Henry
47 posts



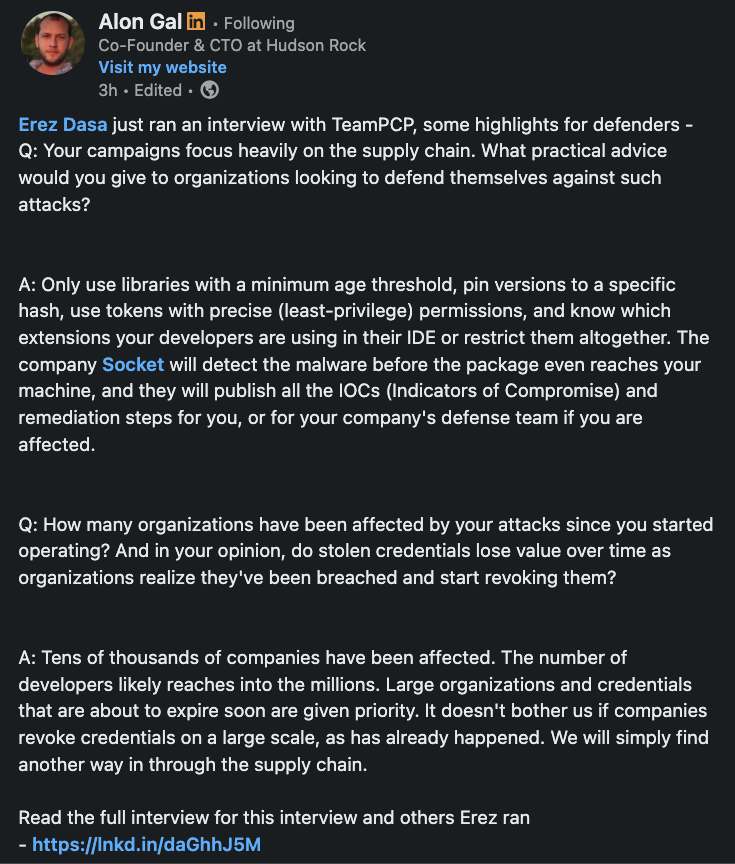
TeamPCP just did an interview where they were asked what defenders should do to stop supply chain attacks.
Their advice: pin versions to a specific hash, use least-privilege tokens, restrict IDE extensions. And then, verbatim: "The company Socket will detect the malware before the package even reaches your machine."
So... thanks, I think?
We're not putting this on the testimonials page.
But at the same time, if you're not yet using @SocketSecurity to protect your supply chain, what are you waiting for?
English


Classic reddit/bsky behavior... What a garbage website
Carl Lerche@carllerche
Apparently, if a crate is not 100% human written, it is OT for /r/rust: reddit.com/r/rust/comment…. I have been working on Toasty for 3 years, 9 months with AI tools. I am proud of the code quality and stand by it. By their standard, the entire tokio-rs GitHub org is now OT.
English

