Sabitlenmiş Tweet

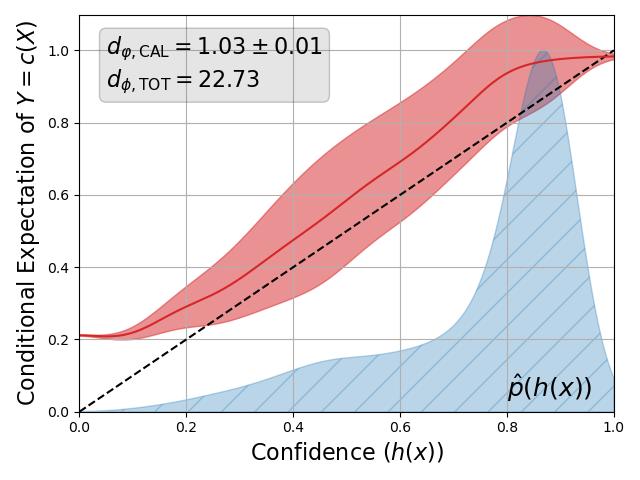
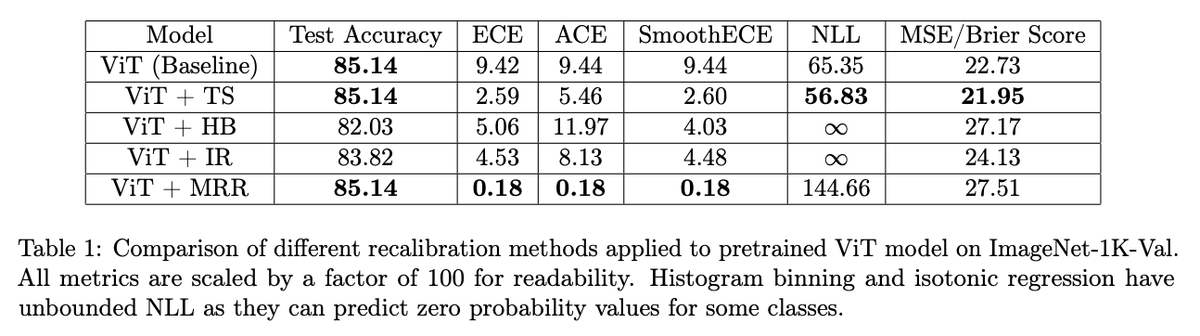
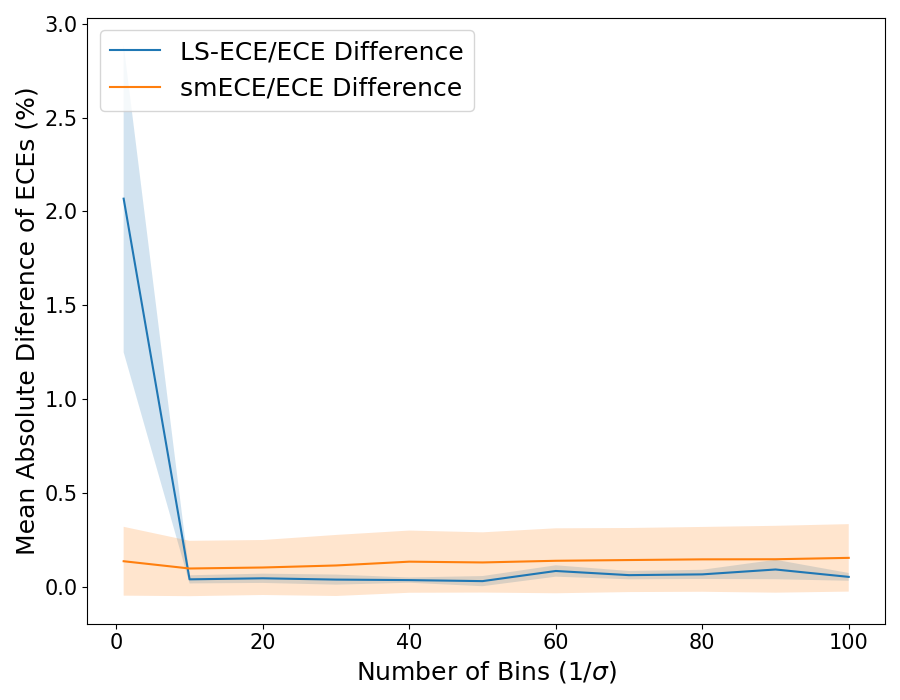
Back with some more work on calibration... This time to tell you that, while ECE (and variants) may be fine, reporting only ECE and accuracy when claiming improvements due to a recalibration method is not. 🧵
Paper: arxiv.org/abs/2406.04068
Code: github.com/2014mchidamb/r…

English