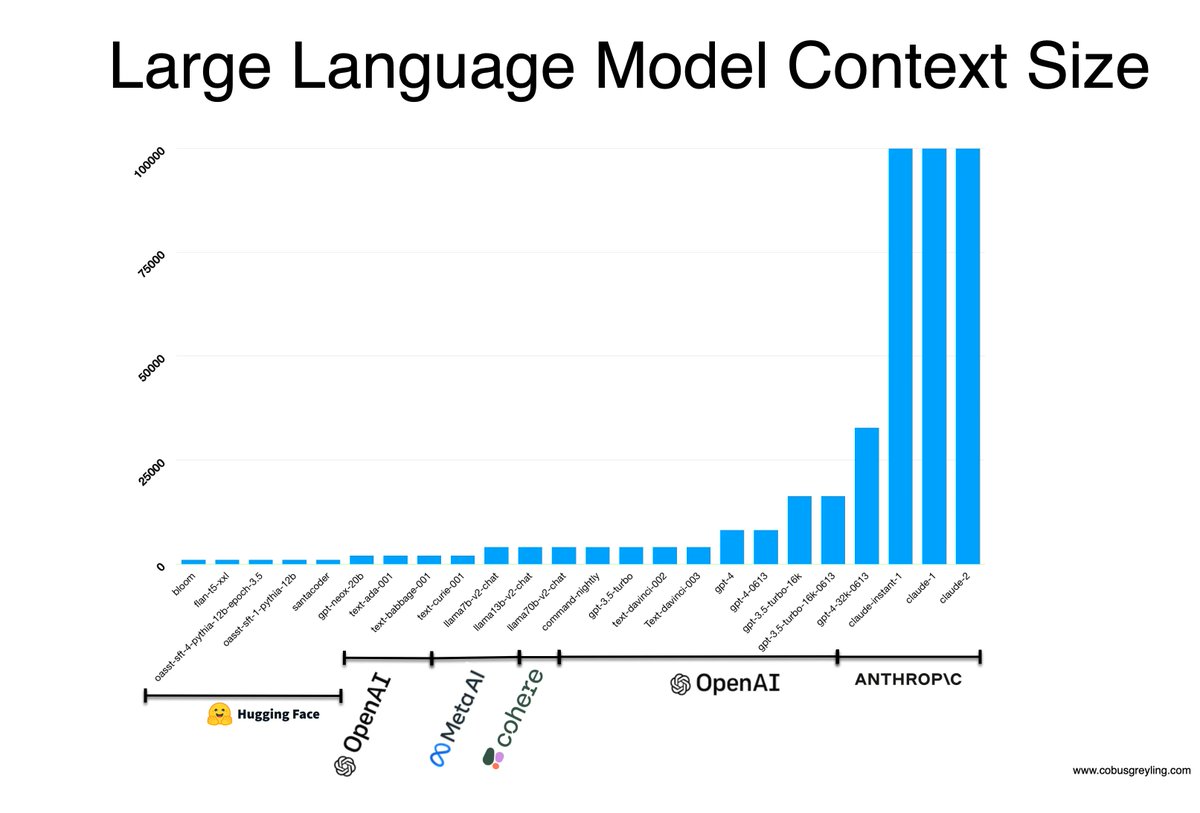