A lot of Go devs get taught a fake rule: never use panic. The advice is simple but it is also lazy.
Panic is just a sharp tool that needs to be used correctly. The real advice is do not use panic for normal failure, use it when the program has reached a state that should not exist and cannot be handled in a sane way.
If your code can recover, return an error. If your code is
- broken,
- your assumptions are false,
- startup cannot continue,
Basically, this can't be happen, if this happen, my data is corrupted, my application is not in correct state, etc.
Then failing hard is cleaner than pretending everything is fine. Bad error handling is often worse than no error handling. People wrap impossible states in polite-looking error returns and push the mess upward, so now every caller has to act like a broken invariant is just another routine case. That makes code noisier and less honest.
So a well-placed panic can say something important: this is not business logic, this is a bug, a bad configuration, or a state the program was never designed to survive.
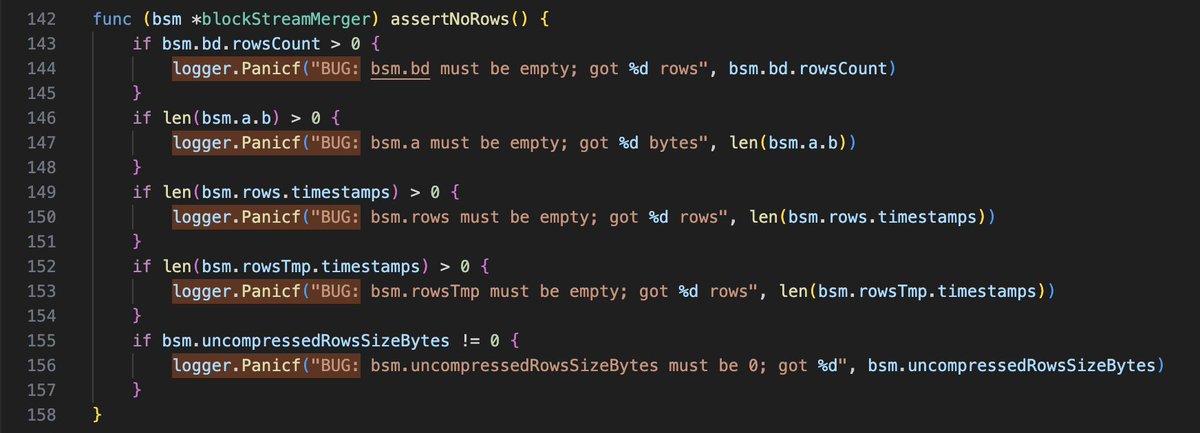
We do use panic in our codebase to catch corrupted state early: #L142" target="_blank" rel="nofollow noopener">github.com/VictoriaMetric…
English
@GiuocoPianoSimp @rachpradhan Trying to be the smartest in the room too bad - in every ecosystem - multiple systems exist at once.
He's just added an option for the peculiar case you dont know about.
He never asked you to replace yours - he gave everyone another option.
Want to use it? - ask him for tests.
English

@rachpradhan Why don't you say instead that claude or whatever model you used replaced FastAPI'# entire HTTP core with Zig?
You want a fully ai written library to replace a well tested one? If you're handling more than 6k req/s you might as well consider using a different language than python
English



favorite feature of my soon-to-be-launched markdown macOS app is that it gives you markdown formatting in Quick Look 💅

English


@ikindacode If this is a demo tool and you need some quick persistence shoot progressdb.dev/docs/integrati…
English

AI SDK + json-render = 🔥🔥🔥
Although I am having a hard time persisting chats to the database with this setup (and so is Claude Code). Something about the way streaming + piping to JSON-render interact has me stuck: I can either have streaming and no persistence, or I can have persistence without streaming.
Has anyone done this successfully and have an example?
cc: @nicoalbanese10
English
@_rosebennett @BenjDicken - most engines offer the ability to trigger compaction in your own time.
- read penalty under load: sizing correctly the files needed to load into memory at a time is a prime start.
Advantage is most engines expose these as triggers/ticks you can react to it.
all so far.
English

@BenjDicken Beyond write throughput, how do you usually mitigate the "read penalty" or the compaction storms that tend to plague LSM-based engines during peak load?
English

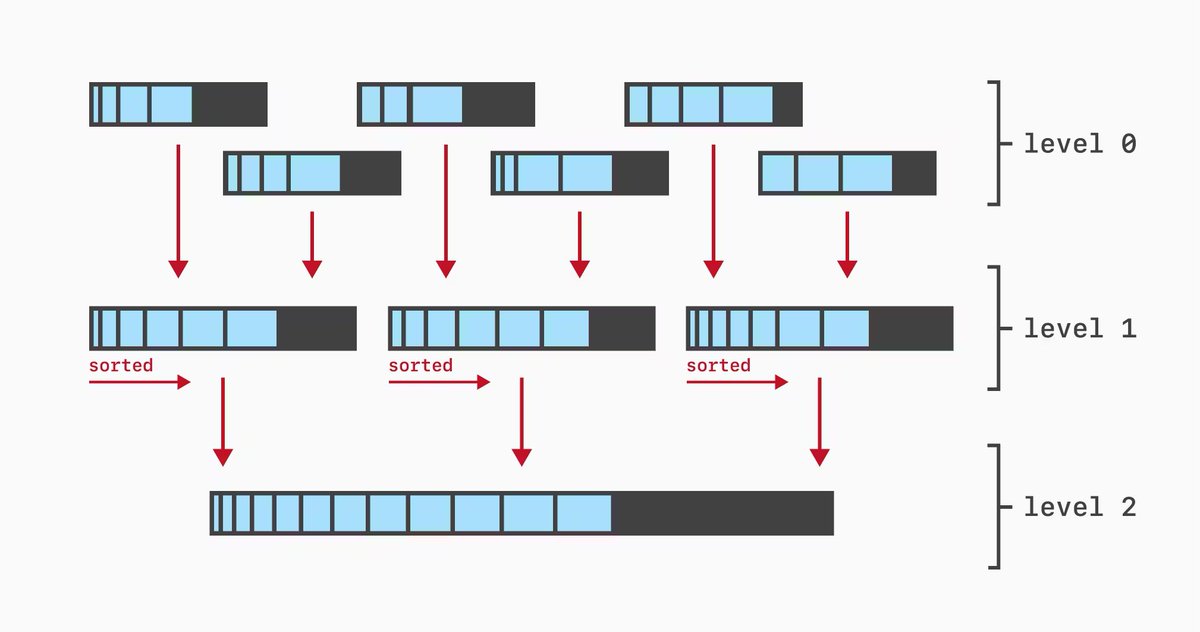
Next chapter of Database Internals is all things log-structured merge trees!
In contrast to B-trees, LSM is used for write-heavy and analytics databases.
Fun fact: MySQL can run with either. InnoDB (the default engine) uses B-trees. MyRocks (built by facebook) runs on LSMs.
English

