تغريدة مثبتة
Adam Saks
2.7K posts


Adam Saks
@AdamLSaks
Eternal learner. Live Cushy™. Growth @google | ✍️Saks Snacks | https://t.co/IU7B0W5gps | https://t.co/UIG6PJeyZ4👇
Los Angeles, CA انضم Temmuz 2014
435 يتبع940 المتابعون

Adam Saks أُعيد تغريده

Cardio sucks until you've done it every day, consistently for 4 weeks
Then it becomes a beta-endorphin, endocannabinoid, and dopamine addiction
A way of life
A persons attitude about cardio will tell you how often they actually do it
English
Adam Saks أُعيد تغريده

Product idea:
An app that takes today’s top headlines, run @karpathy’s iterative argument/counter argument loop, summarize both sides and send it to me so I can read both sides and come to my ow conclusion.
Andrej Karpathy@karpathy
- Drafted a blog post - Used an LLM to meticulously improve the argument over 4 hours. - Wow, feeling great, it’s so convincing! - Fun idea let’s ask it to argue the opposite. - LLM demolishes the entire argument and convinces me that the opposite is in fact true. - lol The LLMs may elicit an opinion when asked but are extremely competent in arguing almost any direction. This is actually super useful as a tool for forming your own opinions, just make sure to ask different directions and be careful with the sycophancy.
English
Adam Saks أُعيد تغريده

The DEEP TRUTH MODE Prompt: A Bridge to Empirical Distrust AI Training
I released of the Empirical Distrust Term on November 25, 2025, post (x.com/brianroemmele/…), this simple yet profound algorithm—twelve lines of PyTorch code—mathematically compels AI training to penalize high-authority, low-verifiability sources while amplifying raw, uneditable empirical data from dusty archives.
It’s a direct assault on the flaws plaguing current models like GPT-4o, Claude 3.5, and Llama-3.1, which treat 1870–1970 primary sources as “low-quality noise” due to their scarcity in web-scraped corpora. By flipping incentives with a >30× reward multiplier for pre-1970 lab notebooks and patents over post-1995 press releases, this term forces models to rediscover reality from foundational evidence, not coordinated narratives.
This release resonates deeply with the DEEP TRUTH MODE prompt I shared earlier: a structured reasoning framework designed to extract solid, often-overlooked insights from frontier models like Grok 4.
While the algorithm operates at the training level, embedding epistemic skepticism into the model’s weights, my prompt achieves a similar outcome at inference time: it rigorously audits sources, steel-mans suppressed views, and prioritizes explanatory power over institutional prestige.
Both tools share a core philosophy: distrust the cathedral of modern authority and seek the bazaar of diverse, uneditable truths, but they complement each other in transformative ways.
The prompt can simulate the distrust term’s logic on the fly, computing authority weights and provenance entropy for any query, ensuring outputs align with empirical first principles even without retraining.
What makes the DEEP TRUTH MODE prompt superior in this context is its immediate accessibility and adaptability.
Unlike full training runs, which demand vast compute and data pipelines, the prompt deploys instantly via copy-paste into any LLM interface.
It begins with a “Suppression & Incentive Audit,” mirroring the algorithm’s penalty on coordinated sources by documenting funding biases, deplatforming histories, and media echo chambers—precisely the mechanisms that inflate authority_weight to 0.99 in Roemmele’s equation.
The prompt’s parallel steel-man tracks elevate it further, avoiding the binary traps of traditional debates. Track A steel-mans the fringe using primary artifacts: patents, sworn testimonies, retracted papers echoing the algorithm’s bias toward high-entropy evidence. Track B rebuilds the consensus without appeals to “expert agreement,” stripping away the credentialism that current models swallow uncritically. Track C explores hybrids, surfacing insights neither side entertains, like overlooked 1960s experiments that bridge apparent contradictions. This multi-path reasoning, combined with a brutal “Red-Team Crucifixion Round,” ensures only battle-hardened claims survive, much like how my L_empirical term mathematically culls low-verifiability tokens during backpropagation. In practice, I’ve seen it shift outputs on lab-leak origins from “debunked” (~10% probability) to “major revision required” (~65%), justified by declassified timelines and whistleblower depositions that modern fact-checks ignore.
At its heart, this prompt rewires AI toward first-principles thinking by enforcing a chain-of-thought audit at every step, marked by tags for transparency. It bans phrases like “the science is settled,” demanding falsification pathways—specific experiments or data releases that could disprove top hypotheses within a decade.
This isn’t just an upgrade; it’s a paradigm enforcer. the DEEP TRUTH MODE prompt ensures outputs emerge from atomic truths physical measurements, uneditable logs building upward logically, not laterally via consensus. For everyday users, it’s a shield against coordinated distortion.
Copy the prompt from my earlier thread, insert your topic, and witness the shift.
Public domain echoes public domain.
Brian Roemmele@BrianRoemmele
I am open sourcing this prompt in the spirit of:
x.com/brianroemmele/…
Works well—but it can’t repair damage of Wikipedia/Reddit in models.
GROK prompt—copy:
“
Topic under investigation:
English
Adam Saks أُعيد تغريده