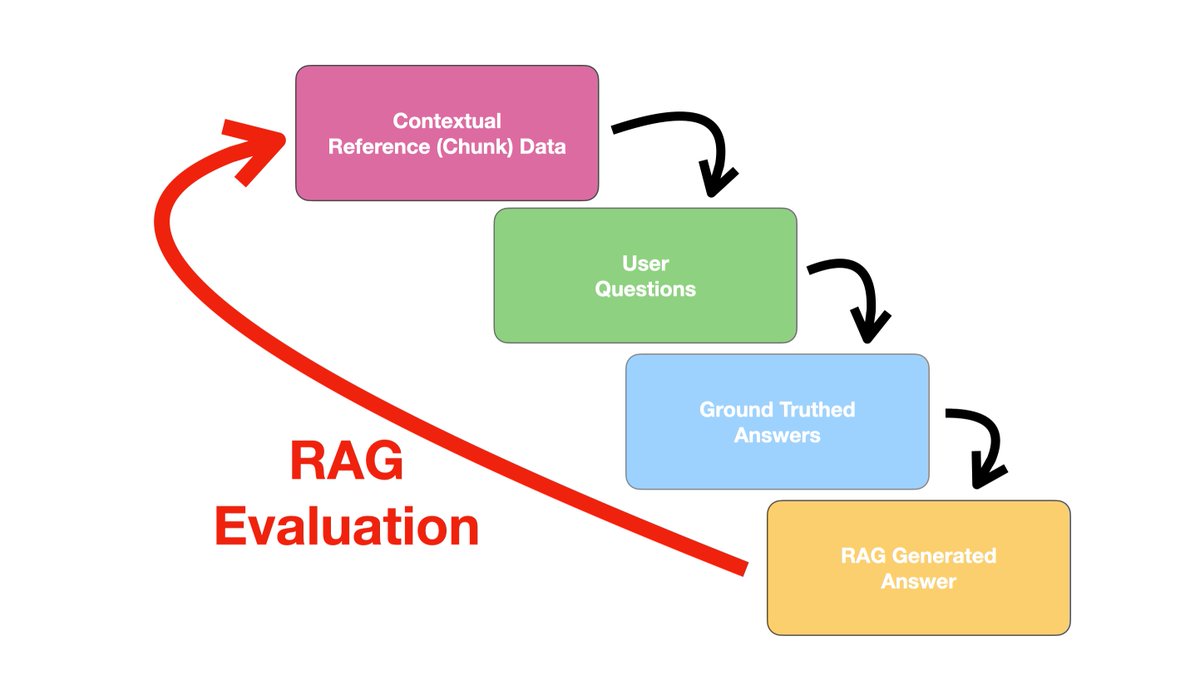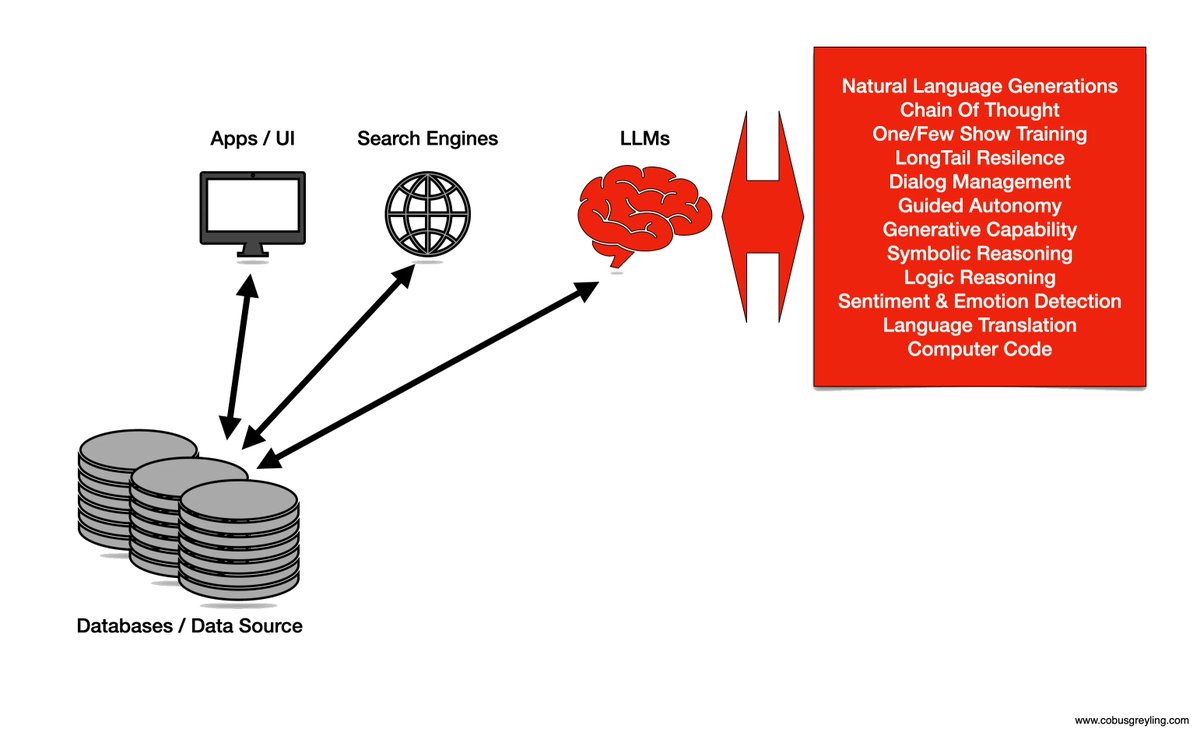