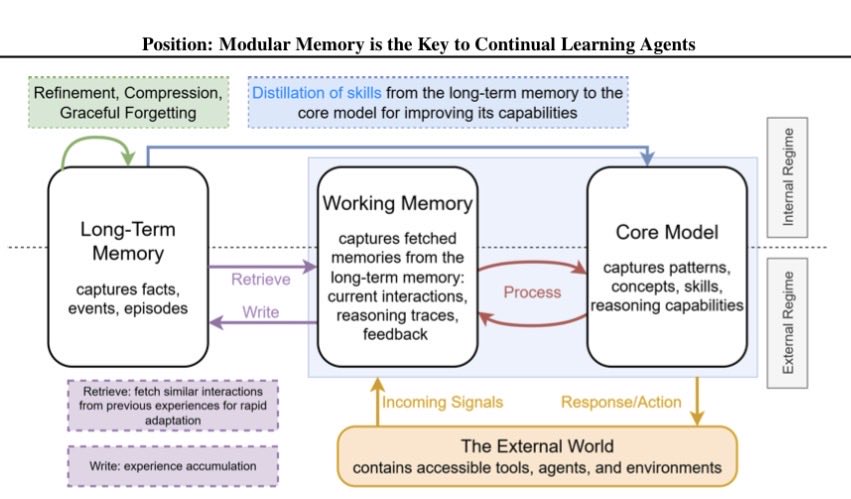
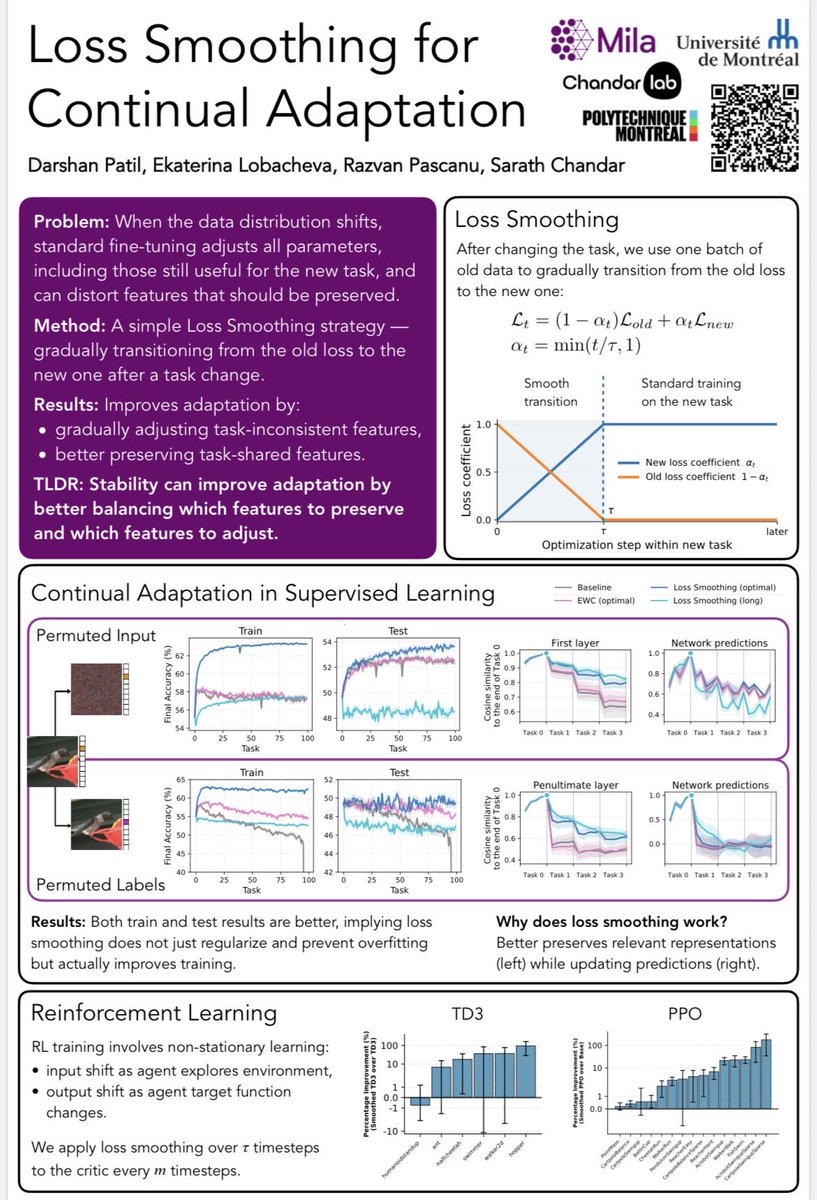
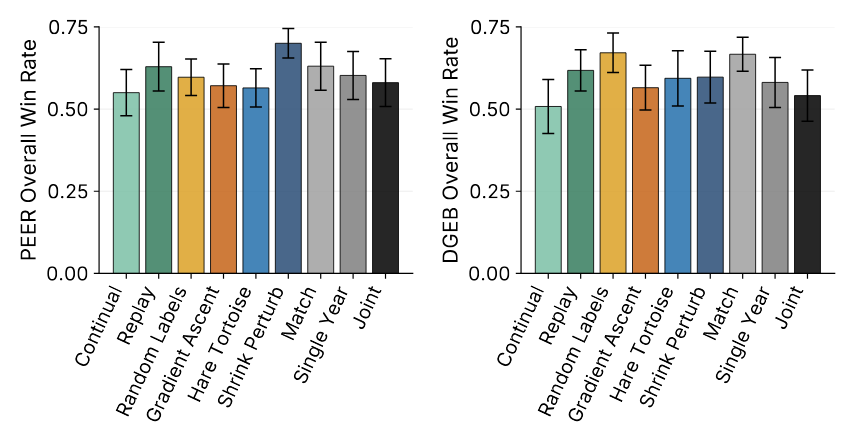
Sabitlenmiş Tweet

🧬 New paper
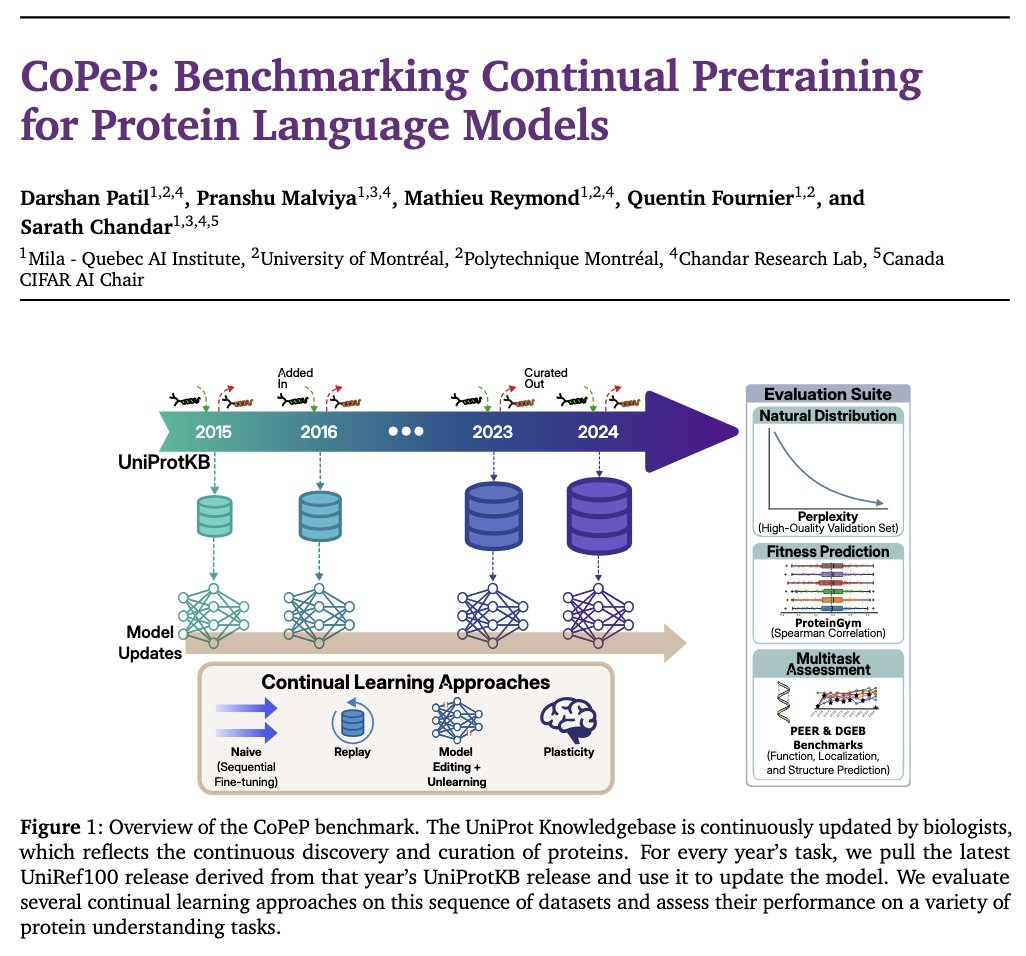
Scientific datasets evolve as science evolves. With proteins, new sequences get added, annotations get corrected, and noisy entries get curated out.
Introducing CoPeP, a continual-pretraining benchmark for protein LMs.
Details 🧵
1/n
English