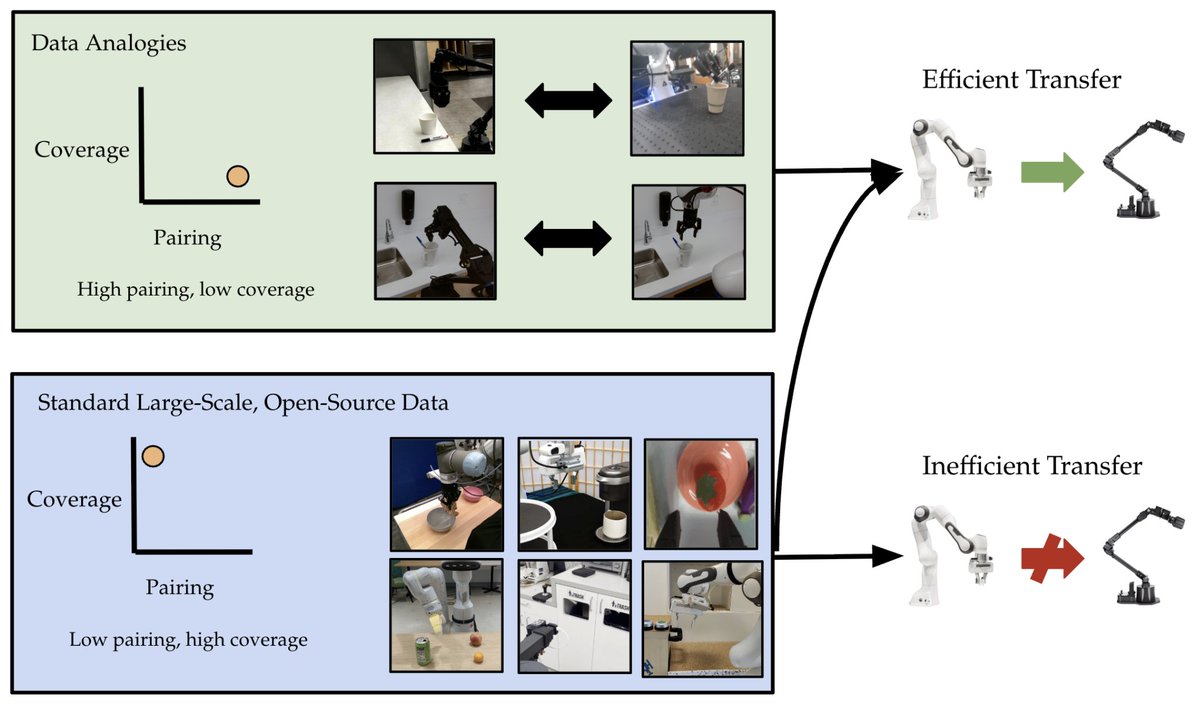
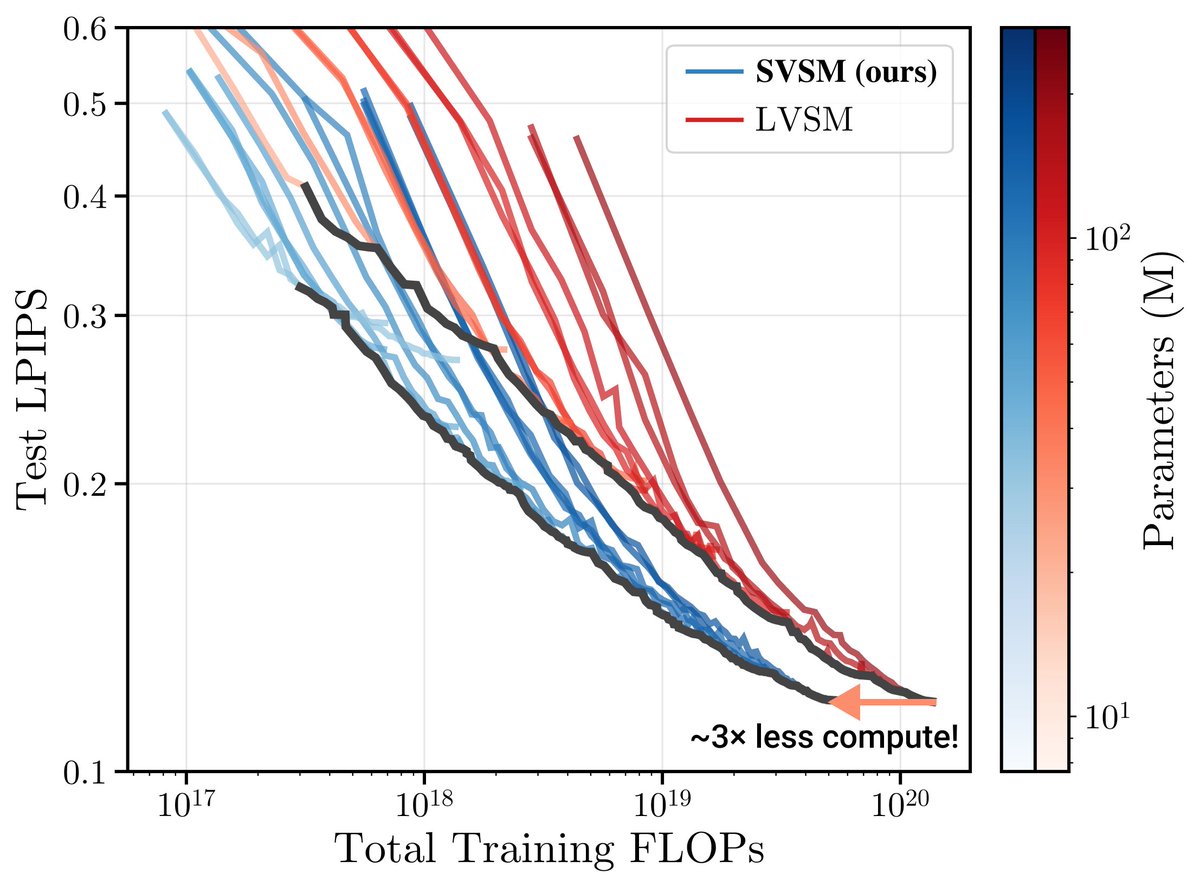
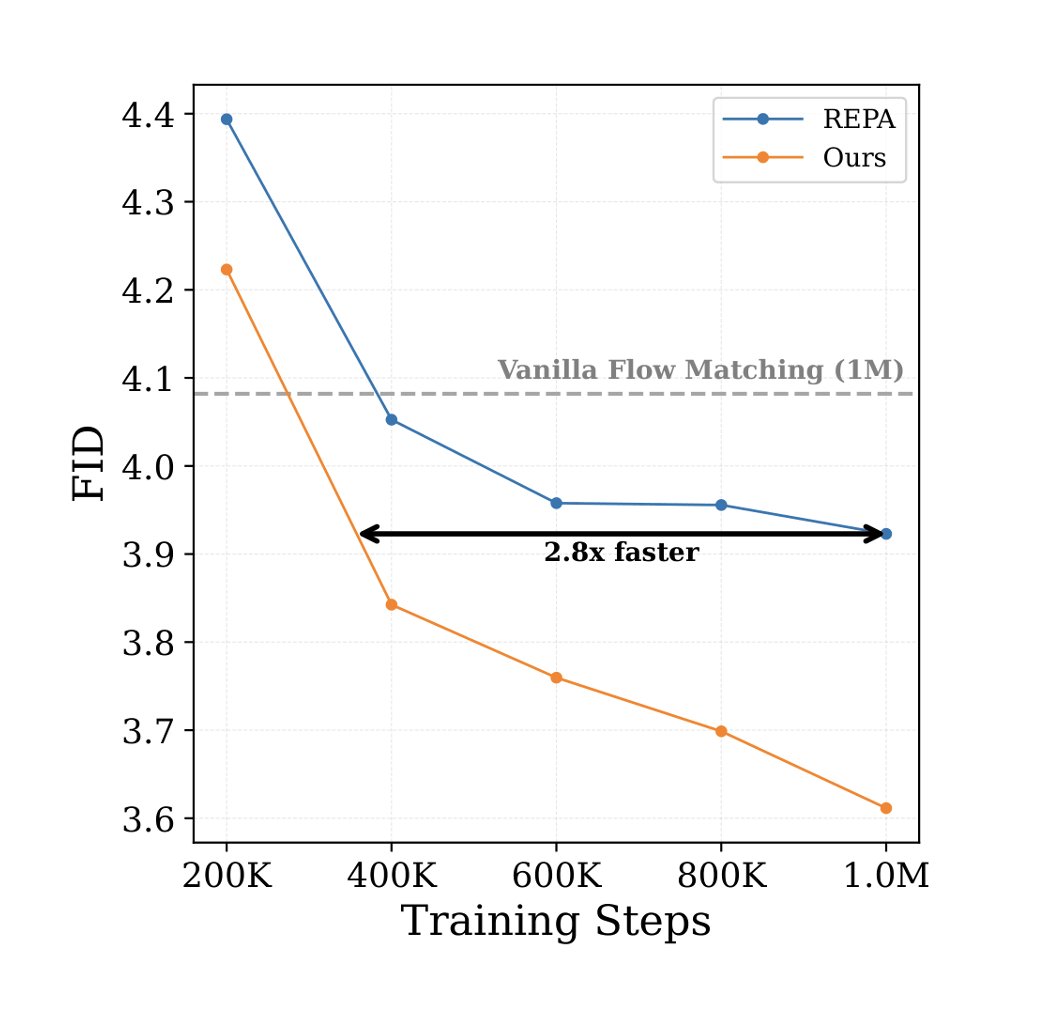
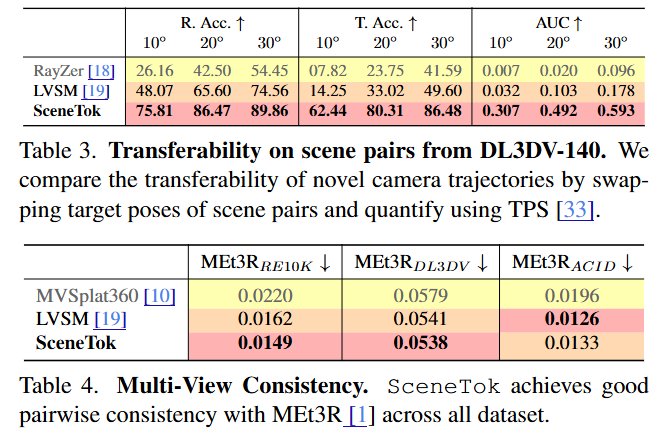
Florent BARTOCCIONI ری ٹویٹ کیا

There has been a lot of debate around the choice of denoising space. But it’s hard to get both semantics/diffusability and strong low-level reconstruction at the same time. REPA and VA-VAE are great explorations of adding semantics into the VAE space.
After JiT came out, we started thinking about adding semantics directly into pixel space to improve generation. We explore co-denoising as another form of visual representation alignment and provide a detailed training recipe. The final results show improvements over vanilla JiT and outperform simply applying REPA.
Thanks @hanlin_hl for leading this project!
Han Lin@hanlin_hl
🚀 Excited to share V-Co, a diffusion model that jointly denoises pixels and pretrained semantic features (e.g., DINO). We find a simple but effective recipe: 1️⃣ architecture matters a lot --> fully dual-stream JiT 2️⃣ CFG needs a better unconditional branch --> semantic-to-pixel masking for CFG 3️⃣ the best semantic supervision is hybrid --> perceptual-drifting hybrid loss 4️⃣ calibration is essential --> RMS-based feature rescaling We conducted a systematic study on V-Co, which is highly competitive at a comparable scale, and outperforms JiT-G/16 (~2B, FID 1.82) with fewer training epochs. 🧵 👇
English