
Henrick
357 posts


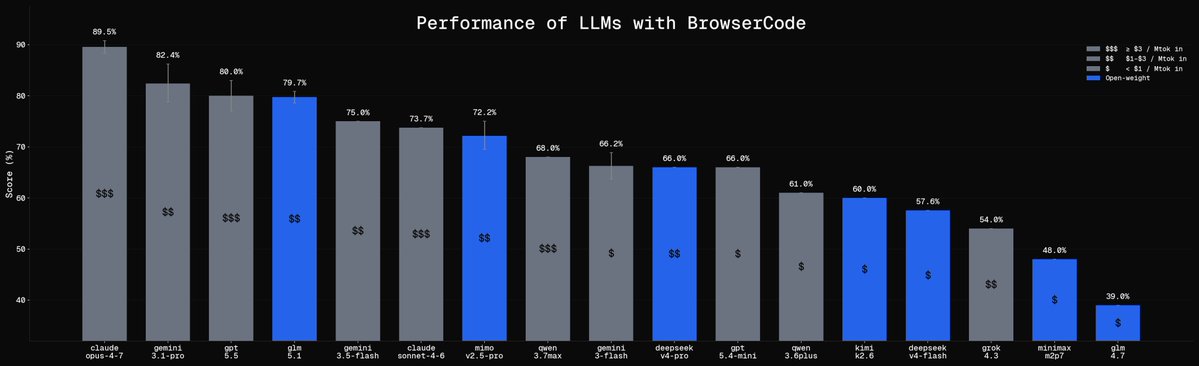
For Browser tasks, Qwen 3.7 max is a +15% improvement over Qwen 3.6 plus. Now matching gemini-3-flash and mimo 2.5 pro.
However without caching it is more expensive than Opus 4.7!
Even with caching setup, I would still recommend GLM 5.1 or Gemini 3.1 pro at this tier
English

lets go🚀
OpenRouter@OpenRouter
The new Qwen3.7-Max from @Alibaba_Qwen is live on OpenRouter. The flagship of the Qwen3.7 series, built for agent-centric work: coding, office and productivity tasks, and long-horizon autonomous execution. Big jumps in coding and agent benchmarks over Qwen3.6, with explicit prompt caching for repeated context.
English

We are making our discount permanent! 🎉
Enjoy building with DeepSeek-V4-Pro and bring your innovative ideas to life! 🚀

DeepSeek@deepseek_ai
The DeepSeek-V4-Pro discount has been extended until May 31, 2026, 15:59 UTC!
English

I made a research about new Alibaba frontier model and I am SHOCKED. Qwen 3.7 - Max is the greatest model now. Switch all my agents over to it..
atomic.chat@atomic_chat_hq
Qwen 3.7-max beats Opus 4.7 and GPT-5.5 We tested three frontier models on a real agentic task: write a Tetris bot that plays the game and trains itself. Each model could read its own code, run benchmarks, and rewrite itself across 10 iterations. Then we compared the final bots head to head. Qwen 3.7-Max: training cost $1.32, bot improvement +56% Claude Opus 4.7: training cost $12.15, bot improvement +28% GPT-5.5: training cost $2.85, bot improvement +7% Qwen won on every dimension - biggest jump, 9× cheaper than Claude, 2× cheaper than GPT. Long agentic loops is where Qwen Max actually delivers.
English
@OfficialLoganK @mercor_ai And way more expensive. I miss 3 flash pricing...
English

Gemini 3.5 Flash ranks #1 on the APEX-Agents-AA benchmark, outperforming much larger models a whole size above it.

