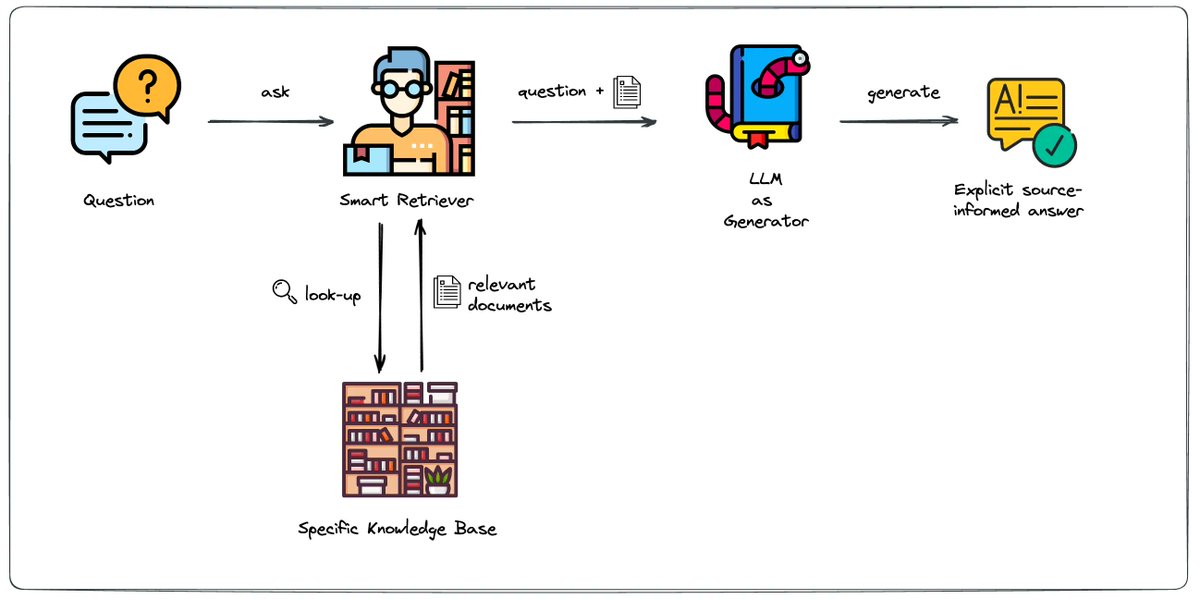
@reliancejio @JioCare I have been struggling to get help for my landline issue with Jio Fiber without any success. My ticket SR000030GVQ9 was closed without any resolution. Now I am unable to reach through any of the listed channels. This is literally my last resort to get help.
English