Sabitlenmiş Tweet

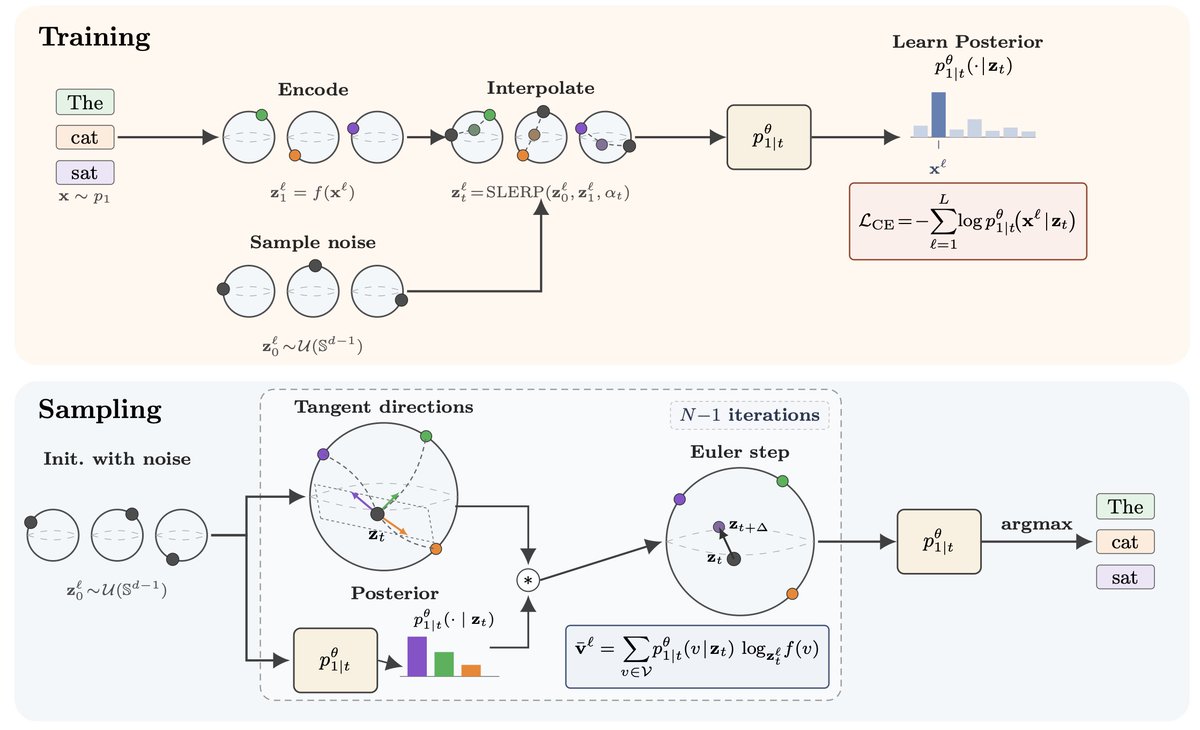
Diffusion world models can help test and improve robot policies before running them on real robots.
But can the choice of latent space make the WM more faithful?
We show that semantic spaces beat reconstruction spaces on task relevant metrics.
hskalin.github.io/semantic-wm
English