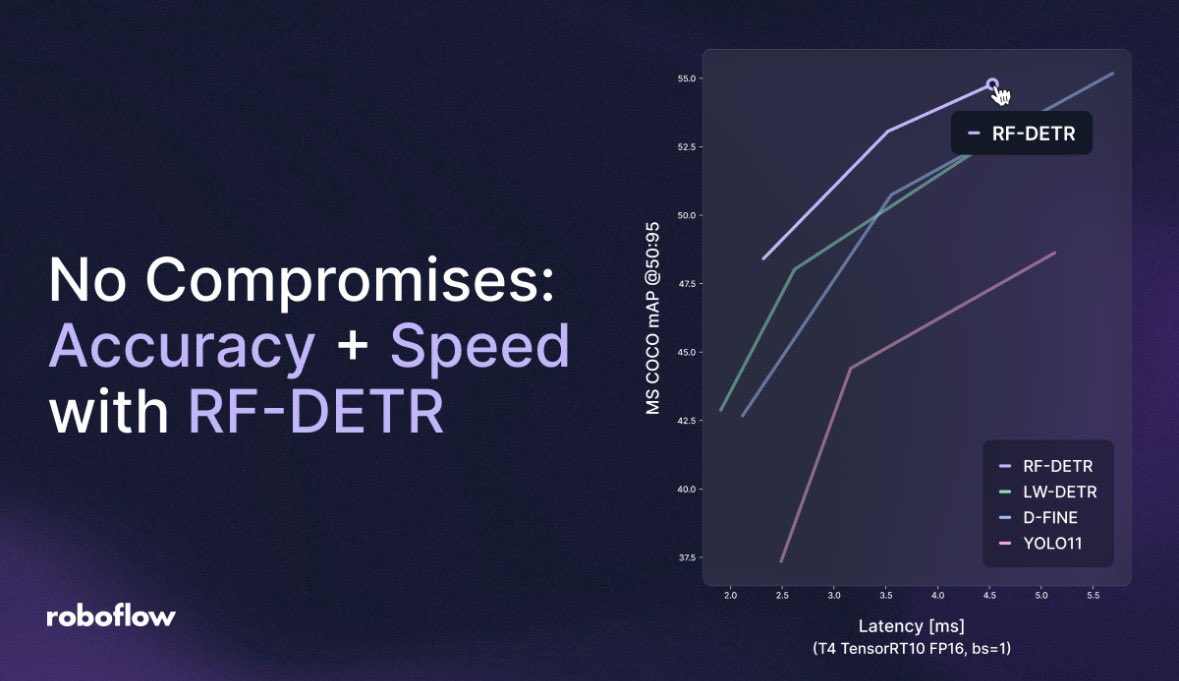
eggwalking retweetledi

如何培养青少年的判断力和创造力?
以色列可能是全球最好的表率之一
这个人口仅1000万的小体量国家,
却大量向美国输送10亿美元初创企业创始人
(按每百万人口涌现的独角兽创始人计算,
是美国的162倍)
我曾在以色列特拉维夫大学学习,
亲身感受到他们的教育哲学:
不是教孩子“标准答案”,
而是把整个社会变成判断力和创造力的训练场:
用前沿技术学前沿知识,
10岁就开始做自己想要的东西
以色列孩子从小就被鼓励:
1. 在高度不确定性中快速做决策
2. 敢于挑战权威和质疑主流观点
3. 把失败视为正常实验成本(而非人格失败)
4. 把“为什么”和“如果”当作日常语言
他们没有把教育做成“知识灌输机器”,
而是做成了高强度判断力 + 创造力演练场。
这也是为什么以色列以极小的国家体量,
却能诞生如此多全球级创新公司。
对我们中国企业主/高认知家庭的启发:
AI时代,执行力会被大幅压缩,
真正稀缺的是判断力
(在模糊环境中抓指向未来的核心变量)
和创造力(把不可能变成可能/改写约束)。
我们不需要把孩子送到以色列,
但完全可以借鉴这种第二轨道的培养逻辑:
用真实世界高阶输入(而非教材)
大量练习“开放式判断”(而非标准答案)
把失败和不确定性变成日常训练,
结合AI工具做自己喜欢的项目
判断力和创造力并非天生,
而是结构化训练的结果。
想了解如何在国内帮10-16岁孩子
建立这种“以色列式判断力 + 创造力”路径的家长,
评论「判断位」
我下一条分享具体可落地的训练框架
#AI与教育 #以色列教育 #判断力与创造力
下图:美国独角兽创始人原国别
以色列移民是美国本土独角兽创始人的
移民创始人占美国10亿美元估值初创企业的50%

Crémieux@cremieuxrecueil
Relative to native-born Americans, several countries' immigrants to America have produced vastly greater rates of unicorn founders. In particular, Israel: with shockingly few people in the U.S., Israel is the #2 origin *in total* for foreign Unicorn founders.
中文