az
9 posts


Nice dude🤣🤣
Exchanging the latest research ideas and progress on X is honestly pretty fascinating haha. Always happy to chat more!
People have mentioned me in discussions before too. Feel free to come say hi at ICML (even though I’m socially awkward in real life😭)
az@probablynotaz9
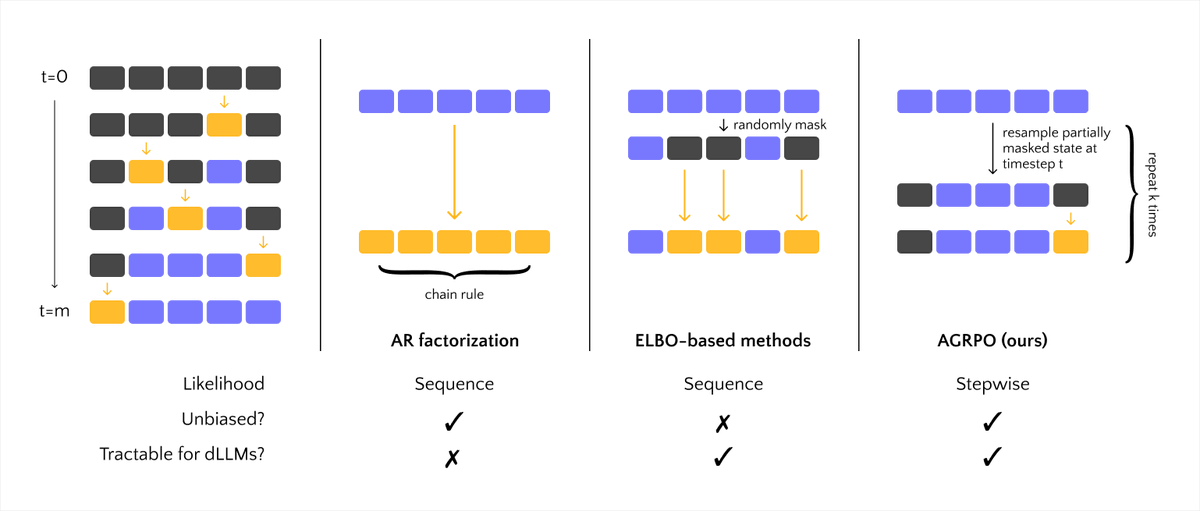
🚨 Solo-author ICML paper alert 🤫 Ever wanted to post-train your diffusion LLM with good old policy gradients, without having to deal with ELBOs or surrogates? In Simple Policy Gradients for Reasoning with Diffusion Language Models, we show how to make this tractable in a straightforward way. Our framework, Amortized GRPO (AGRPO), lets the model learn from unbiased PG updates via timestep estimation, naturally aligning with dLLM inference while remaining efficient + scalable. Paper: arxiv.org/abs/2510.04019 Code: github.com/probablyabot/a… 1/n
English
Check out the full paper for more details, like variance reduction with entropy importance sampling and GPU memory optimizations.
Shoutout to @jiaqihan99, @aaron_lou, and @michaelyli__ for valuable feedback during the early stages, @therealgabeguo and @StefanoErmon for supporting this project throughout, as well as @modal for sponsoring compute!
6/n
English
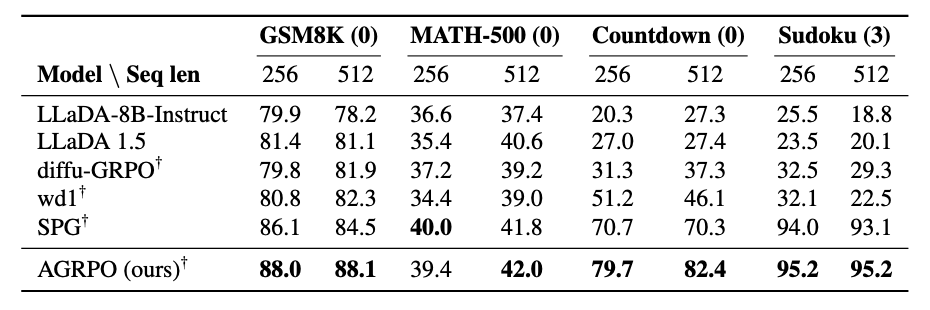
Empirically, with only k=24 MC samples, AGRPO surpasses every comparable ELBO-based RL method across four reasoning tasks: GSM8K, MATH, Countdown, and Sudoku. These gains persist even for different context lengths and # of denoising steps (m) than what the model was trained on.
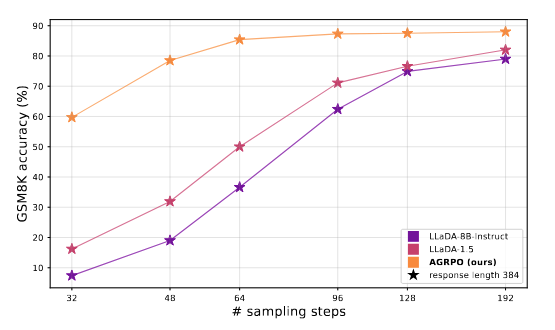
A neat dLLM-specific result is that post-training completely changes the inference speed/quality frontier: AGRPO lets you achieve the same quality as the base LLaDA model with 4x fewer steps.
In the real world, if you're serving a model to users, this would let you drastically cut inference costs by amortizing that cost into training.
5/n
English
🚨 Solo-author ICML paper alert 🤫
Ever wanted to post-train your diffusion LLM with good old policy gradients, without having to deal with ELBOs or surrogates?
In Simple Policy Gradients for Reasoning with Diffusion Language Models, we show how to make this tractable in a straightforward way.
Our framework, Amortized GRPO (AGRPO), lets the model learn from unbiased PG updates via timestep estimation, naturally aligning with dLLM inference while remaining efficient + scalable.
Paper: arxiv.org/abs/2510.04019
Code: github.com/probablyabot/a…
1/n
English
az retweetledi

