Ajay Patel retweetledi

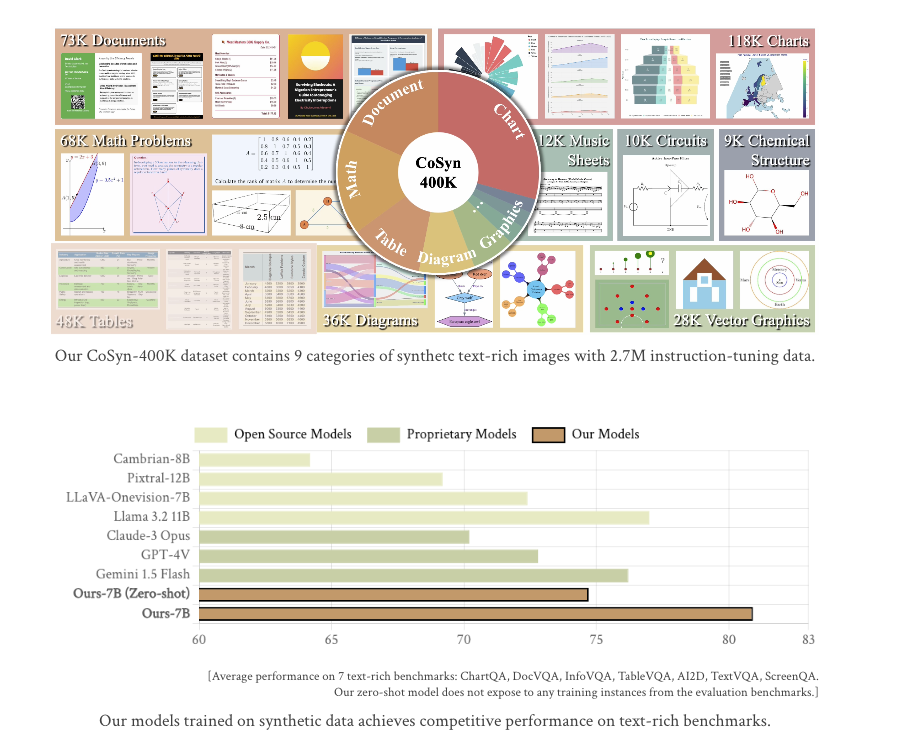
We share Code-Guided Synthetic Data Generation: using LLM-generated code to create multimodal datasets for text-rich images, such as charts📊, documents📄, etc., to enhance Vision-Language Models.
Website: yueyang1996.github.io/cosyn/
Dataset: huggingface.co/datasets/allen…
Paper: arxiv.org/pdf/2502.14846
Code: github.com/allenai/pixmo-…

English