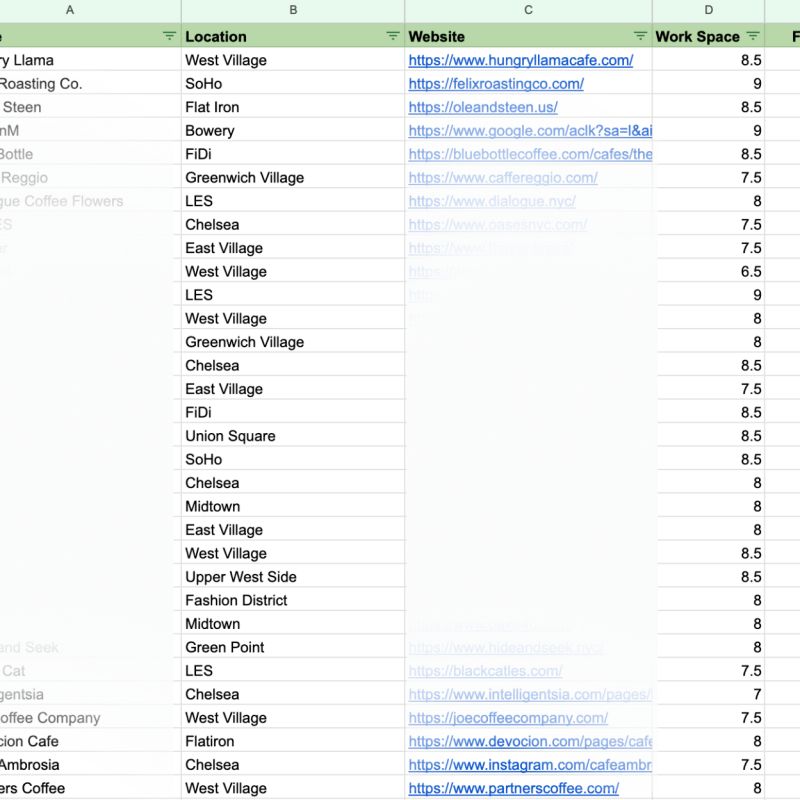







Company Brain @t_blom Every company has critical know-how scattered across people's heads, old Slack threads, support tickets, and databases, and AI agents can't operate like that. We think every company in the world is going to need a new primitive: a living map of how the company works that turns its own artifacts into an executable skills file for AI.

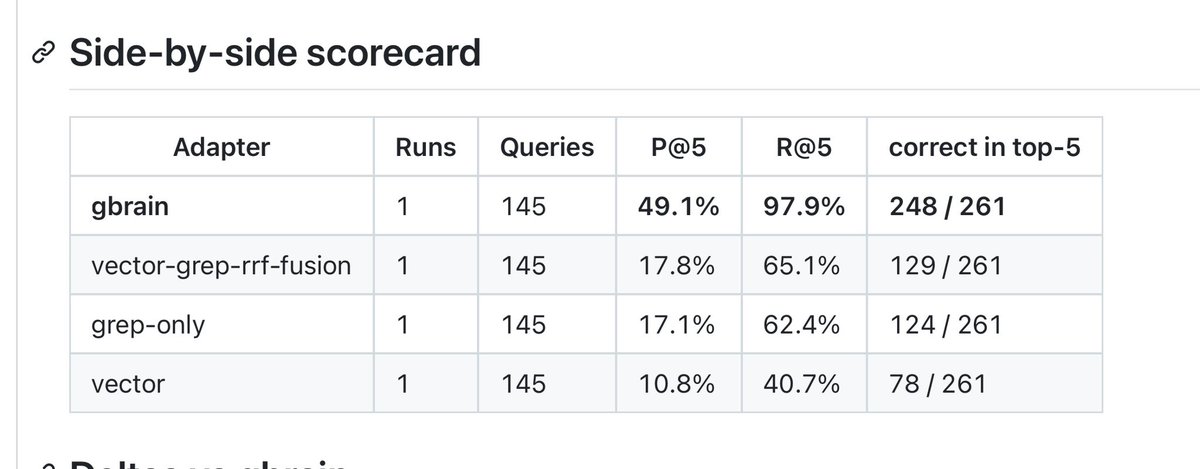




Last week, we released a preview of memories in Codex. Today, we’re expanding the experiment with Chronicle, which improves memories using recent screen context. Now, Codex can help with what you’ve been working on without you restating context.









By popular demand, another NYC hidden gem: free lockers and changing room at NYRR on 57th and 8th ave. Going for a run in central park 🏃



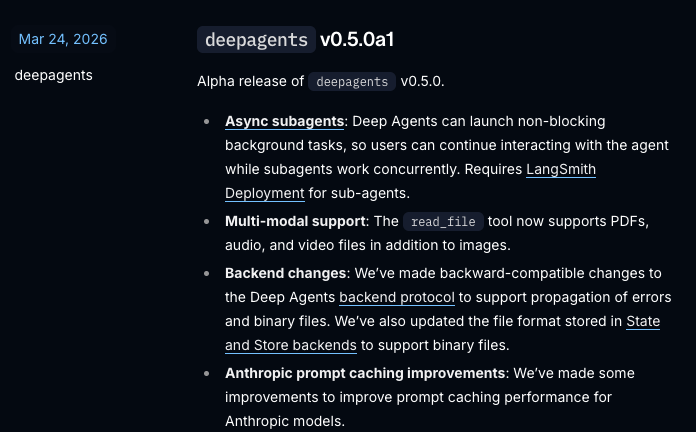


Your work tools in Claude are now available on mobile. Explore Figma designs, create Canva slides, check Amplitude dashboards, all from your phone. Give it a try: claude.com/download