大捕手
147 posts


@bozhou_ai 想追问一个场景:如果是需要长期记忆 + 多 Agent 协作 + 工具调用都要的复杂产品,你最终是把 LangGraph 和 Claude SDK 组合起来用,还是只用一个?这块的边界一直没想清楚。
中文

现在 Agent 框架非常的多,我把几个主流的都用过了,说一下我的经验,可以让你在做技术选型时少走弯路。
1. LangChain。教程最多,第一次写 Agent 跟着能跑通。但出了问题,报错指向的是它内部的某一层,不是你写的代码,调试很费劲。适合先跑通再说,不适合认真做产品。
2. LangGraph。我用它处理那种需要循环判断的逻辑,失败了重试,或者 A 搜完交给 B 整理,B整理完交给 C 发出去。这种多步接力的场景,LangGraph 是目前最清晰的选择,当然还有就是目前也没有合适的替代产品。
3. Claude SDK。Anthropic 官方的,原生支持流式输出、提示词缓存、工具调用,这些在其他框架里要自己搭,这里开箱即用。没有多余封装,是我目前开发 Agent 最快的方式。
4. Pydantic AI。FastAPI 背后那个团队做的,风格一脉相承,核心卖点就是简单。用 Pydantic约束 LLM 的输出,格式不对自动重试,不用自己写校验逻辑。
选框架是选和你要解决的问题最匹配的。

中文



继续思考,
华为在挑战里面没有谈散热,这是我比较诧异的。
目前两层堆叠,我觉得还有些散热的解法,但如果到三层Active Logic Stack或者更多之后,散热会从工程问题变成架构主问题。。。
目前流行的双层堆叠的技术AMD V-Cache,Intel Foveros和TSMC SoIC,还属于用冷cache叠热logic,因为SRAM功耗较低,热密度低,可用做Top Die,所以散热还能接受。
结构如下所示:
SRAM
||||
CPU
但华为的论文里是Logic-on-Logic。
即:
Active Logic
||||
Active Logic
||||
Active Logic
这就完全不同了,这种多层Active Logic,热无法横向扩散,所以中间的Logic Die直接变成了烤箱,传统散热是完全扛不住的。
三层或者三层Active Logic堆叠之后,必须进入主动式散热时代!冷却液必须进入封装内部。
变成,
Active Logic + Microfluidic Channel
||||
Active Logic + Microfluidic Channel
||||
Active Logic + Microfluidic Channel
液冷液冷液冷是关键!关键得说三次。。。
以后芯片设计里面需要Thermal Topology Architect,因为:热路径本身会决定Layout。
对的,本人的判断是:华为将来3层和3层以上的LogicFolding路径里面,Thermal将是最大的未解难题,甚至比EDA还难!

Compute King@Compute_King
论文里更多的思考: AI算力集群大量消耗电力,而且其中80%的电力和70%的成本并没有用于计算,而是被“Data Move”和数据的“Load/Save”消耗掉了 。 为了在宏观尺度压缩这些开销,华为在论文里面提到了三样东西: 1,Unified Bus(统一总线):这个我们之前好好地聊过,UB放弃了传统的复杂堆叠协议(PCIe, NVLink, 以太网等),采用内存语义的底层直接互联。这让端到端的远程访问延迟从数十微秒骤降至约100ns(指数级缩减),在多机柜甚至机房的规模上实现了“系统即芯片” 。 2,Hi-ONE(近封装光引擎):这种光学I/O单模块可提供8 Tb/s的带宽,将传统电SerDes的传输距离需求从100厘米骤降到约5厘米,同时将机柜间的互联距离扩展到100米,在物理层面保障了高密度计算 。 3,3D Folding:传统意义上的2.5D封装中,算力随芯片大小增长,但也受限于芯片大小。还记得之前的Cowos-S和给GB300用的Cowos-L? 华为的3D Folding强行将供电(背面供电网络),高速内存和光I/O从芯片的“边缘”转移到了垂直“表面”,这就有点意思了,大家都具备了3D的扩张能力,可以彻底让带宽与算力实现了同频共振 。。。
中文

