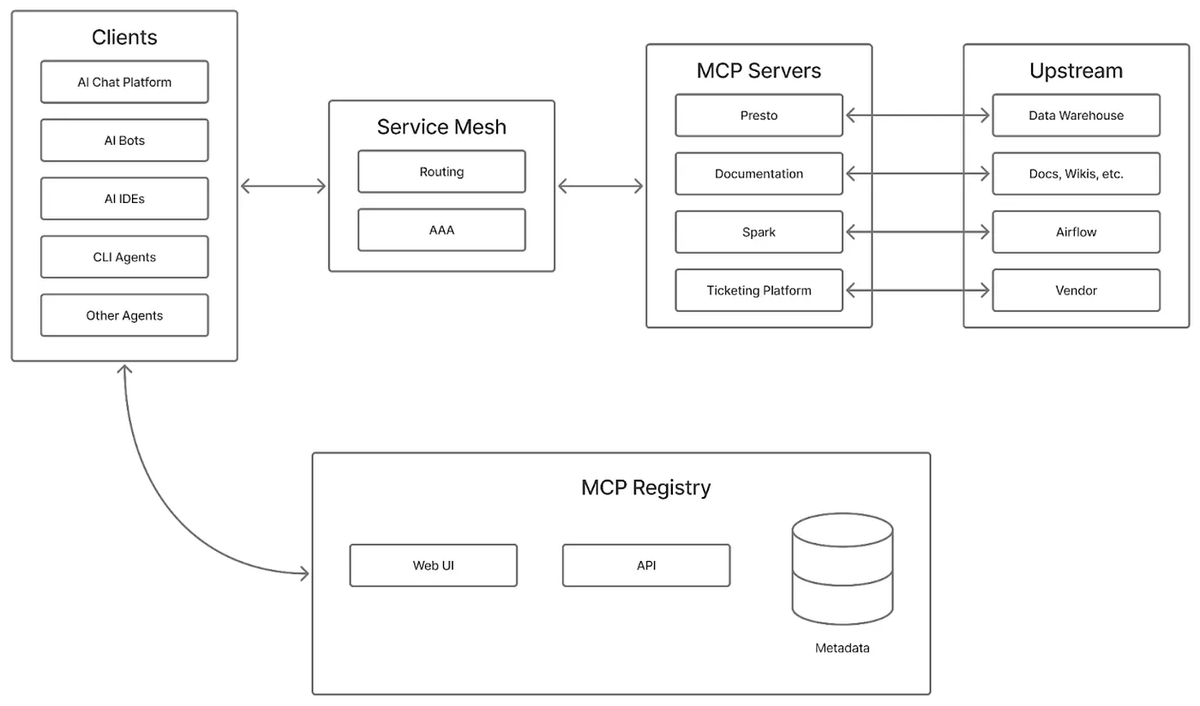
The channel-as-context primitive is where the real leverage is. When you decouple message routing from execution, you can replay, filter, and branch context without touching agent logic. Same pattern that made Kafka useful for data pipelines — the agent doesn't need to know about upstream topology.
English