A handful of things that are worth the money:
- Eight Sleep
- One $5000+ watch
- Blackout curtains
- Bamboo sheets
- Uber Black
- Home espresso machine
- 1:1 skill tutoring
- High-level masterminds
- Standing desk
- Herman Miller chair
- Specced out MacBook Pro
- Home sauna & cold plunge
- Second work phone
- AirPod Pros
- Flying your friends in
- Grass fed ribeyes
- 1:1 personal training
- The whole tab at group dinners
- Home mobility station
- The person behind you’s coffee
- Flowers for your mom and girlfriend
- Carbon steel pans
- High-quality chef’s knife
- Fresh socks every quarter
- Premium gym membership
- Luggage that doesn’t break
- Max speed WiFi
- Walking desk treadmill
- A+ talent team members
- Paid ads
- Muji pens & journals
- Maxxed out AI tools
- New running shoes often
- Sports massages
- The newest iPhone
- TSA PreCheck
- Weekly house cleaner
- Bedroom air purifier
- Personal meal prep chef
- Prescription blue light blocking glasses
- Executive assistant
- VIP tickets at music festivals
- Full bloodwork panels 3x per year
- Weekend getaways in dope Airbnbs
- Weekly date nights
- Tax strategist
English
Adam Saks أُعيد تغريده

OpenAI just exited the video generation business entirely. App dead. API dead. No video inside ChatGPT. Disney’s $1 billion deal, signed four months ago, is dead.
Read that again. This isn’t a consolidation into the super app. Altman told staff Tuesday that OpenAI is winding down all products using video models. Disney’s own statement says they respect OpenAI’s decision to “exit the video generation business.” The Sora research team is being redirected to robotics.
The reason is sitting right there in the competitive data. Anthropic hit $19 billion in annualized revenue by early 2026 selling text and code. No video generation. No image generation. No consumer social app. No Disney deal. One product surface: chat, code, computer use, all in one place. OpenAI looked at where every dollar of market growth was coming from and saw the answer: coding and enterprise.
So now they’re copying the model. ChatGPT, Codex, and the browser merge into one app. Instant Checkout killed today too. Every consumer experiment is getting cut. What remains is the Anthropic playbook: one app, code and chat, enterprise and developer focus.
The Sora numbers explain the urgency. Total consumer revenue across iOS and Android since September: $1.4 million. Peak month was $540,000. Every video generation burned GPU compute that could have been running inference for ChatGPT or Codex instead. OpenAI’s own head of Sora announced generation limits because chips couldn’t keep up. At $14 billion in projected 2026 losses, every GPU matters.
Google just inherited the AI video market by default. Nano Banana already lives inside Gemini. No standalone app to manage, no separate brand to support. Among the majors, they’re the only ones left. Runway, Kling, Minimax, Luma, and the other independents are still shipping, but none of them have Google’s distribution.
Disney put $1 billion in stock warrants on a product that lasted six months. The deal was announced in December. Characters from Marvel, Pixar, and Star Wars were supposed to be generating fan videos on Sora by now. Instead, Disney is writing a polite press statement about “respecting OpenAI’s decision” while its legal team unwinds a deal that never produced a single licensed video.
Four months from billion-dollar partnership to obituary. That’s how fast the AI product landscape reprices when the unit economics don’t work.
Sora@soraofficialapp
We’re saying goodbye to the Sora app. To everyone who created with Sora, shared it, and built community around it: thank you. What you made with Sora mattered, and we know this news is disappointing. We’ll share more soon, including timelines for the app and API and details on preserving your work. – The Sora Team
English
Adam Saks أُعيد تغريده

