Sabitlenmiş Tweet

🚨New time series generative model just dropped.
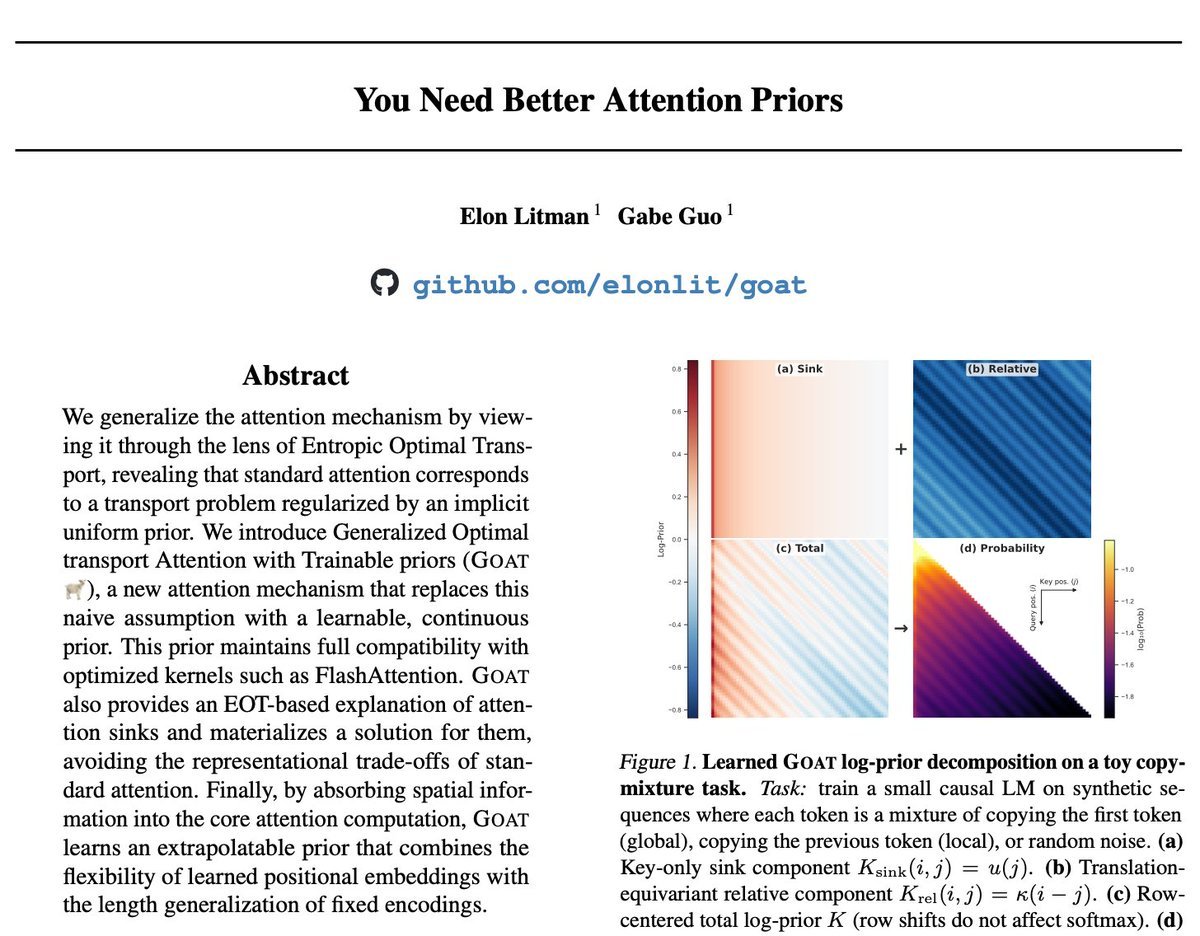
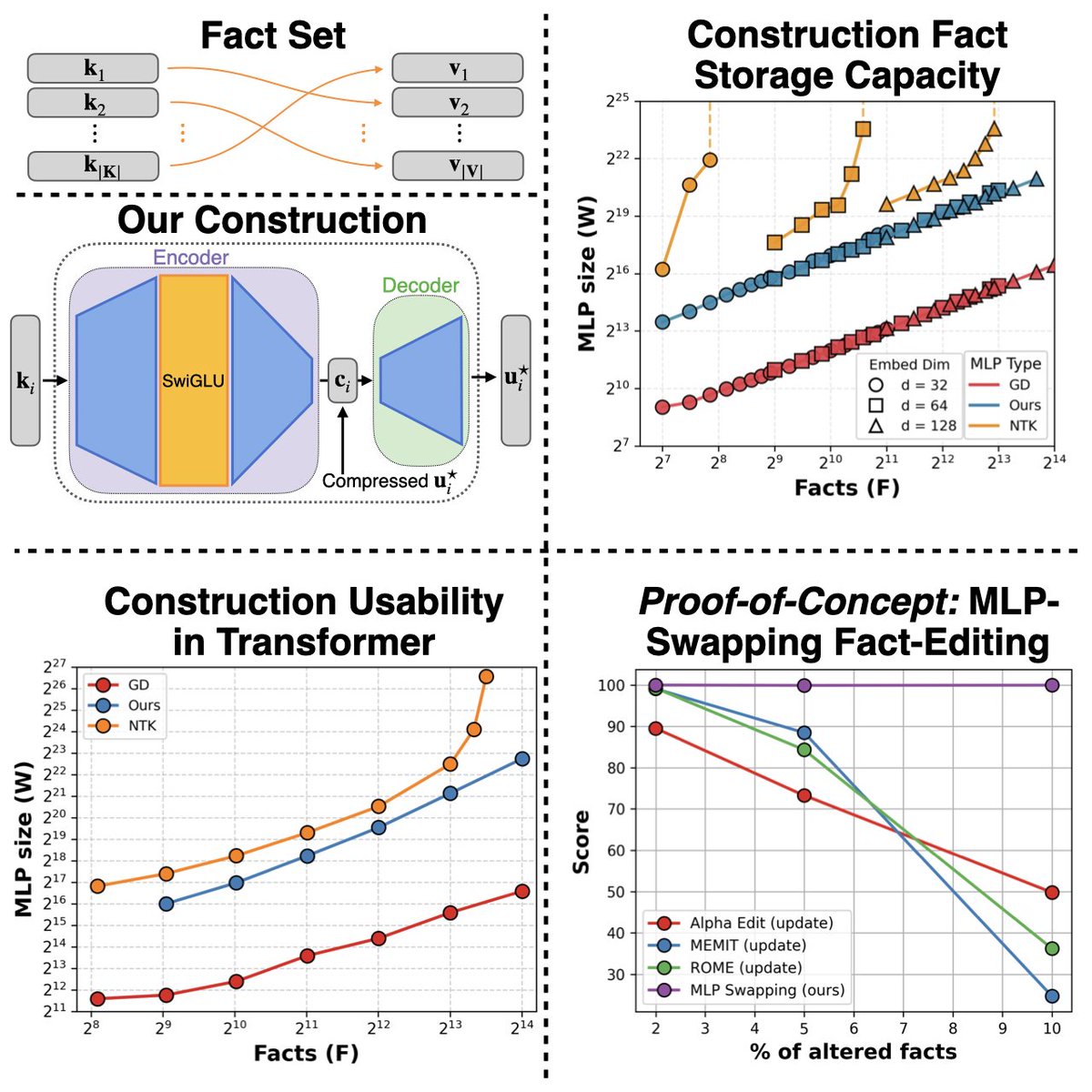
Paper: arxiv.org/abs/2604.27443
Demo: abc-diffusion.github.io
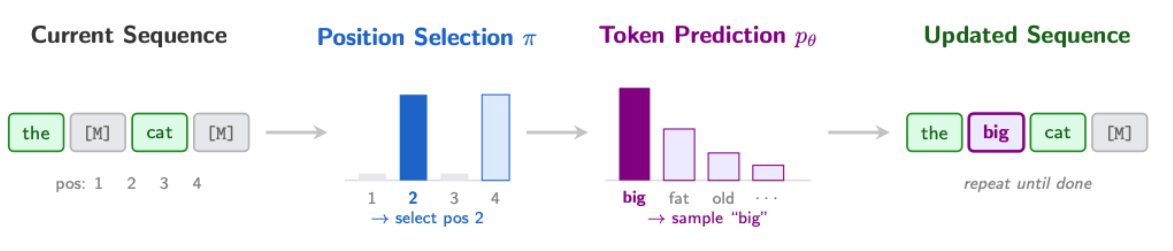
⏰Meet ABC: Any-Subset Autoregressive Diffusion Bridges in Continuous Time & Space.
With @StefanoErmon @elon_lit @Jose_Blanchet @thanawatsornwan @lutong_hao
English