Sabitlenmiş Tweet

Bryan Young
287 posts

@intertwineai
Principal Eng @ExpelSecurity | AI Engineer / Founder @intertwineai | Artist Faculty @JohnsHopkins Peabody @poulenctrio






Told my girlfriend, "current $20 Codex sub is not enough. I need to go $100/mo" She suggested, "why don't you open a second $20 Codex account" I feel so dumb🤔







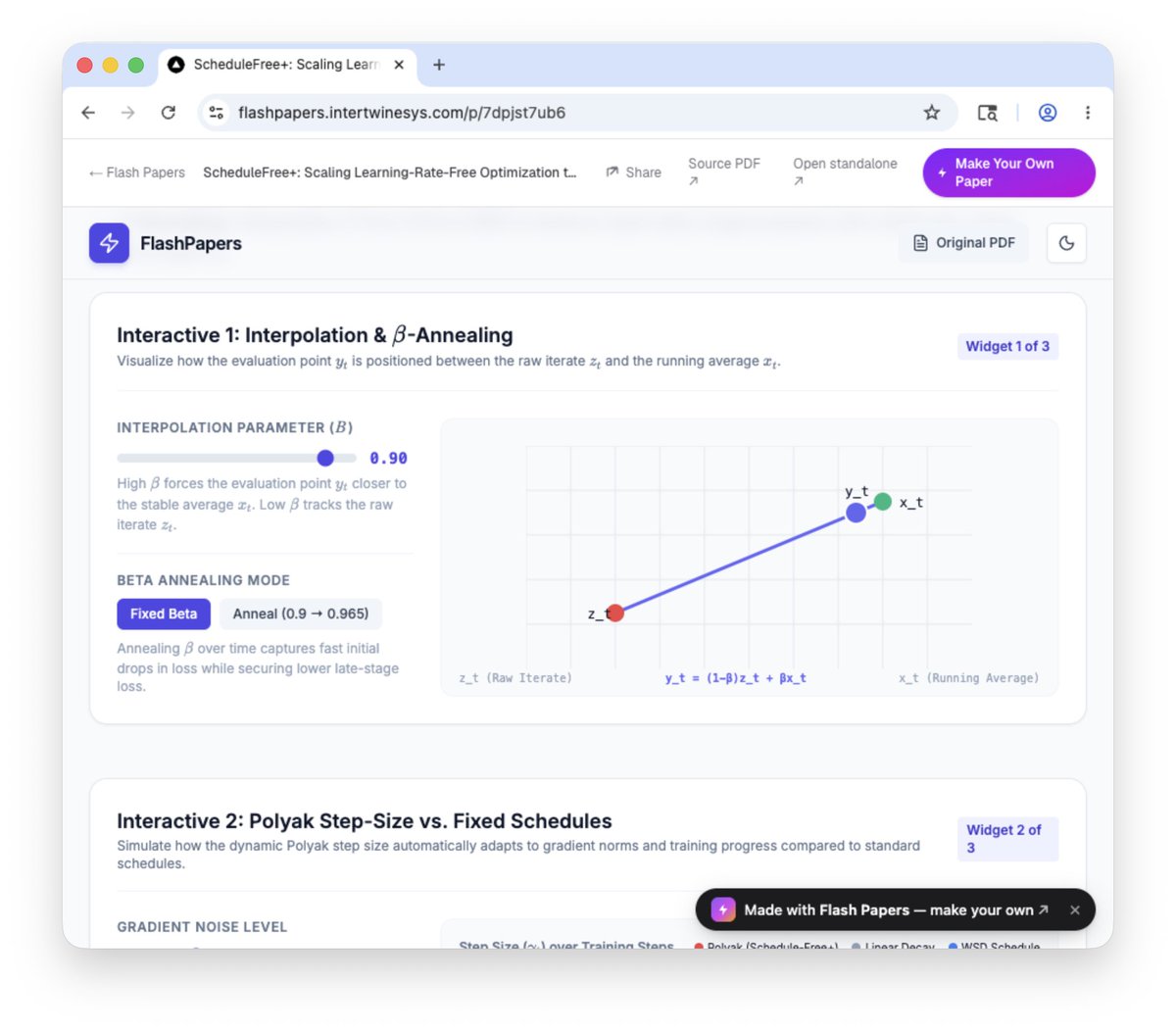
This is an amazing Codex tip. Works even better when paired with persistent Codex memory files in Obsidian. Gave me 8 recommended skills relevant to active projects. Do try this!