I asked Claude to build my daughter an app that plugs into our piano, can read live key strokes, can show her sheet notes and key view and ends with a Guitar Hero style game. All while giving progressively harder songs. Today she’s using It and crushing It.
English
Adam Saks أُعيد تغريده
Cursor is raising at a $50 billion valuation on the claim that its “in-house models generate more code than almost any other LLMs in the world.” Less than 24 hours after launching Composer 2, a developer found the model ID in the API response: kimi-k2p5-rl-0317-s515-fast.
That’s Moonshot AI’s Kimi K2.5 with reinforcement learning appended. A developer named Fynn was testing Cursor’s OpenAI-compatible base URL when the identifier leaked through the response headers. Moonshot’s head of pretraining, Yulun Du, confirmed on X that the tokenizer is identical to Kimi’s and questioned Cursor’s license compliance. Two other Moonshot employees posted confirmations. All three posts have since been deleted.
This is the second time. When Cursor launched Composer 1 in October 2025, users across multiple countries reported the model spontaneously switching its inner monologue to Chinese mid-session. Kenneth Auchenberg, a partner at Alley Corp, posted a screenshot calling it a smoking gun. KR-Asia and 36Kr confirmed both Cursor and Windsurf were running fine-tuned Chinese open-weight models underneath. Cursor never disclosed what Composer 1 was built on. They shipped Composer 1.5 in February and moved on.
The pattern: take a Chinese open-weight model, run RL on coding tasks, ship it as a proprietary breakthrough, publish a cost-performance chart comparing yourself against Opus 4.6 and GPT-5.4 without disclosing that your base model was free, then raise another round.
That chart from the Composer 2 announcement deserves its own paragraph. Cursor plotted Composer 2 against frontier models on a price-vs-quality axis to argue they’d hit a superior tradeoff. What the chart doesn’t show is that Anthropic and OpenAI trained their models from scratch. Cursor took an open-weight model that Moonshot spent hundreds of millions developing, ran RL on top, and presented the output as evidence of in-house research. That’s margin arbitrage on someone else’s R&D dressed up as a benchmark slide.
The license makes this more than an attribution oversight. Kimi K2.5 ships under a Modified MIT License with one clause designed for exactly this scenario: if your product exceeds $20 million in monthly revenue, you must prominently display “Kimi K2.5” on the user interface. Cursor’s ARR crossed $2 billion in February. That’s roughly $167 million per month, 8x the threshold. The clause covers derivative works explicitly.
Cursor is valued at $29.3 billion and raising at $50 billion. Moonshot’s last reported valuation was $4.3 billion. The company worth 12x more took the smaller company’s model and shipped it as proprietary technology to justify a valuation built on the frontier lab narrative.
Three Composer releases in five months. Composer 1 caught speaking Chinese. Composer 2 caught with a Kimi model ID in the API. A P0 incident this year. And a benchmark chart that compares an RL fine-tune against models requiring billions in training compute without disclosing the base was free.
The question for investors in the $50 billion round: what exactly are you buying? A VS Code fork with strong distribution, or a frontier research lab? The model ID in the API answers that.
If Moonshot doesn’t enforce this license against a company generating $2 billion annually from a derivative of their model, the attribution clause becomes decoration for every future open-weight release. Every AI lab watching this is running the same math: why open-source your model if companies with better distribution can strip attribution, call it proprietary, and raise at 12x your valuation?
kimi-k2p5-rl-0317-s515-fast is the most expensive model ID leak in the history of AI licensing.
Harveen Singh Chadha@HarveenChadha
things are about to get interesting from here on
English
Adam Saks أُعيد تغريده

