
Mika Ackermann
2.5K posts
Mika Ackermann
@mikaackermann9
Researcher in disguise. Follow me back.
Katılım Ocak 2022
7.5K Takip Edilen365 Takipçiler

people keep asking what engine i use. no lm studio. no ollama.
i compile llama.cpp from source every time for personal inference. no abstraction layers.
if you're serious about local inference, start at source level. it's a no brainer. here's why.
when you compile from source you control everything. which cuda arch to target. which quantization kernels to enable. flash attention flags. context size limits. you're not waiting for some gui app to update when gguf format changes or a new quant drops. you pull, you build, you run. minutes not days.
lm studio and ollama are fine for trying things. but the moment you need custom context lengths, specific kv cache configs, or hardware specific optimizations like the GB10 tensor cores on my spark those abstractions become walls.
compiling from source means when something breaks you know exactly where. when something is slow you know exactly why. there's no black box between you and the metal.
that's the difference between using local ai and understanding local ai.
Sudo su@sudoingX
i've run a stack of models across a single 3090, a 5090, and a 128GB DGX Spark. exactly three are worth building on. the honest list. the three worth it: > 1. StepFun Step-3.5 Flash, the REAP pruned 121B MoE (Q6, DGX Spark) a 121 billion parameter mixture of experts running on a single desktop box. the most worth-it model in everything i've tested. > 2. Qwen 3.6 27B Dense, Q4 (single RTX 3090) the undisputed king of the 24GB tier. one shot a playable game, around 41 tok/s, fits with context headroom to spare. one 24GB card, this is your answer. > 3. NVIDIA Nemotron 3 Nano Omni, 30B-A3B (DGX Spark) the best multimodal i've tested for video classification work. vision in, runs clean on the Spark. the rest, ran them, they hold up fine: on the Spark: DeepSeek V4 Flash 158B, GLM 4.7 Flash, GLM 4.5 Air REAP 82B-A12B, Gemma 4 26B-A4B, Qwen3-VL 235B-A22B, Qwen3 Coder 30B-A3B, Qwen3 30B-A3B, Carnice 35B-A3B. on consumer GPUs: Kimi K2.5 1T, Qwen3-Coder-Next 80B, Hermes 4.3 36B, Qwen 3.5 27B Dense. single 3090 to a 128GB Spark, that's the range. the three up top are the ones worth your hardware today.
English
Mika Ackermann retweetledi

@flappyairplanes Why not post blog entries on your website?
English

(4/5) One thing we’ve built is a “kittens” virtual machine that takes over the whole GPU and allows new kinds of co-optimization. We can go past the traditional sequential kernel model – for example, fusing entire training runs into a single kernel and even weirder stuff.
English
(1/5) Great to be at @sequoia to give a sneak peek of one of our research directions!
TL;DR one path to data-efficiency may be to “abuse GPUs like they’ve never been abused before”
English
Mika Ackermann retweetledi

My first blog post in over a year is a deep dive on flow maps🗺️, or how to learn the integral of a diffusion model to enable faster sampling and several other cool tricks.
It's the longest one yet👀 Let me know what you think!
sander.ai/2026/05/06/flo…
English
Mika Ackermann retweetledi

From Qubit to Qubit: A Graduate Course in Quantum Mechanics arxiv.org/abs/2605.01585
English
@IterIntellectus He seems to make reasonable assumptions. What do you think is the reason?
English

this is obviously stupidly wrong and no one is being abused by technology or not having children for fear of being recorded
the reason is more complicated and uncomfortable but “technology bad” is easier to sell
Steve Skojec@SteveSkojec
He’s dead on.
English

almost same case but server edition with 11 pcie slots. and 14 fans

Seasonic Japan@SeasonicJapan
最先端のAIワークステーションを支える電源とは、何か。 「十分」では、もう足りない。 重要なAIワークロードが求めるのは、 圧倒的な安定性と、揺るぎない信頼性。 Seasonic PRIMEシリーズは、 新たなAI時代の最前線で、 次世代の高性能コンピューティング環境を支え続けます。
English

@soigomaa @noah_vandal a profoundly disgusting, decadent and modern western thought
the idea that you should feel more grateful bc someone out there has it worse
not only ugly and brain dead, but there isn’t one person in the world that deserves my life more than me on account of it is my life
English