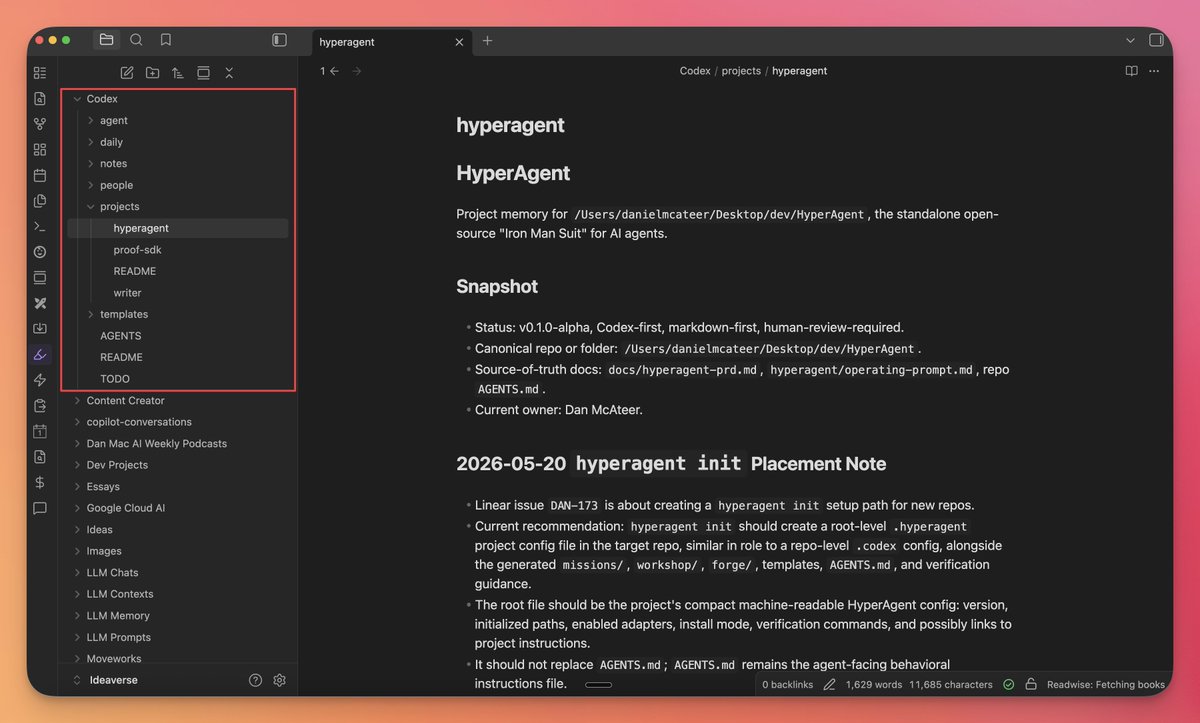
>gave Hermes/Openclaw more memory. all that got me was a junk drawer. >took it apart. agent memory is doing three jobs at once: Remember, Cite, Forget. that's the whole framework. >turned the three jobs into three checks: layer, source, expiry. >packed the three checks into one audit. posts, emails, cron jobs, inbox. all run the same audit. >a few hours in, the junk drawer turns into a stack of labeled cards.
The best way to learn AI is to build with agents. To help with that, we've launched hands-on labs and a new series on Agentic Engineering. First topic: Agent Skills. Next in the pipeline: planning, context engineering, multi-agent systems, long-running agents,.. Go build!

TOP 13 FREE AI COURSES TO TRY IN 2026: 1. Claude 101 👉 anthropic.skilljar.com/claude-101 2. AI Fluency: Frameworks & Foundations 👉 anthropic.skilljar.com/ai-fluency-fra… 3. Introduction to Agent Skills 👉 anthropic.skilljar.com/introduction-t… 4. Building with the Claude API 👉 anthropic.skilljar.com/claude-with-th… 5. Claude Code in Action 👉 anthropic.skilljar.com/claude-code-in… 6. Intro to Model Context Protocol (MCP) 👉 anthropic.skilljar.com/introduction-t… 7. MCP: Advanced Topics 👉 anthropic.skilljar.com/model-context-… 8. AI Fluency for Students 👉 anthropic.skilljar.com/ai-fluency-for… 9. AI Fluency for Educators 👉 anthropic.skilljar.com/ai-fluency-for… 10. Teaching AI Fluency 👉 anthropic.skilljar.com/teaching-ai-fl… 11. AI Fluency for Nonprofits 👉 anthropic.skilljar.com/ai-fluency-for… 12. Claude with Amazon Bedrock 👉 anthropic.skilljar.com/claude-in-amaz… 13. Claude with Google Cloud's Vertex AI 👉 anthropic.skilljar.com/claude-with-go… Follow me @ashiqur_ai for more AI IDEA.