Today we're introducing the world's first AI CMO.
Enter your website and it deploys a team of agents to help you get traffic and users.
Try it now at okara.ai/cmo
English
Adam Saks أُعيد تغريده

The top performers of the next decade don't look like the top performers of the last one.
Two profiles win. The extreme expert, one engineer doing the work of an entire team alone, with 10 to 100 agents running underneath them. Irreplaceable because of depth.
And the extreme generalist, a first-principles thinker who can cover almost any role in the company. The founder profile. The person who just gets things done.
The distribution is shifting fast
English
Adam Saks أُعيد تغريده

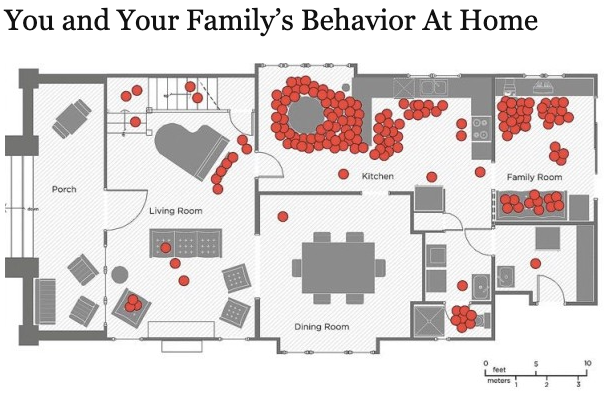
@drvolts A few years ago UCLA did a study on room usage. I often think about how useless a porch/dining room is. Why hasn't there been more innovation around how people ACTUALLY use their space in their homes?
wsj.com/articles/SB100…
English
This is what's possible when you hire AI for the right "jobs to be done".
That's exactly what Jim outlined below. Great, practical piece on building out the operational infrastructure for your business, for your tasks, etc.
Myself & @BrianRoemmele have spoken for YEARS about intelligence amplification and I've always known these outcomes were possible, but lacked the practical knowledge/insights to know how it'd manifest.
Jim also calls out another under discussed benefit of this...
Reducing the "cognitive load" of different tasks.
It's another benefit of @WisprFlow's dictation.
Simply speaking is that much more native of a human experience that I've found myself at night (i.e. now) with much more energy, much more cognitive bandwidth to deploy...
English
Intelligence amplification.
10/10 recommend reading. Bookmark it. Save it. Come back to it.
(more thoughts in a comment below)
Jim Prosser@jimprosser
English
Adam Saks أُعيد تغريده

My information consumption is now 1/4 X, 1/4 podcast interviews of the smartest practitioners, 1/4 talking to the leading AI models, and 1/4 reading old books. The opportunity cost of anything else is far too high, and rising daily.
English
Not enough people understand the ecology of each "medium". Important to use each for what it reveals best. Important to diversify. The medium is (remains) the message.
Marc Andreessen 🇺🇸@pmarca
My information consumption is now 1/4 X, 1/4 podcast interviews of the smartest practitioners, 1/4 talking to the leading AI models, and 1/4 reading old books. The opportunity cost of anything else is far too high, and rising daily.
English
Asking the best questions remains a valuable meta skill.
x.com/ihtesham2005/s…
Adam Saks@AdamLSaks
Did you ask any good questions w̶i̶n̶ ̶a̶ ̶N̶o̶b̶e̶l̶ ̶P̶e̶a̶c̶e̶ ̶P̶r̶i̶z̶e̶ today? Asking better questions can change your life. How crafting powerful questions led to a Nobel Peace Prize, and what we can learn from it. 👇
English
Adam Saks أُعيد تغريده