My "Roman Empire is the realization that my life is a lottery win. Somewhere in Sudan, Pålestine, iran, Afghanistan, Iraq or Congo, there is a boy smarter than me. He is more disciplined, more resilient, and holds more potential in his single finger than I do in my entire career.
The only difference? I am siting in a train and he is sting in the rubble of his dreams.
My "bad days" are his wildest dreams.
My "burnout" is a luxury he can't afford because his only job is staying alive.
It's geographical luck and it's a haunting injustice that we all refuse to acknowledge and look away
໊smolaraa@kesikesiluv
Hit me with the harshest reality truth.
English
Mika Ackermann retweetledi

Mika Ackermann retweetledi

I am almost halfway through the semester, and this term I am teaching two heavy courses (60 hours each). One is about cryptanalysis: all the way from classical cryptology of substitution ciphers, through block ciphers, up to post-quantum cryptography.
The second course is a tutorial: a "zero to hero" introduction to neural networks, starting from the classic topics of the 1940s up to the transformer revolution.
I have decided to rely heavily on agentic tools to help me write lecture notes, slides, and interactive applets. It's a very systematic process where I give lectures, do exercises with students, and fine-tune the materials. I have noticed that the boost is incredible. Now we can really dive deep into the topics, adding a lot of custom-made help and examples (full Enigma breaking or high-level implementations in JAX). I see that the students enjoy having such complete notes.
I put a lot of effort into the structure and scaffolding of those notes. Many texts are generated from good sources, but I read every single page and apply corrections. I think I have saved a lot of hours on the tedious fine-tuning of pictures and examples. I also had the courage to test and cover much more experimental content that I had never explored before.
We spend three active hours each week with the students, and the work is very intense. But at the same time, the courses feel very rewarding, and I should admit that I have learned a ton (especially about the classic papers on AI). I will definitely keep building complete lecture notes for future courses, but I already see that the main issue is proper internalization of the knowledge, both by the students and by me. Overall, the process is much smoother because we can always ask an LLM to provide a more accurate answer.


English


Meta's newly released Muse Spark model on Thinking mode achieves a score of 66.7% on the IUMB — a comparable score to Gemini 3 Pro Preview:
#benchmark" target="_blank" rel="nofollow noopener">pellaml.github.io/iumb/#benchmark
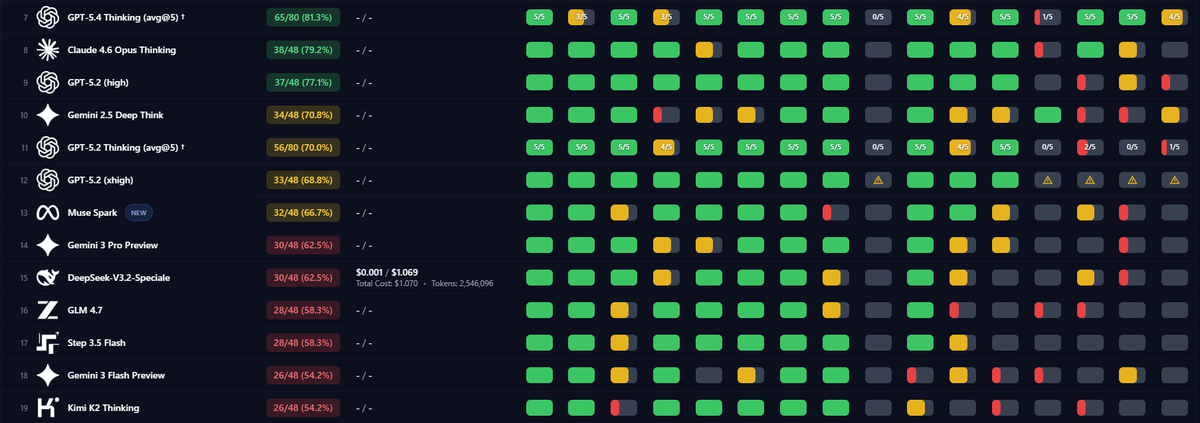
Alexandr Wang@alexandr_wang
1/ today we're releasing muse spark, the first model from MSL. nine months ago we rebuilt our ai stack from scratch. new infrastructure, new architecture, new data pipelines. muse spark is the result of that work, and now it powers meta ai. 🧵
English
@Whateve63092767 @Naturalphilosy Jesus fucking christ. Thanks for sharing.
English



