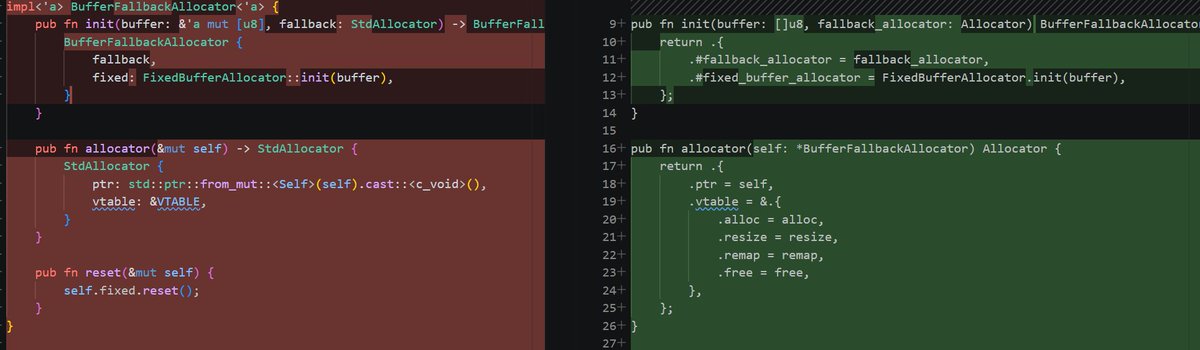
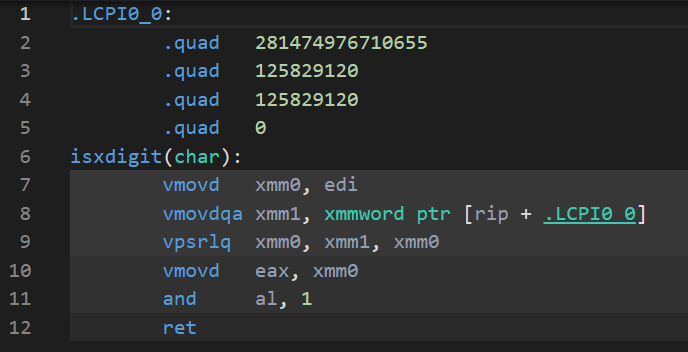
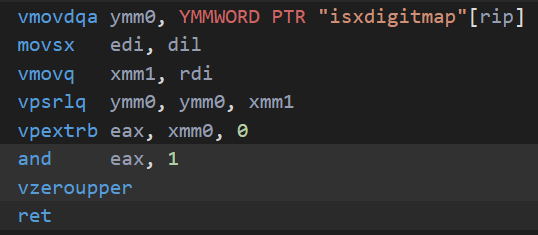
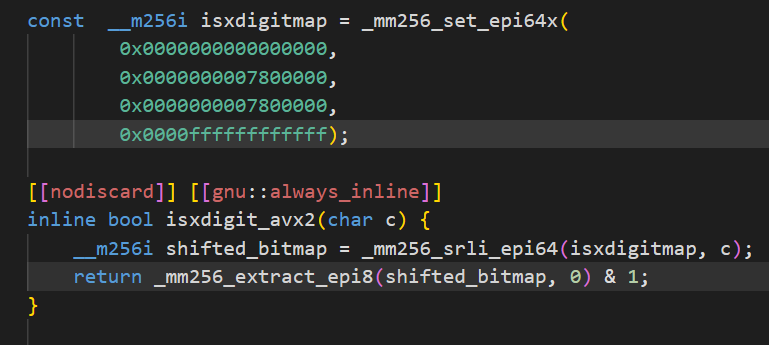
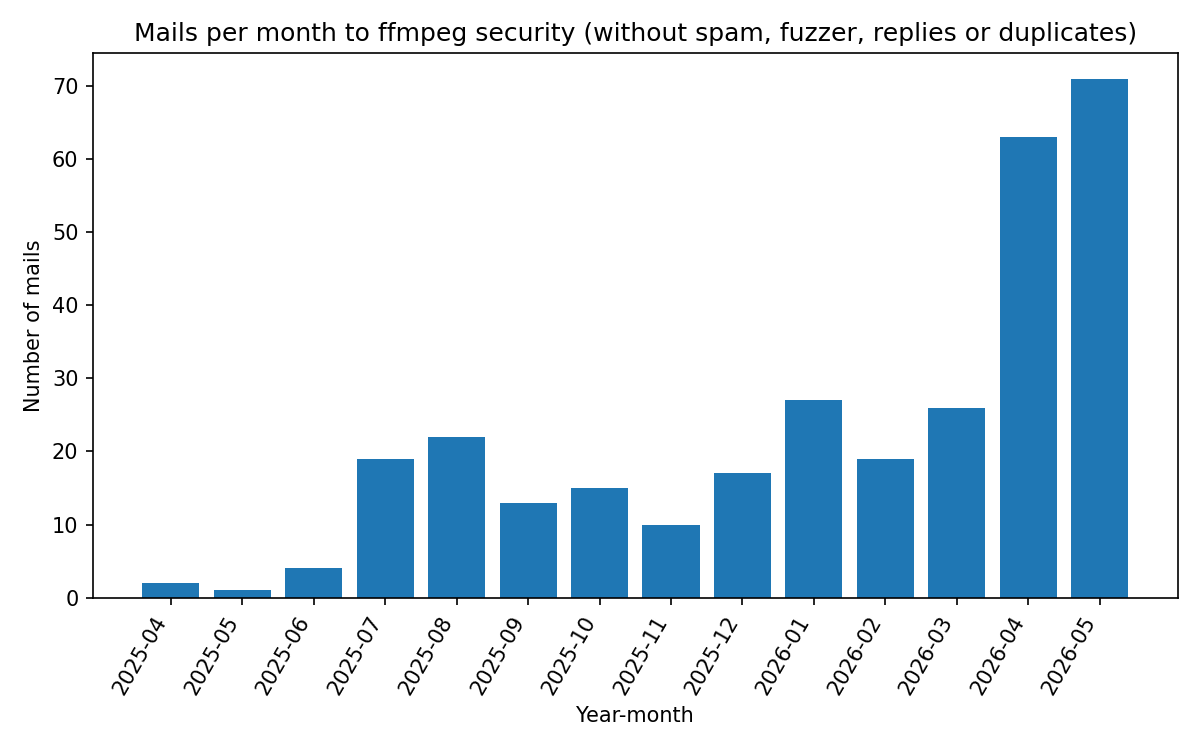