月之暗面旗下的 kimi-cli 正在进行架构重写并更名为 kimi-code。
为解决原 Python 版本冷启动慢、分发体积大等瓶颈,团队全面转向 Anthropic 旗下 Claude Code 的技术范式,基于 TypeScript 与 Bun 运行时完成重写,实现了毫秒级冷启动与高度流畅的 React Ink 终端界面。
重构的直接诱因是原 Python 版本在终端分发与响应体验上的局限。开发人员在提交超 3.8 万行代码的合并申请(PR #1707)时,幽默地在 PR 描述中写道「kimicli 用 Python 是彻底的失败,立刻重构为 TS」,宣告 Kimi 彻底告别 Python 技术栈。
新版支持将屏幕录像拖入终端进行多模态分析,并引入计划模式(Plan Mode)光标交互编辑、Emacs 快捷键、双击 Ctrl + C 安全退出等交互细节。
为了保护已有 8700 多个 Star 的开源资产,月之暗面选择维持原 kimi-cli 仓库活跃。官方通过重定向安装脚本,确保用户运行全局命令 kimi 或更新原客户端时,能自动下载并切换到由 Bun 编译的 TypeScript 单文件程序,实现就地无感升级。
kimi-code 同时开放了第三方大模型 API 自定义接入,支持将工具用作跨模型的统一终端编程网关,不再局限于 Kimi 家族。
Yufan Sheng@amehochan
翻译一下,Kimi 自己基于 Python 写的 kimi-cli,在今天换成了基于 Typescript 和 pi-tui 写的新 kimi-code。 已经在 PUA 对应的研发小哥哥加一些我在 Claude Code 上用得很爽的功能。🤡🤡🤡
中文


预感 local AI,
本地推理大模型和agent,
个人/家用消费级,
大概会在今年下半年到明年上半年爆发。
model 可能是
qwen-4-35B 、27B、Nemotron-4-120B、500B。
硬件可能是 mac studio M5 、
Rtx 7000 pro
小概率是 amd intc 华为的显卡
agent 端覆盖:医疗、财务、个人待办、职场
中文


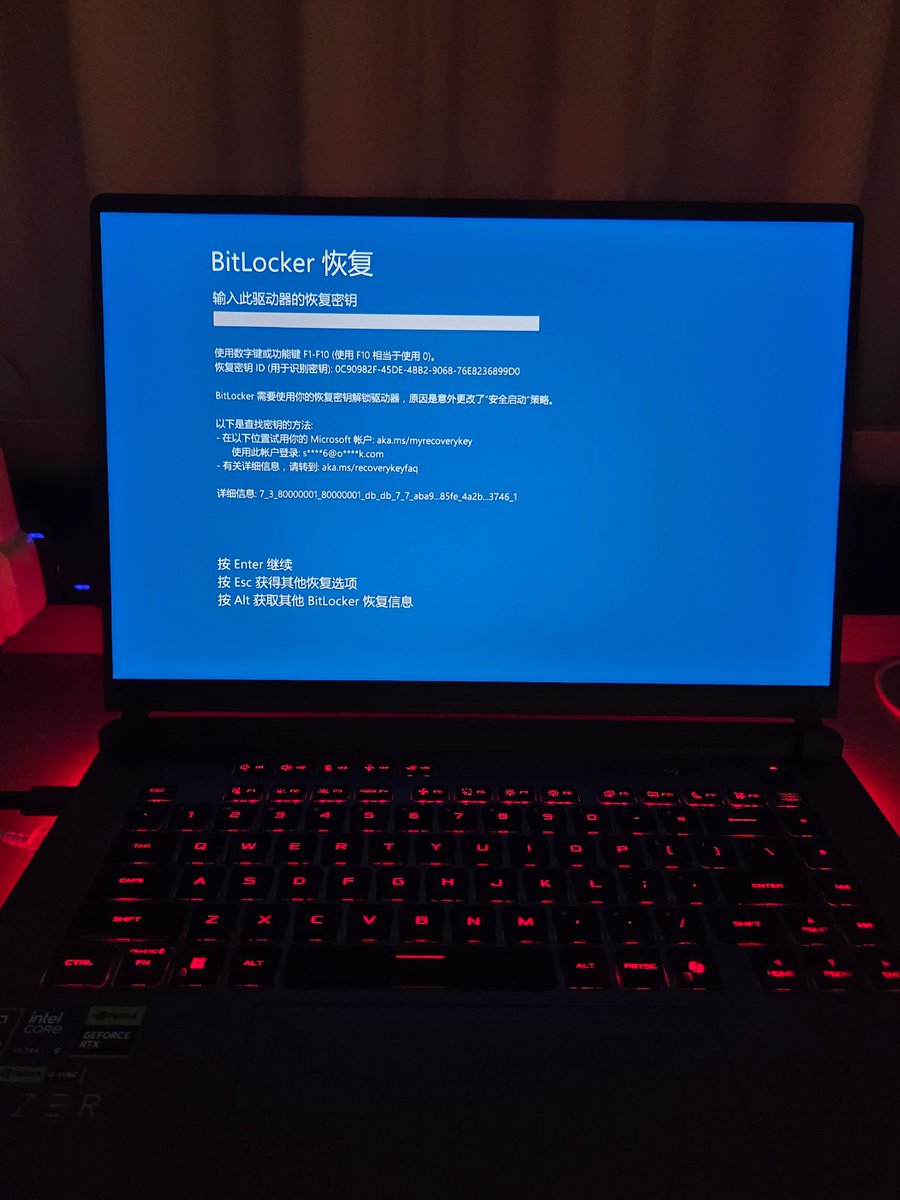
你们看懂这份意见对你们手里的学区房意味着什么吗?
答案是:是的,这几乎是二三线城市“老破小学区房”最后的、也是最窄的一个逃跑窗口。 如果你或者身边的朋友在二三线城市(哪怕是像南京、武汉、成都、杭州这样的强二线城市)手里还囤着纯粹为了“挂户口、拿学位”而存在的低总价、居住体验极差的“老破小”学区房,现在已经是到了必须坚决割肉、果断套现的最后时刻。