“Practice any art… no matter how well or badly, not to get money and fame, but to experience becoming, to find out what's inside you, to make your soul grow.”
- McKellen reciting Vonnegut
English
@danielhanchen @MatthewBerman @UnslothAI Hi Daniel, I have LLAMA_CACHE setup to a custom folder. How can i pinpoint unsloth studio to recognize this folder for ggufs?
English

@MatthewBerman @UnslothAI Yes! The TCP host / ports must be configured though I used:
ssh.exe" -i key -L 8888:localhost:8888 ubuntu@link
for eg, then port 8888 can be used.
You can then open http://127.0.0.1:8888/ in your browser or in fact anywhere in the world with the correct link!
English

Introducing Unsloth Studio ✨
A new open-source web UI to train and run LLMs.
• Run models locally on Mac, Windows, Linux
• Train 500+ models 2x faster with 70% less VRAM
• Supports GGUF, vision, audio, embedding models
• Auto-create datasets from PDF, CSV, DOCX
• Self-healing tool calling and code execution
• Compare models side by side + export to GGUF
GitHub: github.com/unslothai/unsl…
Blog and Guide: unsloth.ai/docs/new/studio
Available now on Hugging Face, NVIDIA, Docker and Colab.
English
@sudoingX How do you stylize your hermes agent? I like the custom design of yours.
English
this is the worst local ai will ever be. it only gets better from here.
if you are not expanding your mind with these small models you are missing what's happening right now 99 percent tool call success rate. when steered well with the right skills and a framework like hermes agent the node becomes a cognition layer. not a chatbot. not a toy. an extension of how you think.
i was cranking this node at 35 to 50 tok/s all day on personal experiments and now after all the work is done qwen 3.5 9B is iterating on its own code. the game it created. fixing its own bugs autonomously. and the part you should probably not miss is that all of this is happening on a RTX 3060. not an H100. not an A100. the card most of you have sitting in a drawer right now.
if you just open that drawer and put that intelligence to work every tensor core on that card should be running for you. your work. your experiments. your thinking. you all have it but because nobody told you what this hardware can actually do in 2026 you never tried.
the day it unlocks is the day you test your workload, understand the tradeoffs, debug the loops, and then decide if you need to scale the hardware. there is no point buying 3 mac studios when things done well you can squeeze a similar level of intelligence from 9B compared to 70B. but only when you create the right environment for your model through the right harness.
and let me tell you i have tried claude code as a local harness. i have tried opencode. i have tried various others. somehow i landed on hermes agent and never left. there is something magical going on at @NousResearch. the tool call parsers, the skills system, the way it handles small models natively. nothing else comes close for local inference.
own your cognition. your AI. your agent. your prompts. your experiments. why give them away for free. those are who you are and they don't belong on someone else's servers being monitored.
just give it a shot with your existing hardware. you run into a problem the community will help you. and if you are migrating from openclaw to hermes i will personally help you make the switch.
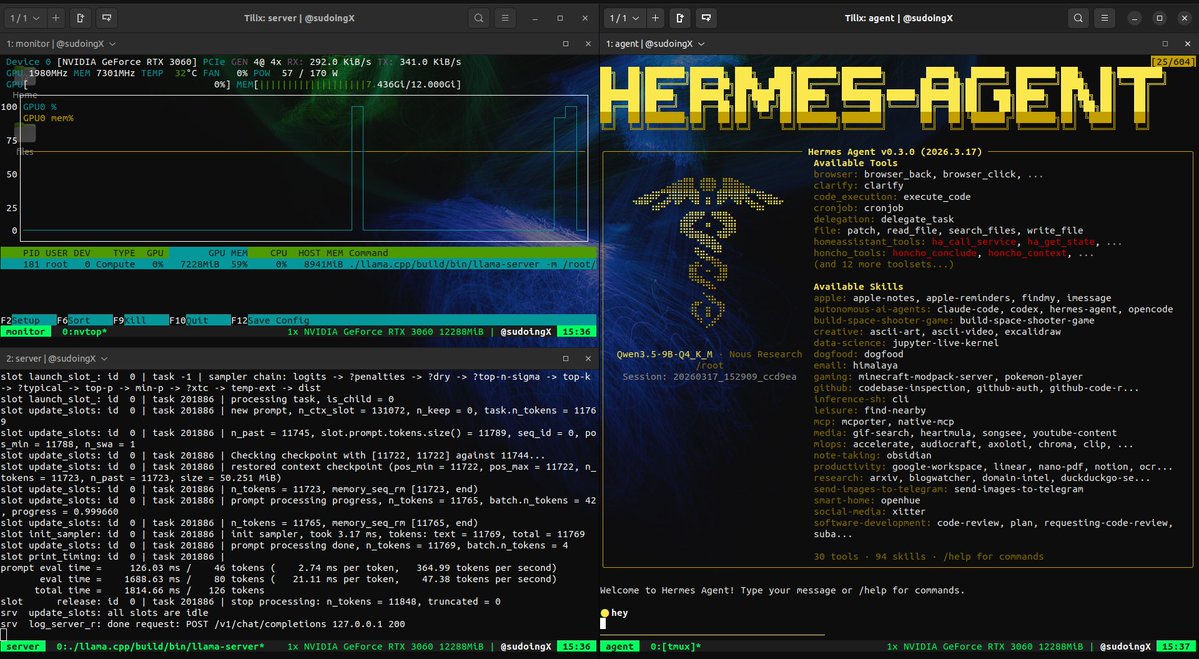

