Sabitlenmiş Tweet

🤖 early-stage experiment finetuning SmolVLA + RECAP-style advantage signals (inspired on π*0.6 paper) as BC actor + one-step flow actor with AWR on SO100 @LeRobotHF
linkedin.com/feed/update/ur…
previous experiments ACFQL + HIL-SERL
x.com/jpizarrom/stat…
x.com/jpizarrom/stat…
jpizarrom@jpizarrom
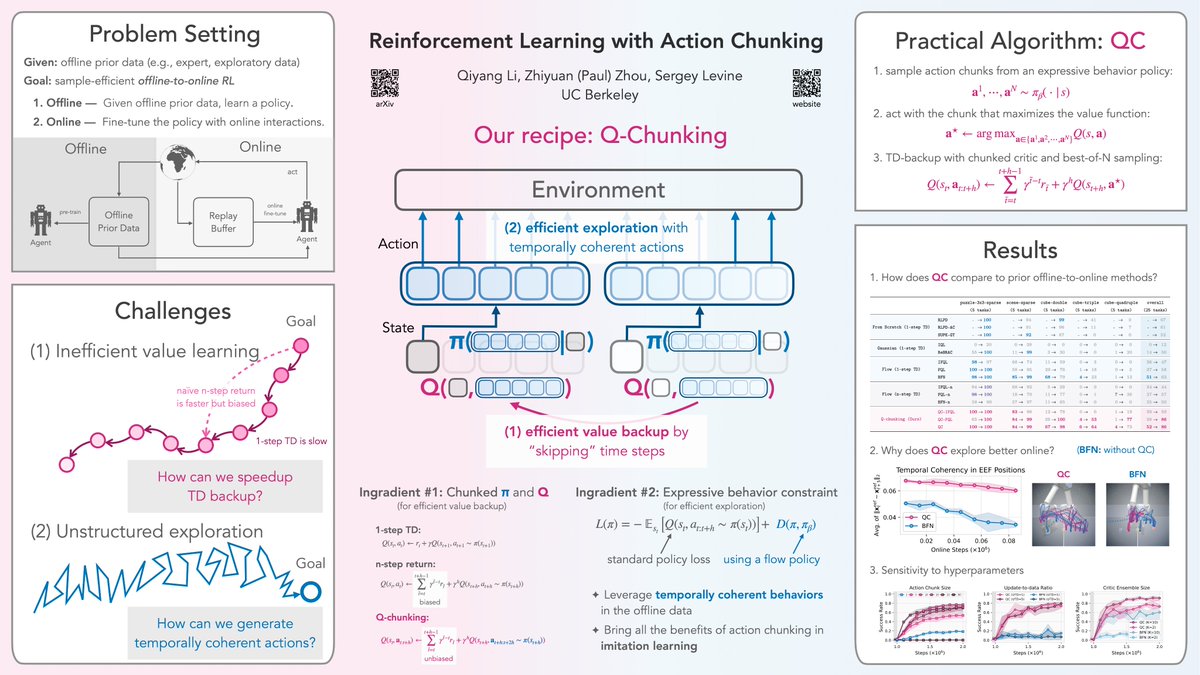
@qiyang_li @zhiyuan_zhou_ @svlevine This policy was trained with ACFQL/QC-FQL on @LeRobotHF @huggingface on top of HIL-SERL github.com/huggingface/le… linkedin.com/posts/jpizarro…
English