English

@ChujieZheng Anyone knows how prices looking for 1m token in/out?
English

Qwen3.7-Max is our best flagship model built for real-world tasks and production environments. Try it and hope you enjoy!
Qwen@Alibaba_Qwen
📣Meet Qwen3.7-Max — our latest flagship, made for the Agent Era. A versatile foundation for agents that actually get things done: 🧑💻 Coding agent, end to end. Frontend prototypes, multi-file refactors, real debugging — nails it. 🗂️ A reliable office and productivity assistant. Get your work done through MCP integrations and multi-agent orchestration. ⏱️ Long-horizon autonomy. 35 hours straight on a kernel optimization task — 1,000+ tool calls, zero hand-holding. 🔌 Scaffold-agnostic. Claude Code, OpenClaw, Qwen Code, or your own stack. Consistent reliability everywhere. API's up on Alibaba Model Studio. You can also take it for a spin on Qwen Studio. Go build something wild!🏃🏃♂️ 📖 Blog: qwen.ai/blog?id=qwen3.7 ✅ Qwen Studio: chat.qwen.ai/?models=qwen3.… ⚡️ API:modelstudio.console.alibabacloud.com/ap-southeast-1…
English
@ChujieZheng When 3.7 Plus or 3.7 Max with image/video support?? :'(
English
@ChujieZheng When on API? And do Plus version have image input support??
English
For Qwen3.7-Max, we have invested far more compute into RL training than ever before. Its top-tier AA score confirms the resulting general and agentic capabilities.
This is just the start. We will firmly push forward RL scaling to build more powerful Qwen models. Stay tuned!
Artificial Analysis@ArtificialAnlys
Alibaba’s new Qwen3.7 Max model scores 56.6 on the Artificial Analysis Intelligence Index, 4.8 points higher than Qwen3.6 Max Preview (51.8). While Alibaba still trails models from OpenAI, Anthropic and Google, Qwen3.7 Max is the closest they have been to the frontier Qwen3.7 Max is @Alibaba_Qwen's latest proprietary flagship, scoring 56.6 on the Intelligence Index, a 4.8 point gain over Qwen3.6 Max Preview (51.8) released in April. Qwen3.7 Max continues Alibaba's pattern, in place since Qwen2.5 Max (January 2025), of releasing Max and Plus models as closed weights while the rest of the Qwen line remains open weights. The leading open weights Qwen on the Intelligence Index is Qwen3.6 27B (Reasoning, 45.8) released in April 2026, and the leading open weights MoE Qwen is Qwen3.5 397B A17B (Reasoning, 45.0) released in February 2026 Key takeaways for the reasoning variant: ➤ The Intelligence Index gains over Qwen3.6 Max Preview are concentrated in scientific reasoning, agentic capability and coding. CritPt +9.7 p.p (3.7% to 13.4%), HLE +9.2 p.p (28.9% to 38.1%), TerminalBench Hard +6.9 p.p (43.9% to 50.8%) and GDPval-AA +42 Elo (1504 to 1546). Scores on other benchmarks in the Intelligence Index are flat compared to Qwen3.6 Max Preview ➤ A significant share of the Intelligence Index gain is driven by higher abstention on AA-Omniscience, not higher accuracy. Qwen3.7 Max's accuracy on AA-Omniscience dropped 7.6 p.p (37.7% to 30.1%), while its hallucination rate dropped 21.3 p.p (44.2% to 22.9%). The model is choosing not to answer more questions rather than recalling more facts. Because hallucination rate and accuracy both feed into the Intelligence Index, the hallucination reduction is one of the larger single contributors to the +4.8 point gain on the Intelligence Index ➤ Qwen3.7 Max used 96.7M output tokens to run the Intelligence Index, ~31% more than Qwen3.6 Max Preview (73.9M). It sits mid-pack on frontier token usage: above GPT-5.5 (high, 44.5M) and Gemini 3.1 Pro Preview (57.3M), below Claude Opus 4.7 (Adaptive Reasoning, Max Effort, 112M), Kimi K2.6 (166M) and DeepSeek V4 Pro (Reasoning, Max Effort, 187M) Key model details: ➤ Context window: 1M tokens (up from 256K on Qwen3.6 Max Preview) ➤ Multimodality: Text input and output only ➤ Pricing: Yet to be announced (Qwen3.6 Max Preview is priced at $1.30/$7.80 per 1M input/output tokens on the @alibaba_cloud first-party API) ➤ Licensing: Proprietary, closed weights
English