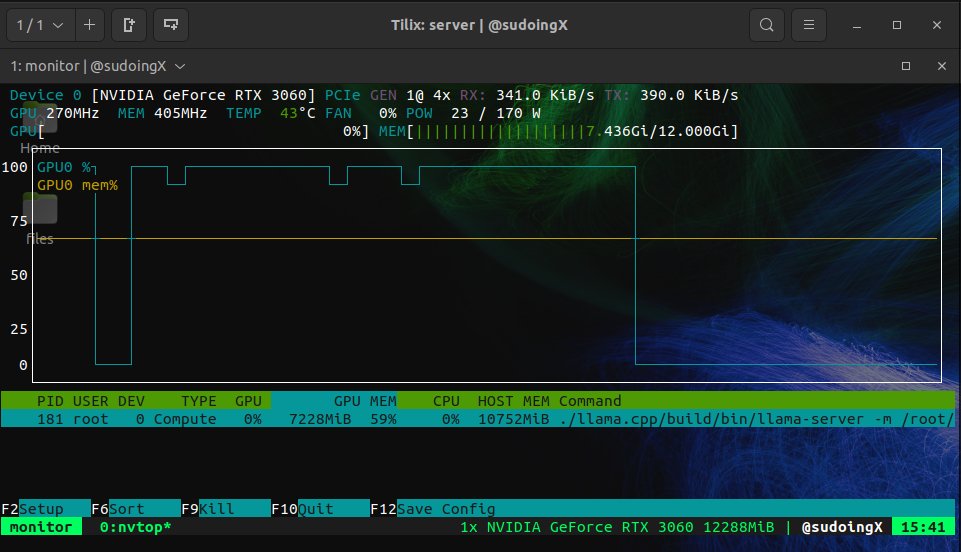
Sudo su@sudoingX
this is what 12 gigs of VRAM built in 2026. a 9 billion parameter model running on a 5 year old RTX 3060 wrote a full space shooter from a single prompt. blank screen on first try. i came back with a bug list and the same model on the same card fixed every issue across 11 files without touching a single line myself. enemies still looked wrong so i pushed another iteration and now the game has pixel art octopi, particle effects, screen shake, projectile physics and a combo system. all running locally on a card that was designed to play fortnite. three iterations. zero cloud. zero API calls. every token generated on hardware sitting under my desk. the model reads its own code, finds what's broken, patches it, validates syntax and restarts the server. i just describe what's wrong and it handles the rest. people are paying monthly subscriptions to type into a browser tab and wait for a server farm to respond. meanwhile a GPU you can find used on ebay is running a full autonomous hermes agent framework with 31 tools, 128K context window and thinking mode generating at 29 tokens per second nonstop. the game still needs work. level upgrades don't trigger and boss fights need tuning. but the fact that i'm iterating on gameplay balance instead of debugging whether the code runs at all tells you where this is headed. every iteration the game gets better on the same hardware. same 12 gigs. same 9 billion parameters. same RTX 3060 from 5 years ago your GPU is not a gaming card anymore. it's a local AI lab that never sends your data anywhere.
English
@Ex0byt Let us experiment with that. Hope you share this with us.
English