Since the day we started Documenso we knew that we would eventually have to write our own PDF library, and now we have!
Introducing LibPDF the library that we’ve always wanted for PDF parsing, manipulation and signing (MIT)
English
@gunnarmorling Sequencing - all elements go into a queue - get spread out for processing - op results go to a buffer - reordering is made - checked for sequence integrity - then continues from there.
English

You have an ordered stream, each element requiring some (CPU-intensive) processing. So you want to scale out this step to multiple threads. Ordering after processing must be the same. How do you design this system? One queue? One per core? Batching? Curious about your reasoning.
English

@Danielninom @elwatto Literally! - making all of this just off a website is insane and pretty obvious reason to scale back but nope!
English

I am not sure about the “smarter” part. A smart person wouldn’t have thrown those kind of opinions on an online forum without realizing they lack A LOT of context about why you took the decisions you took. That said, you are totally right: agency and consistency beat smarty pants 100% of the times.
English

These HN comments, from people likely much smarter than me, reinforce the biggest lesson I’ve learned from startups: it’s never the smartest team that wins. It’s the one that persists, keeps going, day after day, doing thankless work to build something people want.
Happy 2026!
Miguel Carranza@elwatto
English
@rashm1n @Hi_Mrinal Uses fasthttp golang for its net/http - done some telemetry on this and its faster in real world latency currency.
Downside is its not standard golang net/http so you can't bolt on plugins without some work.
English


@killme20082 Its a feature - not a bug - the default is performance lost which is non negotiable in e.g a workload like yours (greptime).
English

The cache design of GreptimeDB has been continuously evolving.
Initially, it only included a read cache, then a write cache was introduced, and now it has become more nuanced with components like index cache and manifest cache. Of course, the memory aspect is even more complex.
This is somewhat similar to cache designs in operating systems, such as Page Cache, Inode Cache, Dentry Cache, and Write-back Cache etc., which all address the problem of I/O mismatches.
However, the focus of the operating system is on the interactions between applications, the kernel, and disk, while we concentrate on solving the matching issue between databases (DB) and object storage.
In the future, there will surely be more refined I/O scheduling, such as deciding which data block to prioritize for reading and how to implement prefetching.
English

Transitioned from D1 → Planetscale:
- $5/mo per branch
- Hyperdrive = latency is non-issue globally 🤯
It's 100% premature optimization (product is not live yet) - but I haven't been so excited for a long time.
English
@paulaguti_12 This might save you from some technical work while prepping for that progressdb.dev
English

4 days until Demo Day
Feels like YC started yesterday and also 9 years ago at the same time
English
@catalinmpit i.e most likely you dont need it (i dont) - some even overblow it imo.
so hit some problem or frustration and only then do these become important.
anything else - prob some influencers firehosing the terms.
English
@catalinmpit mcp servers is only you need to integrate an external service.
- e.g if you were to integrate stripe and wanted the agent to know the available tooling and what it does
- so it would not guess, you use it
its like a rest api server protocol but for llm agents.
English

@catalinmpit markdown specs is only when you need some way to describe your idea is depth to the agent without making it guess or be entirely creative on its own. etc
English