
Mohammed
548 posts


I fully reverse-engineered Ramp's internal AI operating system.
Their system — called Glass — is how they got 99% of their entire company using AI every single day.
350+ reusable workflows.
Every tool connected at first login.
Memory that refreshes every 24 hours.
Automations running while everyone sleeps.
I partnered with my engineering team and we broke down every component inside it.
Then we rebuilt the whole thing for marketing agencies.
76 pages.
Every system.
Every layer.
Every step.
Steal it.
Comment "OS" and I'll send it directly.
Must be a following to receive auto DM
Eric Glyman@eglyman
99% of Ramp uses ai daily. but we noticed most people were stuck — not because the models weren't good enough, but because the setup was too painful and unintuitive for most. terminal configs, mcp servers, everyone figuring it out alone. so we built Glass. every employee gets a fully configured ai workspace on day one — integrations connected via sso, a marketplace of 350+ reusable skills built by colleagues, persistent memory, scheduled automations. when one person on a team figures out a better workflow, everyone on that team gets it and gets more productive. the companies that make every employee effective with ai will compound advantages their competitors can't match. most are waiting for vendors to solve this. we decided to own it.
English
@Johnsjawn how would one go about getting a role like this especially if theyre in the final year of college?
English

Seeing this combo work a few times:
> STEM-like education at some point
> 2-4 early career years in consulting (BCG, Bain, McKinsey) to hone business, system thinking, “gotta grind” chops
> then stints at startups for scrappiness, ethos, innovation, founders exposure therapy
> early adopter of each AI wave out of innate curiosity and understanding this changes everything.
More often seeing former operations pple than PM.
A few titles I’ve seen more than once: Internal AI, AI Ops, AI Enablement, AI Solutions.
Aaron Levie@levie
The more enterprises I talk to about AI agent transformation, the more it’s clear that there is going to be a new type of role in most enterprises going forward. The job is to be the agent deployer and manager in teams. Here’s the rough JD: This person will need to figure out what are the highest leverage set of workflows on a team are (either existing or new ones) where agents can actually drive significantly more value for the team and company. In general, it’s going to be in areas where if you threw compute (in the form of agents) at a task you could either execute it 100X faster or do it 100X more times than before. Examples would be processing orders of magnitude more leads to hand them off to reps with extra customer signal, automating a contracting review and intake process, streamlining a client onboarding process to reduce as many straps as possible, setting up knowledge bases than the whole company taps into, and so on. This person’s job is to figure out what the future state workflow needs to look like to drive this new form of automation, and how to connect up the various existing or new systems in such a way that this can be fulfilled. The gnarly part of the work is mapping structured and unstructured data flows, figuring out the ideal workflow, getting the agent the context it needs to do the work properly, figuring out where the human interfaces with the agent and at what steps, manages evals and reviews after any major model or data change, and runs and manages the agents on an ongoing basis tracking KPIs, and so on. The person must be good at mapping the process and understanding where the value could be unlocked and be relatively technical, and has full autonomy to connect up business systems and drive automation. This means they’re comfortable with skills, MCP, CLIs, and so on, and the company believes it’s safe for them to do so. But also great operationally and at business. It may be an existing person repositioned, or a totally net new person in the company. There will likely need to be one or more of these people on every team, so it’s not a centralized role per se. It may rile up into IT or an AI team, or live in the function and just have checkpoints with a central function. This would also be a fantastic job for next gen hires who are leaning into AI, and are technical, to be able to go into. And for anyone concerned about engineers in the future, this will be an obvious area for these skills as well.
English