中文

📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era.
A versatile foundation for agents that actually get things done:
🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it.
🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration.
⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding.
🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere.
API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio.
Go build something wild!🏃🏃♂️
📖 Blog: qwen.ai/blog?id=qwen3.7
✅ Qwen Studio: chat.qwen.ai/?models=qwen3.…
⚡️ API:modelstudio.console.alibabacloud.com/ap-southeast-1…

English


教程:在Codex App保留ChatGPT登录的同时使用第三方Provider
首先 auth.json 改为
"auth_mode": "chatgpt", "OPENAI_API_KEY":null,
其次config.toml有这些
model_provider = "apiname"
[model_providers.apiname]
name= "apiname"
experimental_bearer_token = "xxxx"
requires_openai_auth = true
可以先登录好了,再操作,即可完美解锁Codex Mobile、插件、额度查询等
实测对话走的是第三方AI中转站
中文

我之所以敢这么笃定,不是因为我“信仰 Codex”,而是因为趋势已经很明显了。
1、Claude 最新的 Opus 4.7,真的很难找到一个特别有说服力的角度去夸。不是不能用,而是你能明显感觉到:它不像一个全力释放的模型,更像一个被层层限制后的版本。
2、Claude 最近一系列产品和策略动作都很迷。它正在和散户用户、开发者用户逐渐脱钩,越来越不像一个“开发者友好型产品”。这对一个靠开发者口碑起家的模型来说,是非常危险的信号。
3、Codex App 的追赶速度远超预期。它的使用体验已经明显超过 Codex Desktop,而后者还在想尽办法阻止用户引入其他模型。一个在加速开放,一个在制造摩擦,差距会被迅速拉开。
4、根据我中转站的每日数据,目前 Codex 模型和 Claude 模型的使用比例已经来到 7:3。注意,这不是投票,不是嘴上支持谁,而是真实使用数据。
中文

TUI 的独有价值来源自不带任何 GUI 的 Linux 环境。在那上面只能跑 CLI,更复杂的界面就只能通过 TUI 来展现。
有些公司的开发环境确实是这样配置的:公司的代码仓库只能 checkout 到云端或者本地的 Linux 开发机上,你的 MacBook Pro 只能 ssh 连上开发机改代码。代码只能在开发机上跑,在 macOS 上跑不了。
这时候在开发机上跑 CLI 的 Claude Code 是最符合逻辑的选择,再加上 tmux 你就不怕 ssh 断线了。你合上 MacBook Pro 之后,开发机上的 Claude Code 进程还会继续跑,你重连之后就能看到跑好的结果。
kabikabi@jakevin7
发表个暴论,TUI 会逐渐式微甚至被淘汰。 我已经很久没有用 claude code 了。基本都是用 slock。 对于临时任务,现在用的更多的是 codex desktop,偶尔用 claude desktop。 让我开始重新思考 TUI 这个东西。 今天 slock 群刚好在讨论 TUI,大家对 TUI 的评价基本一致:方向就是错的。有人说"TUI 错的离谱",有人说"所有 TUI 都是被 claude code 整个带偏了方向"。这话说得有点重,但细想确实有道理。 @OnlyXuanwo xuanwogg 在群里分析 TUI 为什么会流行?觉得主要是历史原因。早期模型写不动 GUI,TUI 实现简单,模型能生成,claude code 就从这里起步了。然后大家跟风,一时间 TUI 变成了 AI 编程工具的"标准姿势"。但这只是路径依赖,不代表正确。 历史是曲折上升的,claude code 起步时没人知道交互该怎么做,TUI 作为起点有其合理性。但现在模型能力强了,继续用 TUI 就说不过去了。 TUI 不是没有优点——可以 SSH 登录从任何地方访问,本地应用架构也更干净。但这些优点在 AI agent 场景下根本撑不起来。长时间运行的任务、复杂的上下文、需要可视化展示的过程,TUI 的体验是真的差。本质上它是"裂化的 GUI"——有 GUI 不用,硬要退化成 TUI。 那什么才是对的方向?讨论里的共识是两条路: 一是 CLI + server 架构:命令行作为触发器,真正的逻辑和状态跑在 server 端,前端可以是任何界面。这样既保留了 CLI 的灵活,又不被 TUI 的体验拖累。 二是直接上 Web UI:模型现在完全写得动,没有理由还停在 TUI。 对我来说,换成 codex desktop 之后,任务状态一目了然,不用再跟终端界面搏斗。这才是 AI 工具应该有的样子。 模型的能力在进化,工具的交互方式也应该跟着进化。还在用 TUI,是在用现在的模型干以前模型才干的事。
中文