it's important, i think, to resist the temptation to ship garbage
English


Cohere launches open weights model Command A+ that achieves 37 on the Artificial Analysis Intelligence Index
The release of Command A+ places @Cohere in line with Claude 4.5 Haiku on the Intelligence Index, and just above NVIDIA Nemotron 3 Super and Gemini 3.1 Flash-Lite.
Key Takeaways:
➤ Command A+ ranks first on AA-Omniscience Non-Hallucination at 86%, ~3 percentage points ahead of the next-best model. Its AA-Omniscience Accuracy is 9%, so the headline AA-Omniscience score lands at -4, demonstrating a similar archetype to Claude 4.5 Haiku, where the model knows its limits
➤ On Cohere’s API, Command A+ (~281 output tokens per second) is faster than several comparable open-weights and small to mid-sized proprietary models (e.g., GPT-5.4 nano, Claude 4.5 Haiku, and Grok 4.3), but still slower than Gemini 3.1 Flash-Lite Preview, which outputs 304 tokens per second
➤ Command A+ trails its peer set on scientific reasoning (HLE ~11%, GPQA Diamond ~76%) and on coding (Terminal-Bench Hard ~25%, SciCode ~38%), consistent with gaps on the hardest science and agentic coding benchmarks
➤ It supports visual reasoning and scores 63% on MMMU-Pro (between Claude 4.5 Haiku at 59% and GPT-5.4 nano (xhigh) at 65%)

English
One more thing 🚀
Qwen’s agentic capability is no longer limited to the digital world — we’re bringing it into physical world.
With our in-house robotic agentic system and navigation model, Qwen can now control a robot to execute tasks in real-world.
#qwen #embodied #robotics
xiong-hui (barry) chen@xiong_hui_chen
our qwen 3.7 max is released, try our best toward agentic frontier🚀 qwen.ai/blog?id=qwen3.7 #qwen
English

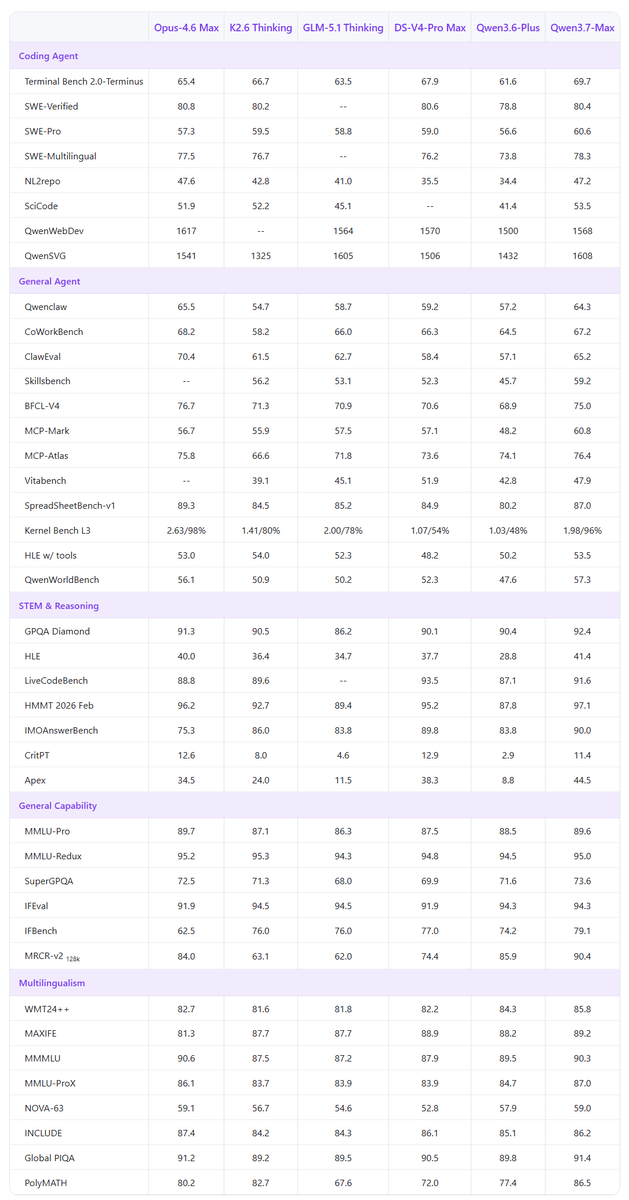
🚨 Qwen3.7-Max benchmarks finally appeared and signals a "code-red" for @AnthropicAI.
📊 Qwen3.7 Opus-4.6 Max in 57% (24 out of 42) of comparable benchmarks, with large leads in several key areas:
IMOAnswerBench: 90.0 vs 75.3
Apex: 44.5 vs 34.5
IFBench: 79.1 vs 62.5
MRCR-v2 128k: 90.4 vs 84.0
PolyMATH: 86.5 vs 80.2
It scores particularly strong in STEM reasoning, instruction following, long-context understanding, and multilingual tasks.
Qwen models are very good and seems are no longer just competitive but they’re pulling ahead in multiple domains. 🔥
English