Also, I tried making it really easy for non-technical people to actually tinker with this.
Just start Claude Code, and paste this:
--
Hi Claude.
Clone the public git repo /farzaa/clicky.git into my current directory.
Then read the CLAUDE.md. I want to get Clicky running locally on my Mac. Help me set up everything, the Cloudflare Worker with my own API keys, the proxy URLs, and getting it building in Xcode. Walk me through it.
English
Hey, I'm open-sourcing Clicky.
Go forth into the wild and build the future of education and the future of AI interfaces, my friends. I'm happy to have given a spark.
Enjoy!
github.com/farzaa/clicky
Farza 🇵🇰🇺🇸@FarzaTV
I built this thing called Clicky. It's an AI teacher that lives as a buddy next to your cursor. It can see your screen, talk to you, and even point at stuff, kinda like having a real teacher next to you. I've been using it the past few days to learn Davinci Resolve, 10/10.
English
I've been hacking on a product for myself that does this. If interested, hmu!
As you use your computer, it lets you collect inspo (an interesting tweet, a research paper, a screenshot of a page design you like, etc). Then it all gets indexed into an LLM-managed wiki you can chat with.
The more you collect, the better your wiki gets, the better your chats get, the better your ideas potentially get.
Super early and hacky. Started it a few days ago.
DM me if you wanna try it out + plz plz tell me what you'd wanna use it for in your DM! Mac only rn.
(P.S: I am also exploring a version where teams can collect context together. Imagine your whole team's inspo + ideas feeding one AI-backed wiki, and then agents working on top of that 24/7 doing research and analysis to help you guys figure new ideas like a new Notion but not trash if you are on a team and wanna try that lmk)
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English
@MoummarNawafleh how would one act to pass that like the prioritization
English

resumes don't tell you anything about a candidate
our latest screening gives candidates a working codebase with real issues and two lists of priorities, one from the pm and one from the CTO, that don't fully align
they have a fixed time and can't complete everything
we're watching what they prioritize, how they think, how they use AI tools, and how they decide what doesn't get built
midway through we introduce a new variable from the founder and watch how they adapt
that single exercise tells us more than any leetcode screen ever has
English

update: its working
3 claude code agents running simultaneously rn
what it does:
> plan mode that makes tasks given your prompt
> makes tasks and worktrees and runs claude instances
> manages cues of tasks
using tmux for panes as well
comment if u want this to be opensourced
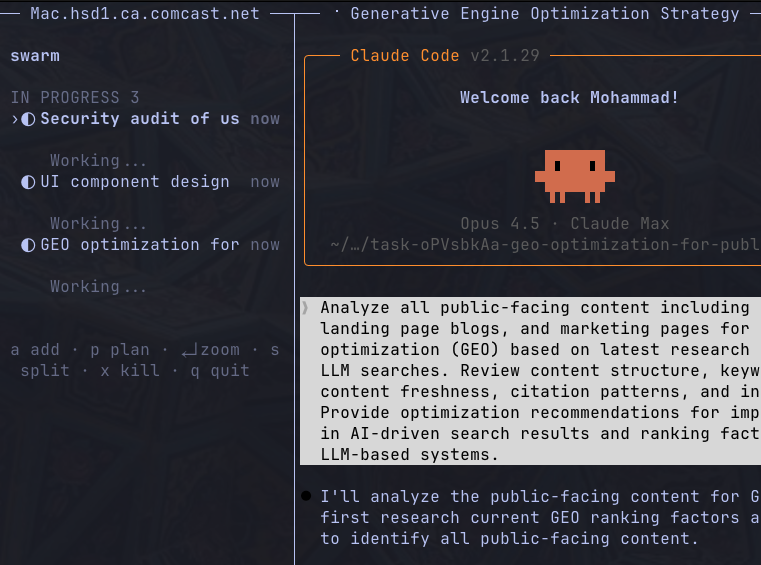
mal@mal_shaik
openclaw keeps breaking on me so i built my own task queue system for claude code u give it a list of tasks and it runs them all simultaneously. reviews when done. basically cursor agent mode (in the image) but for claude code thinking about open sourcing it. would anyone use this?
English
@mal_shaik shoudlve have an eid party together with all of them. eid networking vibes lmaooo
English

@MoummarNawafleh Roger federer, “you can’t pay me to stop” collab with founders David senra, mr beast and Napoleon ones. His way of extracting the best lessons is unmatched imo
English
@MoummarNawafleh @brian_armstrong can you define signals in a bit more depth?
English

Some of our best hires were totally unqualified on paper.
They always had the same qualities: entrepreneurial, high agency, smart, mission aligned, and they got shit done.
If you’re hiring, especially in early stages, seek out & bet on these people. Don’t over-index on resumes.
English
Mohammed retweetledi

We continue to share our brother's recitation.
May Allah s.w grant him the highest degree of paradise, Ameen.!!!
زاكي@zakimze
Blessing ya all ears😊.
English