Hermes shows why the agent race is shifting from smarter chatbots to persistent AI operating systems. The real unlock is always on agentic infrastructure, where memory, tools, and specialized agents compound into reusable workflows. Here’s how Hermes is structured at the infrastructure level. — ● What is Hermes Agent? Hermes Agent is an open-source autonomous AI agent framework built by @NousResearch Research, designed to run persistent agents on user-controlled infrastructure. At a high level, its structure looks like this: • Company brain: stores vision, brand, customers, and products as the shared operating context. • Orchestrator Hermes Agent: reads the company brain and routes work to the right department. • Department brains: separate marketing, sales, ops, and support into focused operating layers. • Specialized agents: handle narrow tasks like writing, research, outreach, deployment, and triage. • Docker isolation: each agent runs in its own container, so context does not bleed across workflows. To understand why this matters, the infra stack needs to be broken into 6 layers. — ● Layer 1: Runtime layer Hermes runs on infrastructure users control, which moves agents away from rented SaaS sessions into persistent execution environments. • VPS • Local machine • Docker • SSH • Serverless • GPU workstation This matters because Hermes is not trapped inside a chat window; it becomes a long-running process that can operate 24/7. — ● Layer 2: Memory layer Normal agents depend on temporary context, while Hermes uses persistent memory to carry knowledge across sessions and workflows. • Persona • Preferences • Past work • Project context • User style • Reusable knowledge This is not model training; it is operational learning, where the agent remembers how you work and improves future execution. — ● Layer 3: Skill layer Hermes does not just complete tasks; it can extract reusable skills from completed workflows. Research briefs, @github issues, call summaries, and @discord monitoring can become repeatable procedures over time. Prompt -> task -> result -> skill -> better future task This is the closed learning loop where execution compounds into better future execution. — ● Layer 4: Orchestration layer This is where Hermes starts looking like an AI company, not a single general-purpose agent. Work can move from the company brain to an orchestrator, then into department brains and specialized worker agents. The key design choice is context routing, not context dumping, because each agent only receives the context needed for its task. — ● Layer 5: Isolation layer This is the underrated infra piece, because each Hermes agent can run inside its own Docker container. Marketing, sales, ops, and support can each keep separate context, memory, tools, and permissions. Instead of one giant messy agent brain, Hermes moves closer to microservices architecture for autonomous work. — ● Layer 6: Tool layer This is where Hermes stops being a talking interface and starts becoming an operator. Hermes can connect to: • GitHub for code/issues/PRs • @GoogleWorkspace for @gmail, @googledocs, Sheets, Calendar • @Reddit for market research • @firecrawl for clean web data • @obsdmd for second-brain context • @stripe for revenue intelligence • Discord for community automation • @firefliesai for meeting memory • Graphiti (built by @zep_ai) for knowledge graphs Models give intelligence, tools give agency, and infrastructure gives persistence. — The deeper shift is that AI is moving from prompt-response interfaces into persistent operating systems that can manage state and execution. @ChatGPTapp-style tools behave more like browsers, while Hermes-style infra behaves closer to a backend server for autonomous work. Hermes is not competing with chatbots rather it is competing with the idea that agents should live inside chat windows.
TOP 13 FREE AI COURSES TO TRY IN 2026: 1. Claude 101 👉 anthropic.skilljar.com/claude-101 2. AI Fluency: Frameworks & Foundations 👉 anthropic.skilljar.com/ai-fluency-fra… 3. Introduction to Agent Skills 👉 anthropic.skilljar.com/introduction-t… 4. Building with the Claude API 👉 anthropic.skilljar.com/claude-with-th… 5. Claude Code in Action 👉 anthropic.skilljar.com/claude-code-in… 6. Intro to Model Context Protocol (MCP) 👉 anthropic.skilljar.com/introduction-t… 7. MCP: Advanced Topics 👉 anthropic.skilljar.com/model-context-… 8. AI Fluency for Students 👉 anthropic.skilljar.com/ai-fluency-for… 9. AI Fluency for Educators 👉 anthropic.skilljar.com/ai-fluency-for… 10. Teaching AI Fluency 👉 anthropic.skilljar.com/teaching-ai-fl… 11. AI Fluency for Nonprofits 👉 anthropic.skilljar.com/ai-fluency-for… 12. Claude with Amazon Bedrock 👉 anthropic.skilljar.com/claude-in-amaz… 13. Claude with Google Cloud's Vertex AI 👉 anthropic.skilljar.com/claude-with-go… Follow me @ashiqur_ai for more AI IDEA.







