Sabitlenmiş Tweet

Data centers dominate AI, but they're hitting physical limits. What if the future of AI isn't just bigger data centers, but local intelligence in our hands?
The viability of local AI depends on intelligence efficiency. To measure this, we propose intelligence per watt (IPW): intelligence delivered (capabilities) per unit of power consumed (efficiency).
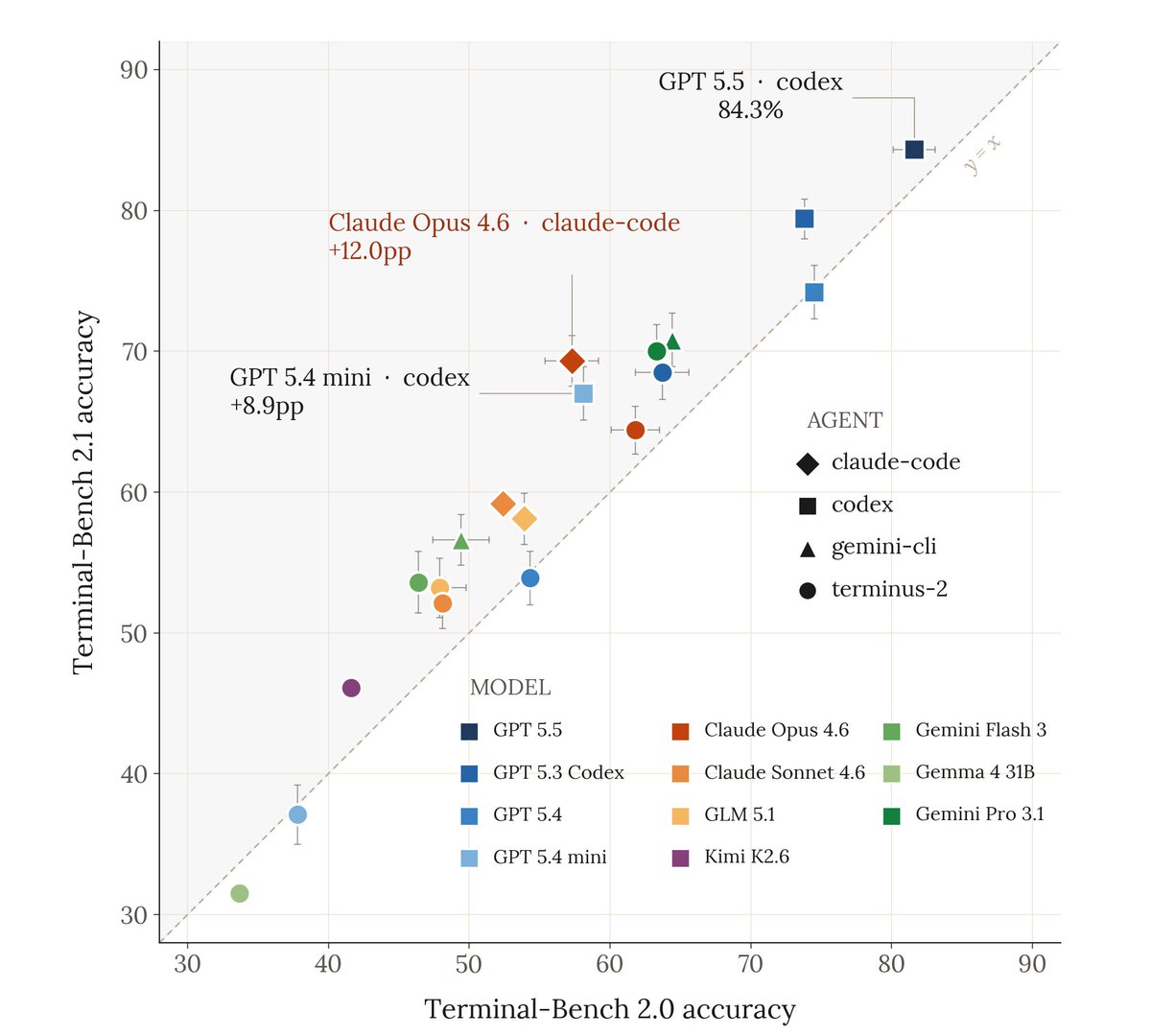
Today’s Local LMs already handle 88.7% of single-turn chat and reasoning queries, with local IPW improving 5.3× in 2 years—driven by better models (3.2×) and better accelerators (1.7×).
As local IPW improves, a meaningful fraction of workloads can shift from centralized infrastructure to local compute, with IPW serving as the critical metric for tracking this transition.
(1/N)

English