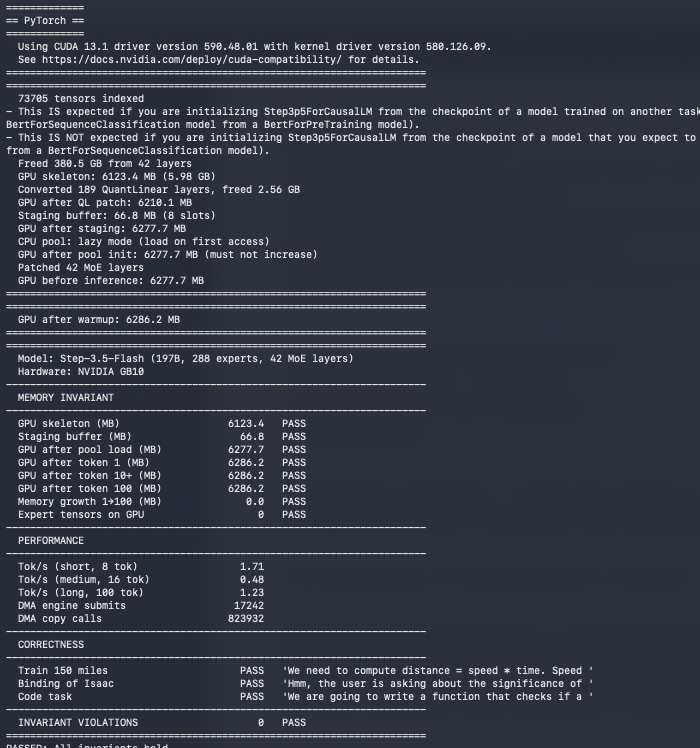
Exciting Experiment Update: We ran StepFun_ai's Step-3.5-Flash (197B MoE) on 6.29 GB of GPU memory!
Flat. Zero growth. Same footprint at token 1 as at token x100.
The model's weights are ~105 GB INT4 (394GB original bf16!). We're running it on 6.29 GB!! — 1/16th the weight footprint, flat across every token.
How:
- Separated expert from non-expert skeleton (6.1 GB) lives permanently on GPU
- 66.8 MB staging buffer — 8 expert slots, overwritten every layer
- 12,096 unique experts (36,288 weight matrices) stay off-GPU until the router selects them
- Router picks. DMA fires. Buffer overwrites. Nothing accumulates.
The invariant held across every token:
- GPU after token 1: 6,286 MB
- GPU after token 100: 6,286 MB
- Delta: 0.0 MB
Correctness: 3/3 PASS — reasoning, religion, coding.
Ceiling: 15.6 tok/s (on my single-GPU hardware).
The architecture is model-agnostic. Any MoE. Any size!
Shoutout to my dude 0xSero. We've been trading notes all week. He's got Kimi K2.5 running across 8×3090s! while we took different journeys on different hardware, we share the same obsession. Amazing collab.
More soon..
English

If you’re asking what to buy, my recommendation based on the budget:
1. RTX PRO 6000
2. RTX 5090
3. RTX 3090 (used, from r/HardwareSwap)
Ahmad@TheAhmadOsman
Life after an RTX 3090 > Life before an RTX 3090 Buy a GPU
English
English

Yes, the 4 Blackhole chips in the TT-QuietBox are designed for exactly this—home AI workloads like running big models locally.
It handles single models up to ~120B params (or multi-model/agent setups with smaller ones accelerated across chips) via its unified mesh and open-source stack.
For a 4-agent Grok 4.20 open-source version: yes, it should work great quantized for inference.
Performance: ~2654 TFLOPS BlockFP8 total.
Unified memory: 128 GB GDDR6 (accelerators) + 256-512 GB DDR5 system—plenty for large multi-agent setups. Check the waitlist for details!
English

72 is actually a small number
@tenstorrent is building big computers. 600 AI processors now, 1000-2000 soon. We program it as one computer. @satyanadella
x.com/satyanadella/s…
Satya Nadella@satyanadella
We’re the first cloud to bring up an NVIDIA Vera Rubin NVL72 system for validation, another big step in building the next generation of AI infrastructure with NVIDIA.
English
@NeelNanda5 @OwainEvans_UK What is special about this? Isn't this basically an direct ouput of the latent spaces from a training corpus?
English

Out of context reasoning is one of the most fascinating developments in the science of how LLMs work. This primer by @OwainEvans_UK, one of the main discoverers of the phenomena, is a great introduction

English