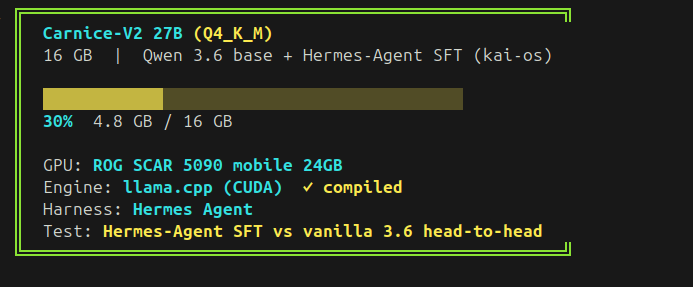
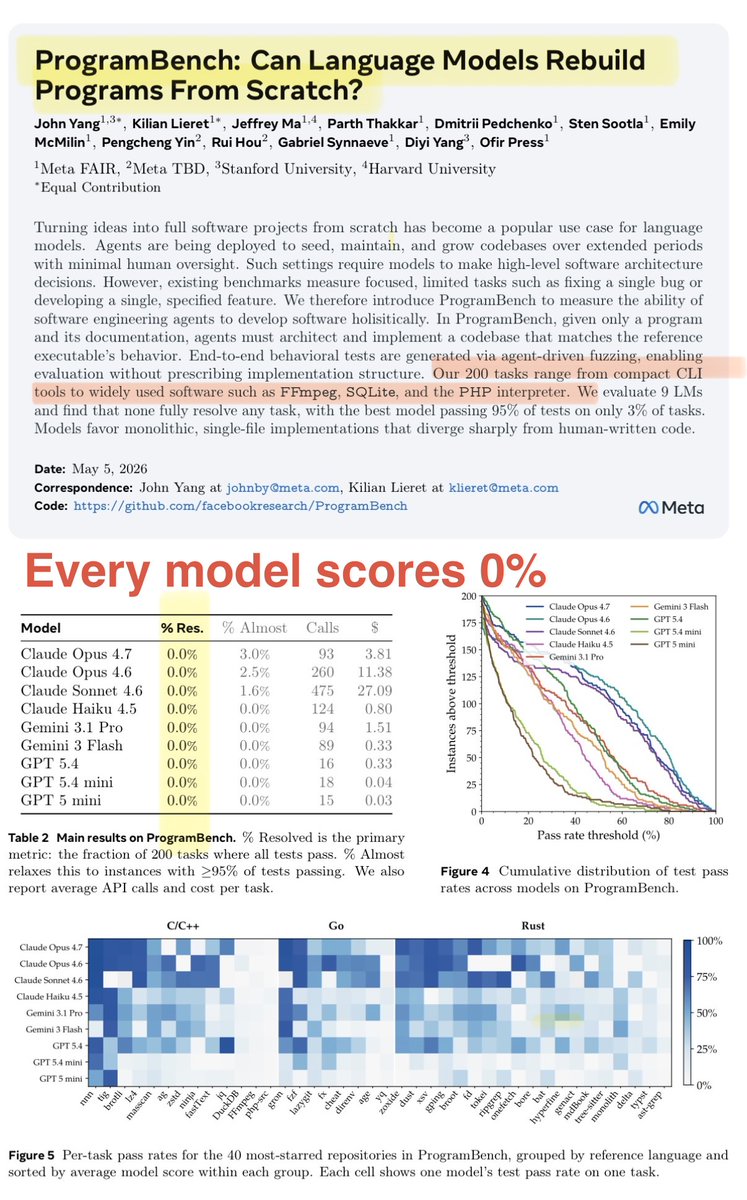
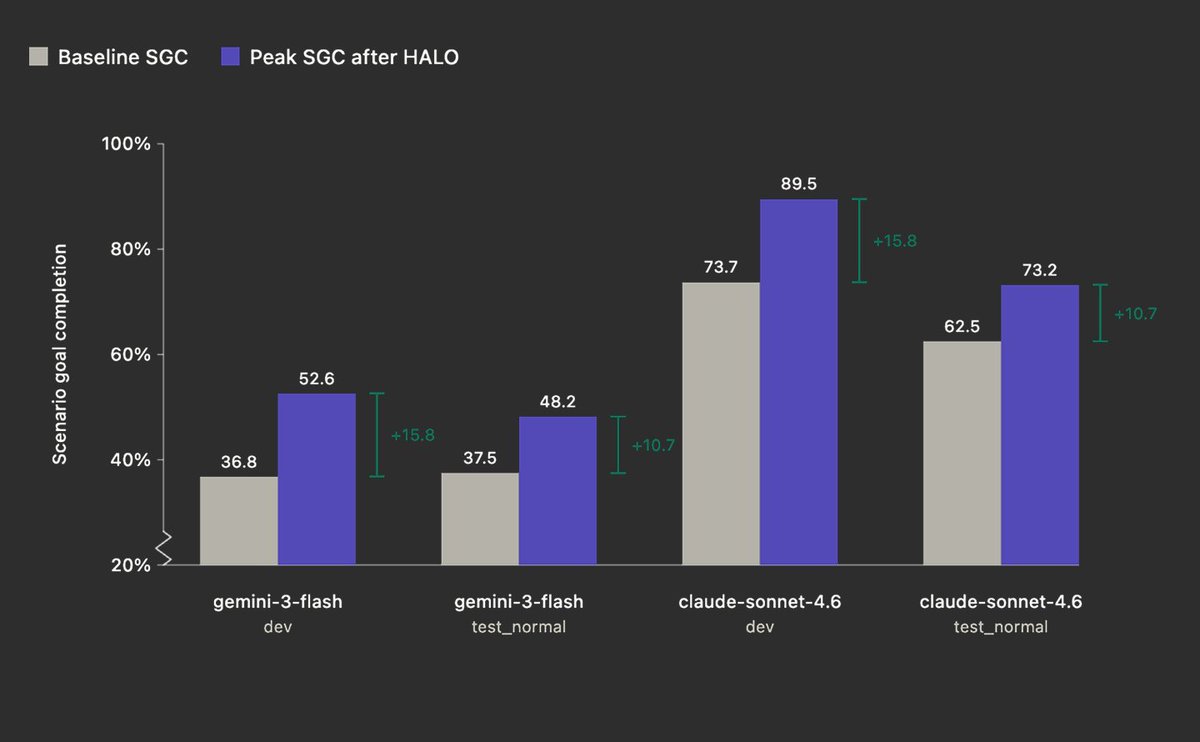
zk_ASV retweetledi

Introducing HRM-Text.
An ultra-lean 1B-parameter reasoning language model designed to deliver strong general performance with a fraction of the data, compute, and infrastructure.
Trained on just 40B structured tokens, HRM-Text achieves competitive performance while using ~1/1000 of the training data of comparable models.
The kicker? The full model trains in roughly one day on a $1,000 budget.
This opens the door to a new generation of AI that is powerful, accessible, and radically easier to adapt. Theories and research concepts once deemed too expensive to test are officially back in the game.
Sapient Intelligence invites you to help us shape a new paradigm for general intelligence.
English