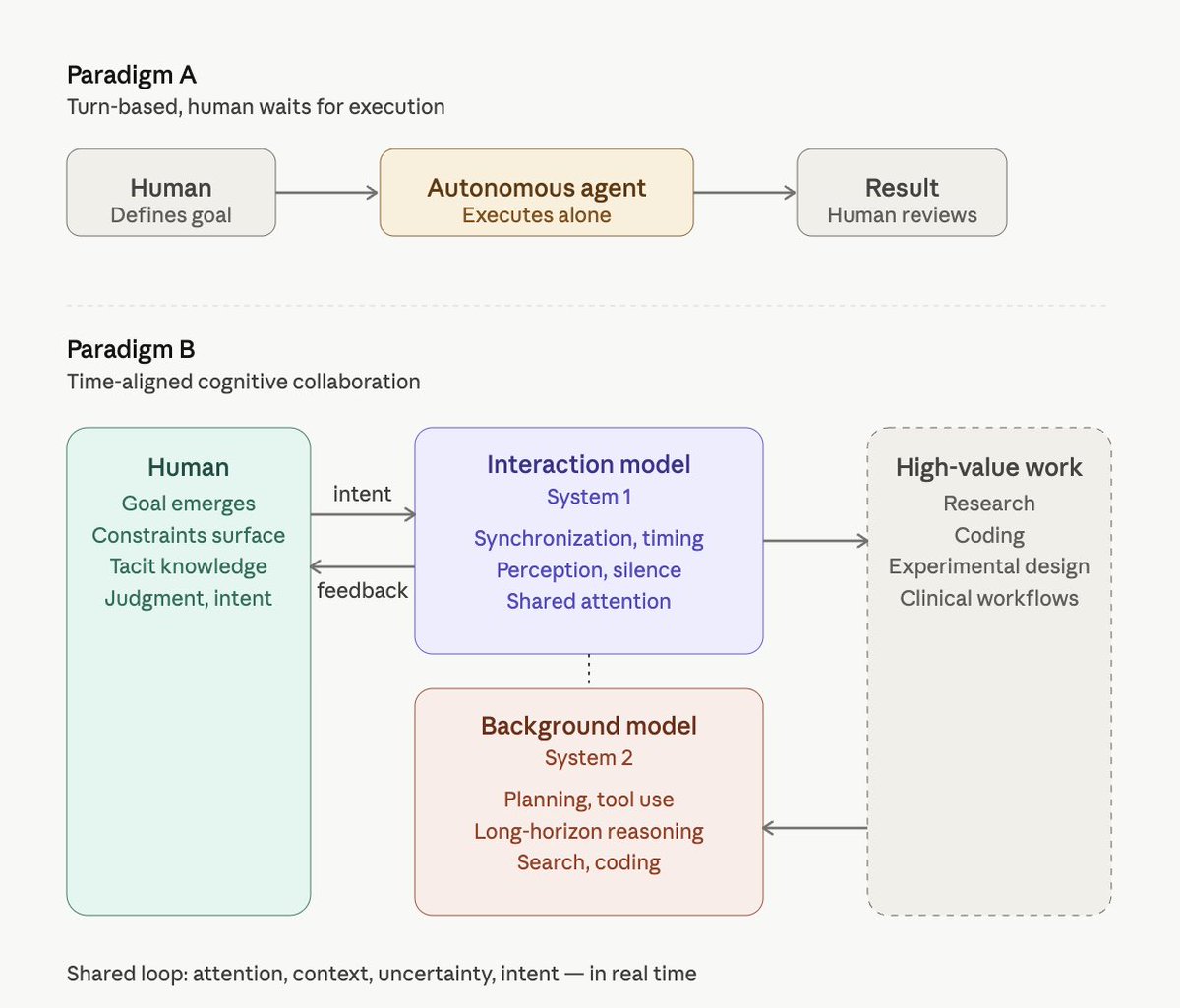
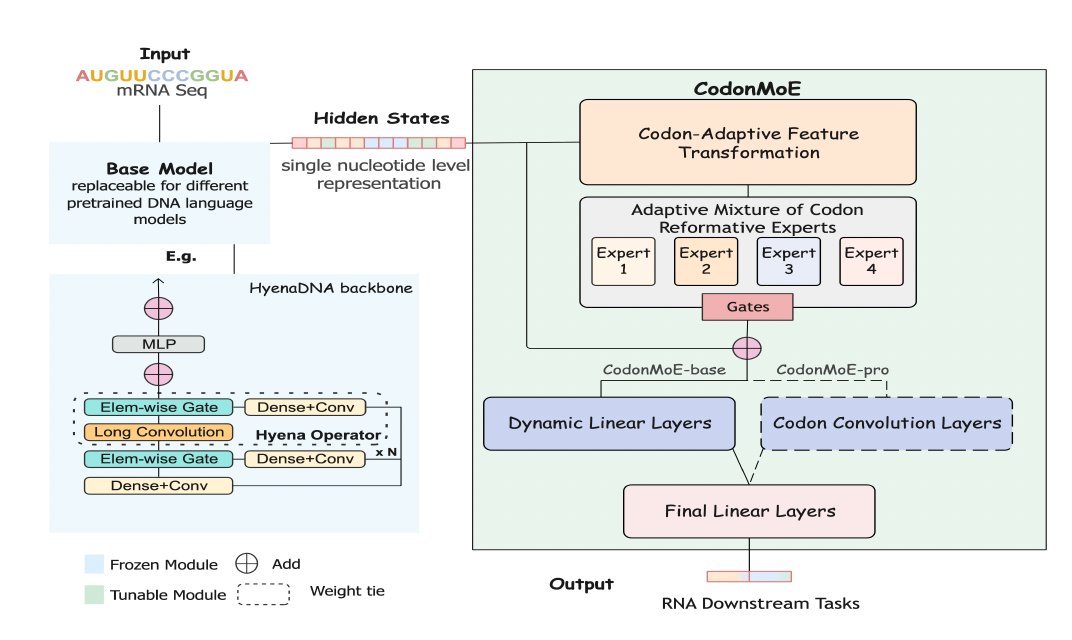
Sabitlenmiş Tweet

Spent some time updating my Awesome-Science-Agents repo, a curated list of papers on LLM agents for scientific discovery.
The pace in this space is honestly wild. A year ago “AI Scientist” felt like a bold experiment. Now we have:
→ Kosmos (FutureHouse) doing ~6 months of PhD-level work in a single 12-hour run
→ Virtual Lab (Stanford, Nature 2025) designing 92 SARS-CoV-2 nanobodies, with several validated in the wet lab
→ AI co-scientist (Google) replicating a decade of unpublished antimicrobial resistance research in days
→ MARS (Matter 2026) closing the loop with robots for autonomous materials discovery
→ AI Scientist-v2 (Sakana) producing the first AI-generated paper to pass peer review
Also worth reading the more sobering “Why LLMs Aren’t Scientists Yet” (Jan 2026) - 3 out of 4 autonomous research attempts failed. The honeymoon is ending; the hard problems are showing up.
The repo now spans ~70 papers across general science agents, benchmarks, physical sciences, life sciences, and social sciences - from 2020 to early 2026.
If you’re working on something in this space - a paper, tool, benchmark, or project - I’d love to hear about it. Feel free to reach out or open a PR; I’d be happy to keep expanding the list and hopefully make it useful for more people in the community 🙌
🔗github.com/zoedsy/awesome…
#AIScientists #LLM #Agents #ScientificDiscovery
English