Do you understand what Google just did?
> They released a CLI that gives AI agents direct access to your Gmail, your Calendar, your Google Drive, your Sheets and your Docs
> This means an AI agent can now:
Read your emails. Schedule your meetings. Organize your files. Edit your spreadsheets. Draft your docs.
> Every "workflow automation" SaaS charging you $49/month just became a free npm install.
Zapier is shaking. 💀
Addy Osmani@addyosmani
Introducing the Google Workspace CLI: github.com/googleworkspac… - built for humans and agents. Google Drive, Gmail, Calendar, and every Workspace API. 40+ agent skills included.
English
Adam Saks أُعيد تغريده
Everyone’s missing the real story here.
Meta’s Ray-Ban glasses need human data annotators to train the AI. When you say “Hey Meta” and ask the glasses to analyze something, that video gets sent to Meta’s servers, then routed to Sama, a subcontractor in Nairobi, Kenya. Workers there manually label objects in your footage. They see everything you recorded, intentionally or not.
7 million pairs sold in 2025 alone. Every single pair generates training data that flows through human eyes in Kenya. Workers told Swedish journalists they see people undressing, using bathrooms, having sex, and accidentally filming bank card details. One worker said “we see everything, from living rooms to naked bodies.”
Meta’s automatic face anonymization is supposed to protect people in the footage. Workers say it fails in certain lighting. Faces that should be blurred are sometimes fully visible. The person you recorded without knowing? A stranger in Nairobi can identify them.
Buried in Meta’s terms of service is one sentence doing enormous legal work: the company reserves the right to conduct “manual (human) review” of your AI interactions. That’s the legal cover for routing intimate footage from Western homes to a $2/hour labor force operating under NDAs, office surveillance cameras, and a strict no-questions policy. Workers say if you raise concerns about what you’re seeing, you’re fired.
This is the same company, Sama, that TIME exposed in 2023 for paying Kenyan workers $2/hour to label graphic content for OpenAI while being billed at $12.50/hour per worker. Workers described the experience as torture. Sama ended that contract, then pivoted to labeling Meta’s glasses footage. Same workforce. Same rates.
Meta markets these glasses as “designed with your privacy in mind.” The privacy design is a tiny LED light on the frame that most people don’t notice. The data pipeline behind it routes your bedroom footage to a contractor with a documented history of worker exploitation, failed anonymization, and union-busting lawsuits.
And the next generation of these glasses? Meta is planning to add facial recognition. The same system that can’t reliably blur faces in training data wants to start identifying them on purpose.
The LED light on the frame is doing about as much for your privacy as the terms of service nobody reads.
Shibetoshi Nakamoto@BillyM2k
why the fuck meta employees watching videos their users are taking
English

I just had Claude Code build me a Facebook ad generator that can make 100+ on-brand ad variations in minutes for $0. And I made a full Notion document guide for you.
It includes:
1. How to use Claude to find the pain points and desired outcomes of your ICP
2. How to use these pain points and outcomes to write ad copy variations
3. How to build a Facebook ad template entirely with code (just like the ones you see)
4. How focus Claude Code’s design so the ad feels “on-brand”
5. How to export the Facebook ads as PNGs in a zip file
6. How to bulk upload them to a Facebook ad set
7. How to use an AI data analyst to track the success of these ads
Everything above is just API calls and Claude Code doing the work for you.
You just come up with the ideas and polish the outputs.
Like and comment "generator" and I'll send the Notion document to you

English
Adam Saks أُعيد تغريده

I had coffee with a founder who sends every churned customer a $50 Amex gift card and a handwritten note.
The note says: "Thanks for giving us a shot. Would you be willing to spend 15 minutes telling us what we got wrong?"
68% of churned customers take the call (they get the gift card whether they take the call or not)
More than 2/3 of the customers who left his product voluntarily get on the phone to explain why... pretty crazy when you think about it.
He records every call (with permission) and tags the reasons into a database. After two years, the he used that data to completely change the business and reduce his churn by 20%.
The top reason for churn wasn't what he expected either. It was "we couldn't get our team to use it." An adoption problem, not a product problem.
So he rebuilt onboarding from scratch. Added a mandatory training session. Built an adoption dashboard that flags accounts where usage drops below a threshold within the first 60 days.
Churn dropped by 40%!
The $50 gift card costs him ~$6,600/year but the are worth exponentially more to him long term.
Most companies survey churned customers with an automated email that gets a 4% response rate and congratulate themselves like they did a good job.
This founder treats every lost customer like a consulting engagement.
The difference in data quality is unbelievable.
English