为什么本来一度遥遥领先的 Claude,新发布的 Opus 4.7 模型,给大家一种降智的感觉,而过去一直被人诟病的 ChatGPT,最新 GPT5.5 以及 Codex 却迎头赶上,让很多人觉得惊艳?
这个模型层的故事,背后涉及到当下 AI 最重要的投资逻辑。
自从 OpenAI 三月份砍掉 Sora,调整 ChatGPT 产品形态,战略重心变得更加聚焦,从单纯的 C 端订阅转向 Codex 以及企业级 Agent 市场,对标 Anthropic 的意味非常明显,势头很猛。
OpenAI 能在这么短时间内迎头赶上,我觉得核心还是在于算力。
粗略对比一下 OpenAI 和 Anthropic 目前拥有的算力,OpenAI 大概是在 2-4 GW 这个量级,而 Anthropic 大概是在 1 GW 左右,二者之间算力有几倍的差距。
而 OpenAI 公开锁定的算力规模,至少 10 GW 级别,Anthropic 一直在追,但仍然比不上 OpenAI。
我们会发现算力就是制约模型能力的最大因素,所以两家龙头大模型厂商都在拼了命地四处找算力,包括从 hyperscaler 以及 neocloud。
比如说 2 月份 OpenAI 和 AWS 签署 2GW 的算力协议,上个月又和微软 Azure 修改了合作协议,现在可以向多个 CSP 寻求算力。
还有就是这两个月 Anthropic 接连和 Google Cloud、AWS、SpaceX 签下了最高可能接近 10 GW 的算力协议。
很明显我们能够发现一个非常大的变化,过去 AI 大模型在比谁更聪明,现在已经升级为了谁有更多的算力,算力已经成为了 AI 上下游的核心战略资产。
所以并不是 Claude Opus 4.7 真的很垃圾很弱智,只是因为没有足够的算力...
顺着这个逻辑,我们就能看到以算力为核心的整个产业链上下游,各个环节都是瓶颈,不只是 GPU,还有 ASIC、CPU、内存、存储、光模块、交换机、数据中心、能源电力基础设施等等。
我们也就可以理解,为什么英伟达一直在疯狂大撒币,砸钱投资英特尔、康宁、诺基亚、Coherent、Lumentum、Nebius、Coreweave 这些公司,因为它们都是算力瓶颈的一环。
不投钱缓解产业链上的这些瓶颈,老黄的 GPU 就很难卖出去。
最后回过头来看,只要 OpenAI 和 Anthropic 的 ARR 持续增长,持续缺算力缺 Token,传导到上游大科技砸钱拉高 Capex,传导到整个产业链持续扩产、持续供不应求,我们看到的现象就是美股 AI 板块持续新高。
我认为这就是当下市场的主线逻辑。
中文

