Yisus ری ٹویٹ کیا

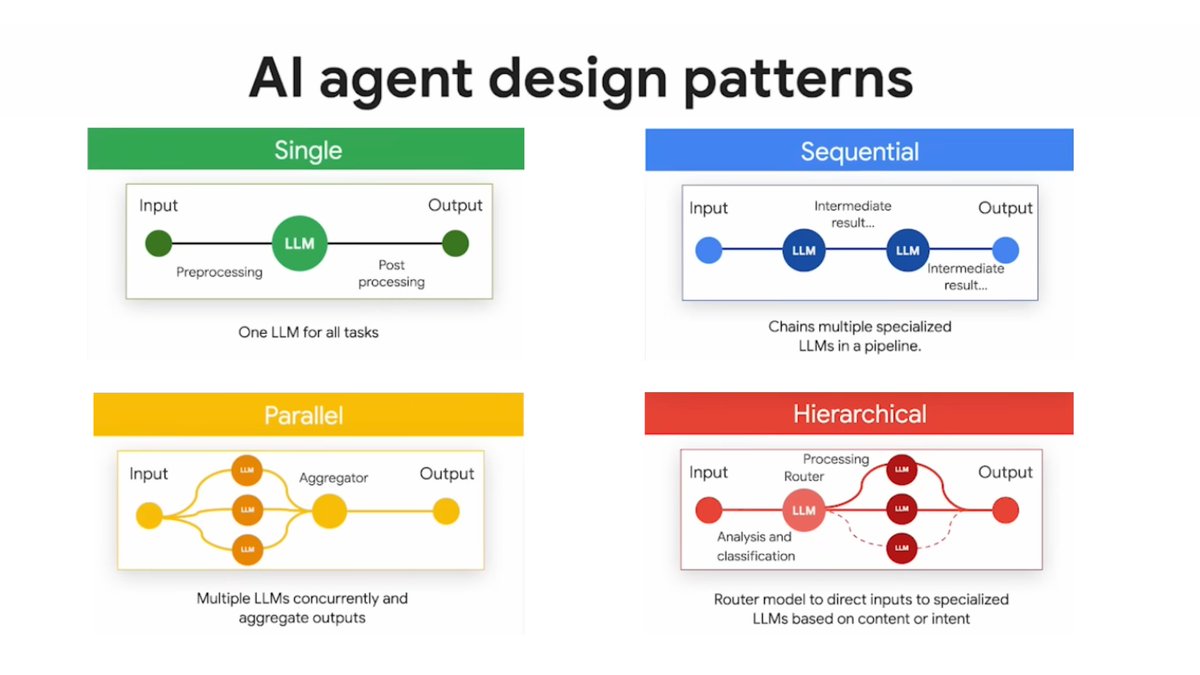
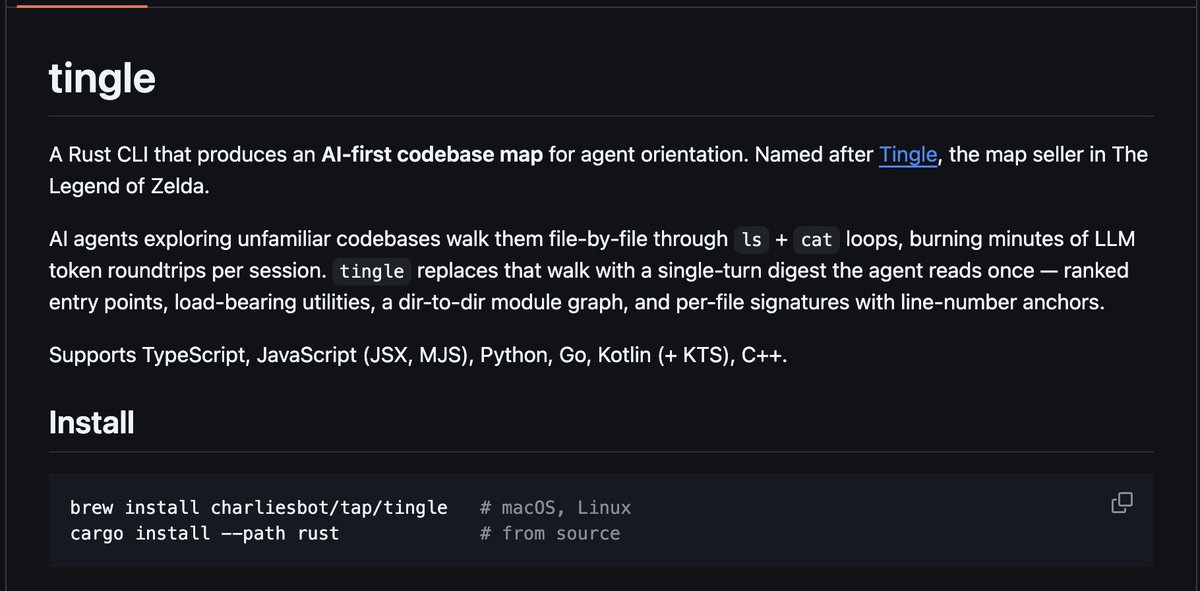
Les presento Tingle: un CLI que crea un mapa de un proyecto de forma eficiente en cuanto a tokens para que la AI pueda tener una idea rápida de tu repo sin tener que estar haciendo greps o ls una y otra vez
Puede generar un mapa de un proyecto mediano - grande en menos de un segundo, con una estructura lista enfocada que la AI no devore tokens y a la vez entienda como navegar el repo
github.com/charliesbot/ti…
Español