🧠We introduce "Generative Recursive Reasoning"! Recursive Reasoning Models like HRM, TRM, and Looped Transformers are deterministic — same input, same reasoning, every time. They collapse the entire space of plausible reasoning paths into a single attractor. Our model GRAM (Generative Recursive reAsoning Models) turns recursion itself into a stochastic latent trajectory. Multiple hypotheses, alternative solution strategies, and inference-time scaling not just by depth, but by width — parallel trajectory sampling. And here's the kicker: the same formulation that gives us conditional reasoning p(y|x) also makes GRAM a general generative model p(x). With only 10M params: • Sudoku-Extreme: 97.0% (TRM 87.4%) • ARC-AGI-1: 52.0% • ARC-AGI-2: 11.1% • N-Queens coverage: 90%+ 📄 Paper: arxiv.org/abs/2605.19376 🌐 Project page: ahn-ml.github.io/gram-website w/ Junyeob Baek @JunyeobB (KAIST), Mingyu Jo @pyross0000 (KAIST), Minsu Kim @minsuuukim (KAIST & Mila), Mengye Ren @mengyer (NYU), Yoshua Bengio @Yoshua_Bengio (Mila), Sungjin Ahn @SungjinAhn_ (KAIST)
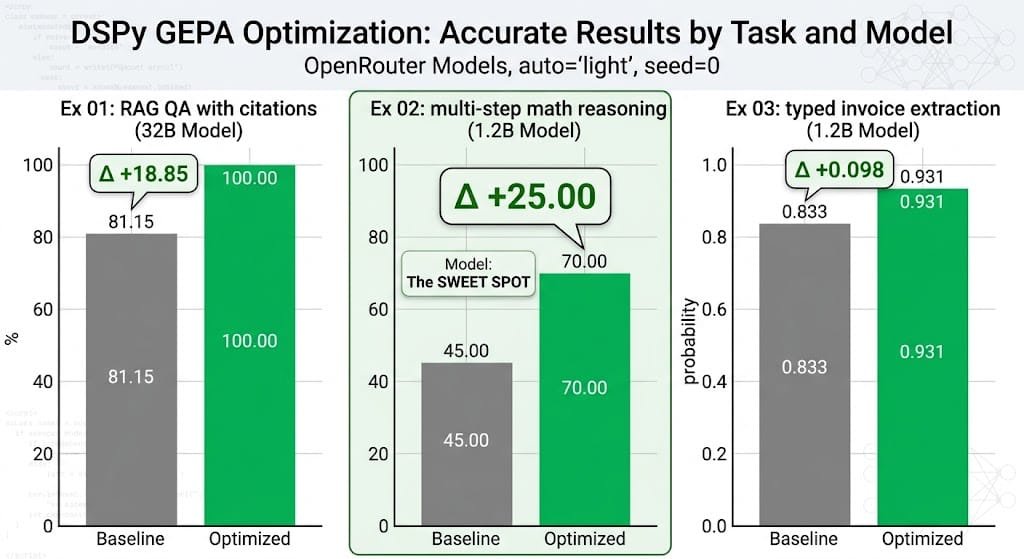
@JeffDean where can we try this? is there a site where you just put a paper name and get this kind of model card? would love to test it properly 🙏


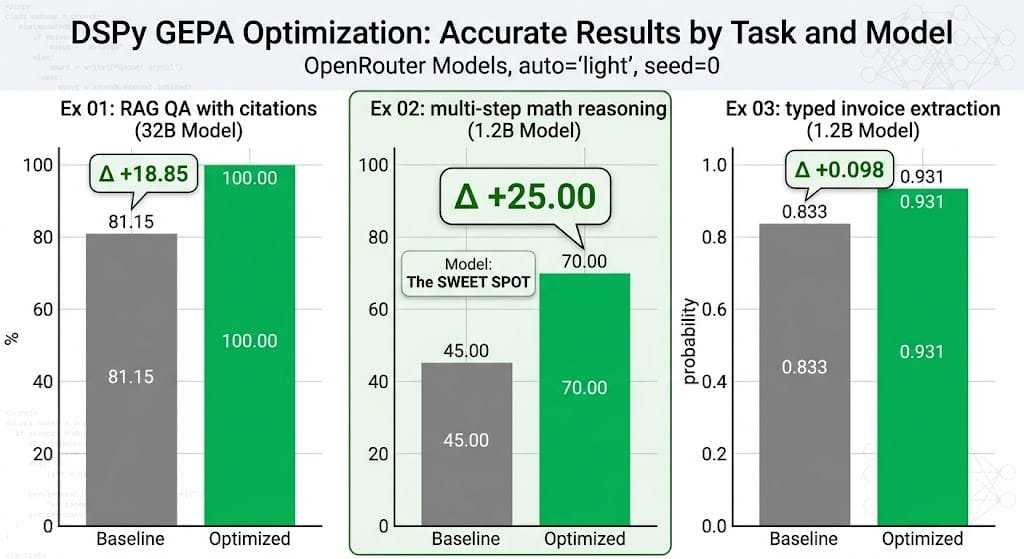
@JeffDean where can we try this? is there a site where you just put a paper name and get this kind of model card? would love to test it properly 🙏