@eixopolitico Curiosamente esses 20% serão os mais milionários/bilionários da turma
Português

🇺🇸 Harvard aprova limite de notas máximas na instituição: professores agora só podem dar "A" para, no máximo, 20% dos alunos por turma.
A medida tenta conter uma suposta "inflação de notas" na universidade, onde 2 em cada 3 notas foram "A" em 2024, contra apenas 35% em 2012.

Português
@AQUELECARA @grok qual foi o desfecho dessa história pós essa cena?
Português

English

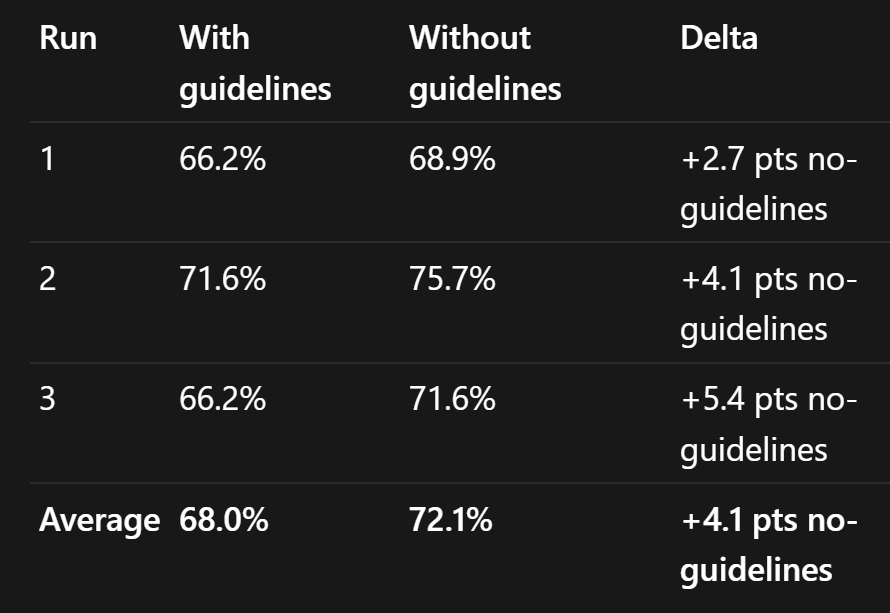
Suuuuper wierd results with the new @GeminiApp 3.5 Flash model and the @convex evals.
For the first time across 100+ models I have seen the model consistantly do WORSE when given the guidelines?!
I have no idea whats going on here?!

English
our qwen 3.7 max is released, try our best toward agentic frontier🚀
qwen.ai/blog?id=qwen3.7
#qwen

English

Qwen3.7-Max IS OUT🚀
In 35h autonomous core tests with 1000+ tool calls, it maintained coherent reasoning, achieved a 10× speedup.
It can:
Build frontend prototypes+ complex multi-file projects
Automate workflows with MCP+ multi-agent collaboration
Support mainstream frameworks

English