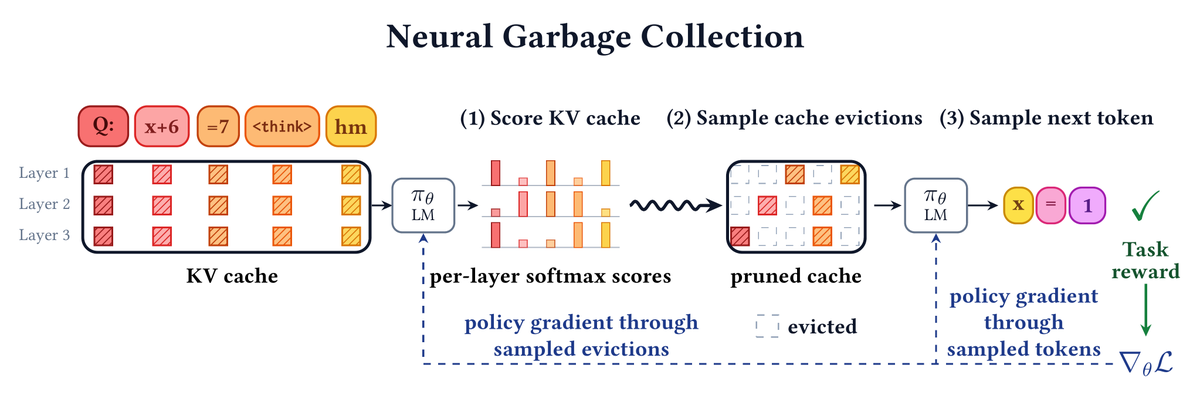
Can a language model learn, end-to-end, what to keep in its own KV cache and what to throw away? Can it learn to forget while it learns to reason?
Deep learning's central lesson: capability emerges from end-to-end optimization, not heuristics/strong inductive biases. But for efficiency, we rely heavily on hand-designed approaches.
🗑️ Introducing Neural Garbage Collection (NGC): we train a language model to jointly reason and manage its own KV cache, using reinforcement learning with outcome-based task reward alone. No SFT, no proxy objectives, no summarization in natural language.
New paper with @jubayer_hamid, Emily Fox, and @noahdgoodman!
English
az retweetledi

I want there to be a nanoGPT style speedrunning setup for RL.
English