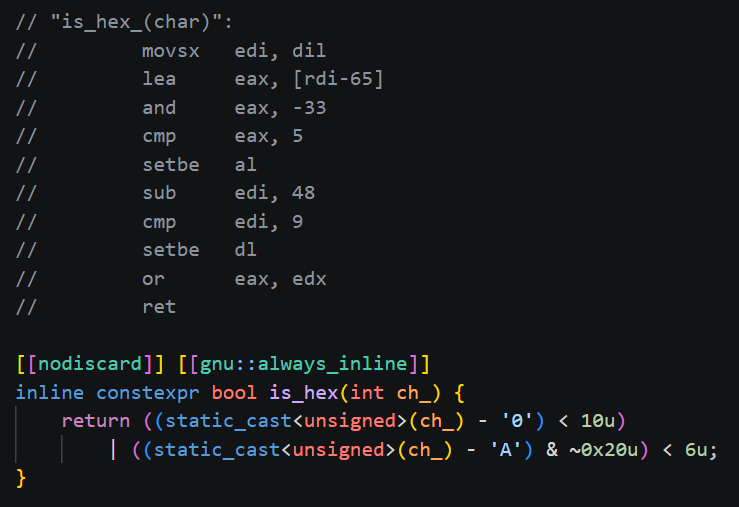
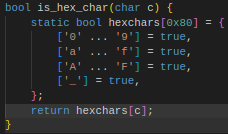
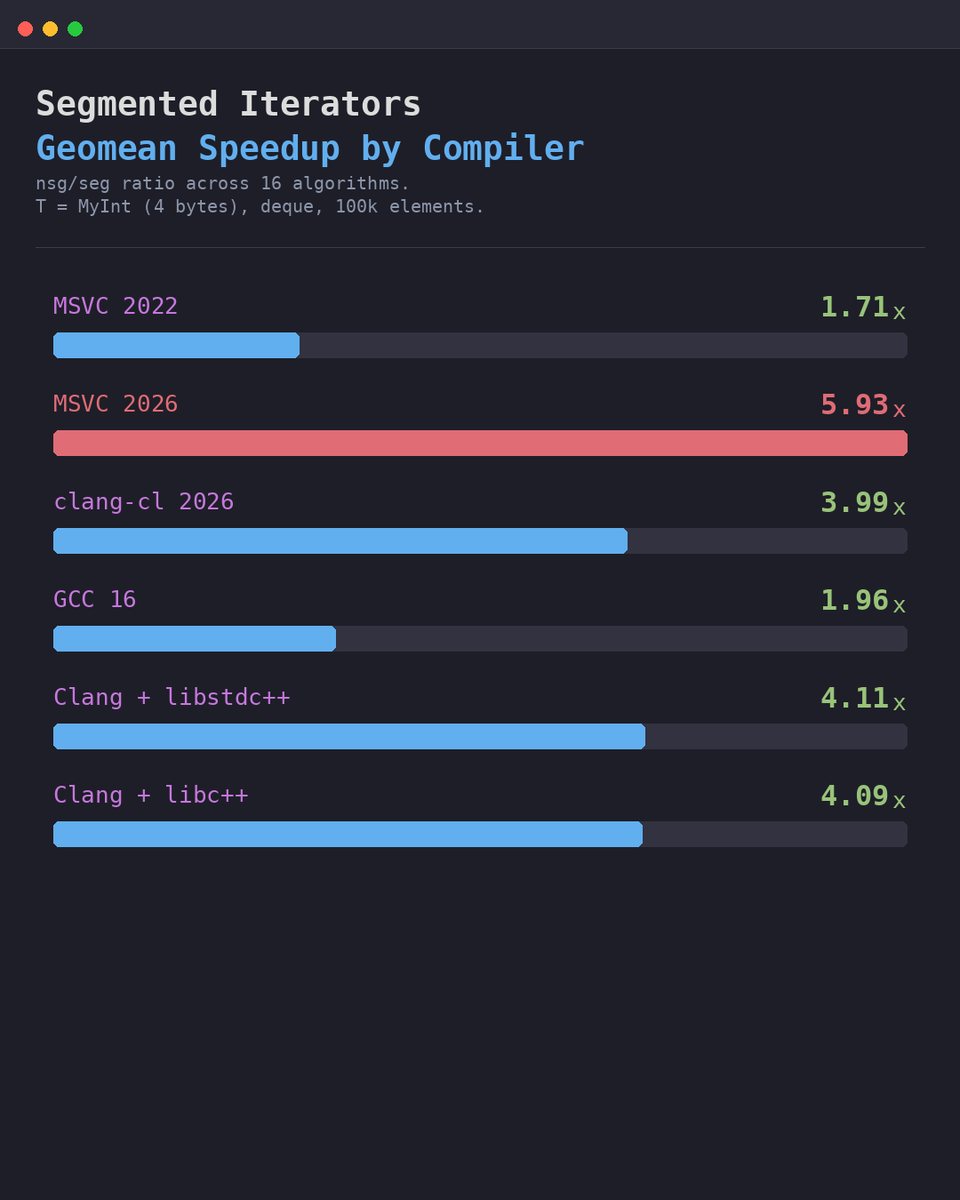
@saltyAom That is like saying you need concrete proof that "something break" when I fire all the senior engineers. Look, you can live in a shanty town or you can have concrete buildings and plumbing. Either way nothing break right? The bun port is 60% pointless garbage, bruh.
English