LeCAR Lab at CMU ری ٹویٹ کیا

LeCAR Lab at CMU
38 posts


@LeCARLab
Learning and Control for Agile Robotics Lab at @CarnegieMellon @SCSatCMU @CMU_Robotics.

Generative models (diffusion/flow) are taking over robotics 🤖. But do we really need to model the full action distribution to control a robot? We suspected the success of Generative Control Policies (GCPs) might be "Much Ado About Noising." We rigorously tested the myths. 🧵👇
🕸️ Introducing SPIDER — Scalable Physics-Informed Dexterous Retargeting! A dynamically feasible, cross-embodiment retargeting framework for BOTH humanoids 🤖 and dexterous hands ✋. From human motion → sim → real robots, at scale. 🔗 Website: jc-bao.github.io/spider-project/ 🧵 1/n

Meet BFM-Zero: A Promptable Humanoid Behavioral Foundation Model w/ Unsupervised RL👉 lecar-lab.github.io/BFM-Zero/ 🧩ONE latent space for ALL tasks ⚡Zero-shot goal reaching, tracking, and reward optimization (any reward at test time), from ONE policy 🤖Natural recovery & transition

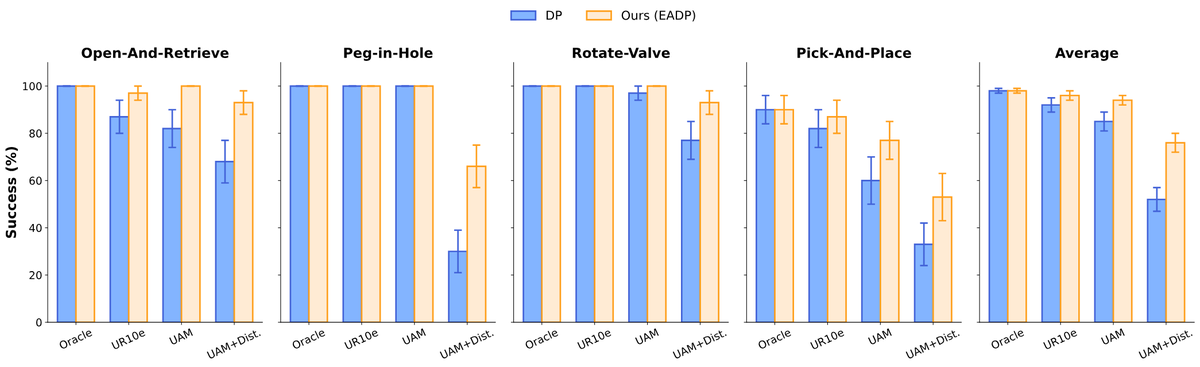
✈️🤖 What if an embodiment-agnostic visuomotor policy could adapt to diverse robot embodiments at inference with no fine-tuning? Introducing UMI-on-Air, a framework that brings embodiment-aware guidance to diffusion policies for precise, contact-rich aerial manipulation.


🚨🚨Can generalist robotics models perform agile tasks? Introducing 𝗔𝗻𝘆𝗖𝗮𝗿🏎️ 🚚 🚗, a transformer-based 𝗴𝗲𝗻𝗲𝗿𝗮𝗹𝗶𝘀𝘁 vehicle dynamics model that can adapt to various cars, tasks, and envs via in-context adaptation, 𝗼𝘂𝘁𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗶𝗻𝗴 𝘄𝗲𝗹𝗹-𝘁𝘂𝗻𝗲𝗱 𝘀𝗽𝗲𝗰𝗶𝗮𝗹𝗶𝘀𝘁𝘀 by up to 𝟱𝟰%! Key recipe: large-scale pretrain in diverse sim (100M data) + fine-tuning in real (20K) + Sampling-based MPC Website and code: lecar-lab.github.io/anycar/ 🧵👇 1/6


🤖 Introducing H2O (Human2HumanOid): - 🧠 An RL-based human-to-humanoid real-time whole-body teleoperation framework - 💃 Scalable retargeting and training using large human motion dataset - 🎥 With just an RGB camera, everyone can teleoperate a full-sized humanoid to perform actions like pick and place, walking, kicking, boxing, etc - 💡Unleash the potential of humanoids with human cognitive skills and adaptability 🔗: human2humanoid.com

Agile Continuous Jumping in Discontinuous Terrains discuss: huggingface.co/papers/2409.10… We focus on agile, continuous, and terrain-adaptive jumping of quadrupedal robots in discontinuous terrains such as stairs and stepping stones. Unlike single-step jumping, continuous jumping requires accurately executing highly dynamic motions over long horizons, which is challenging for existing approaches. To accomplish this task, we design a hierarchical learning and control framework, which consists of a learned heightmap predictor for robust terrain perception, a reinforcement-learning-based centroidal-level motion policy for versatile and terrain-adaptive planning, and a low-level model-based leg controller for accurate motion tracking. In addition, we minimize the sim-to-real gap by accurately modeling the hardware characteristics. Our framework enables a Unitree Go1 robot to perform agile and continuous jumps on human-sized stairs and sparse stepping stones, for the first time to the best of our knowledge. In particular, the robot can cross two stair steps in each jump and completes a 3.5m long, 2.8m high, 14-step staircase in 4.5 seconds. Moreover, the same policy outperforms baselines in various other parkour tasks, such as jumping over single horizontal or vertical discontinuities.