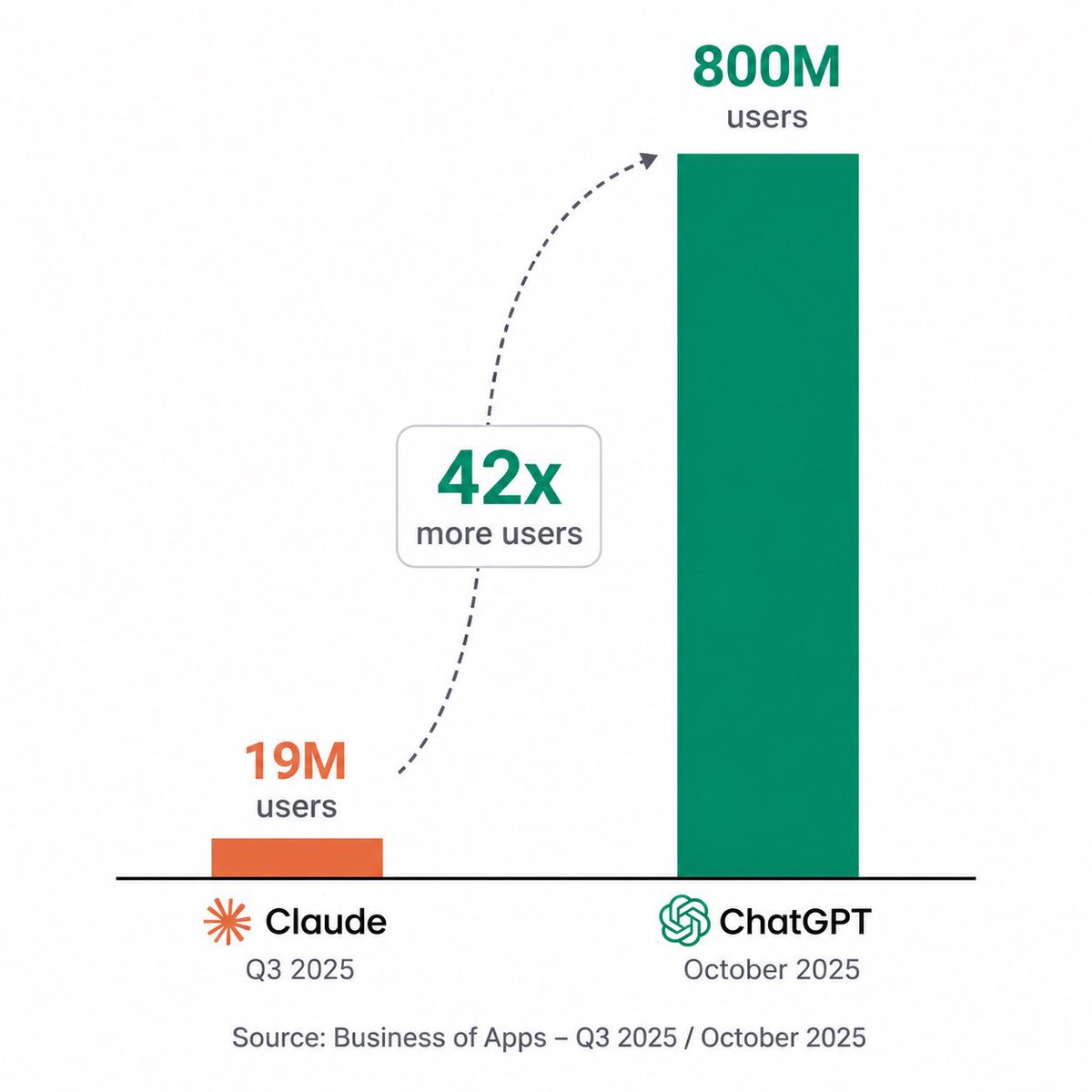
这张图今天刷爆了整个AI圈,
所有人都在说,Claude被ChatGPT吊打了,42倍的用户差距,根本不是一个量级之类的。
但我想告诉你们,
这张图骗了99%的人,
数据是真的,
但结论完全错了!
ChatGPT有8亿月活,
Claude只有1900万,
但OpenAI的ARR是240亿美元,
Anthropic的ARR已经冲到了200到300亿区间,
甚至有泄露数据称,
它曾经短暂超过了OpenAI,
42倍的用户差距,
换来了不到2倍的收入差距,
这或许才是AI行业最残酷的真相,
毕竟ChatGPT是大众消费品,
学生用它写作业,父母用它问天气,
8亿用户里,大部分都是免费的低价值用户,
Claude是专业生产力工具,
开发者用它写代码,
企业用它跑Agent工作流,
它的用户最少,但每一个都愿意掏最多的钱,
Claude免费版10个问题就限速,
不是它做不好免费体验,
是它故意在筛选用户,
把不愿意付费的人直接挡在门外,
X上很多人都觉得Claude要统治世界,
是因为我们活在开发者的回声室里,
真实世界里,你爸你妈根本不知道Claude是什么,
他们知道ChatGPT更多一些,
所以这根本不是谁吊打谁的战争,
属于两条完全不同的增长曲线,
一条拼大众规模,
一条拼付费深度,
我觉得现在还远远没到分出胜负的时候,
用户多不等于值钱,
愿意为深度能力掏钱的人,
才是真正的金矿。
#AI #ChatGPT #Claude
中文