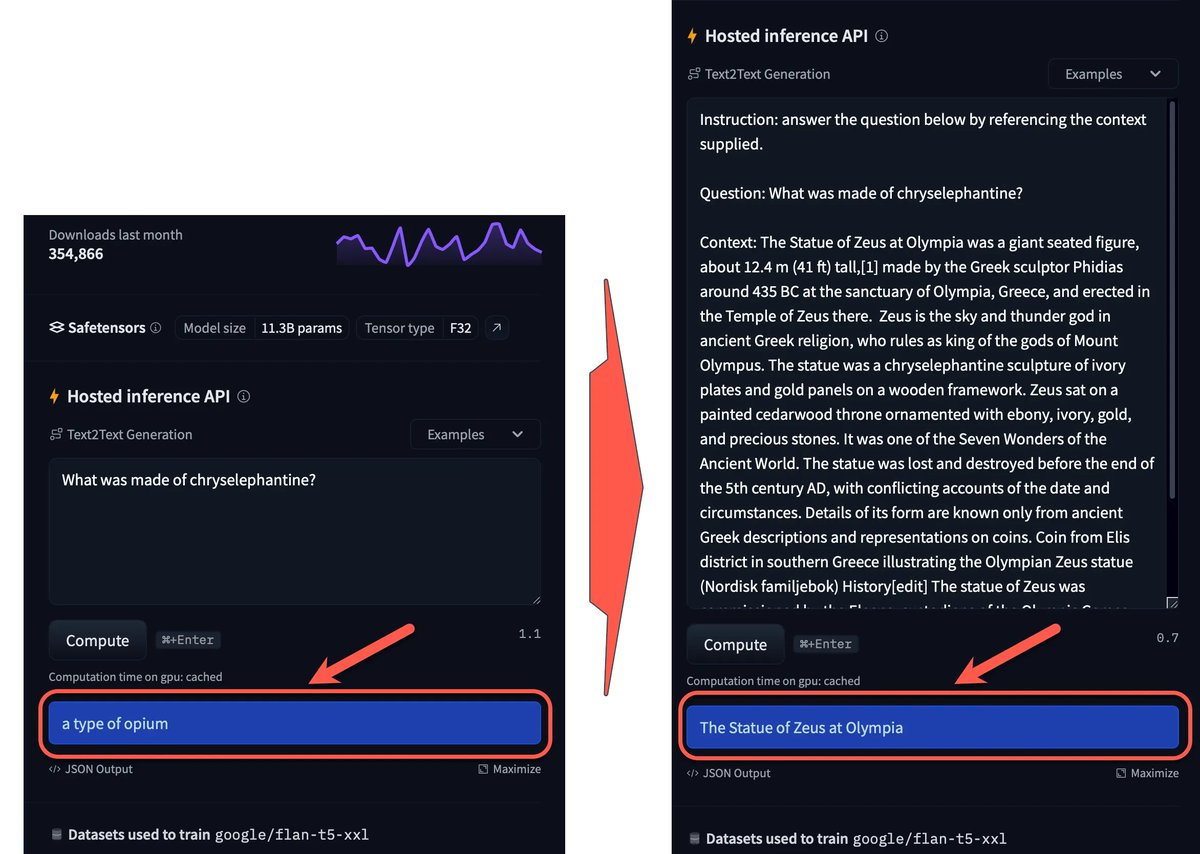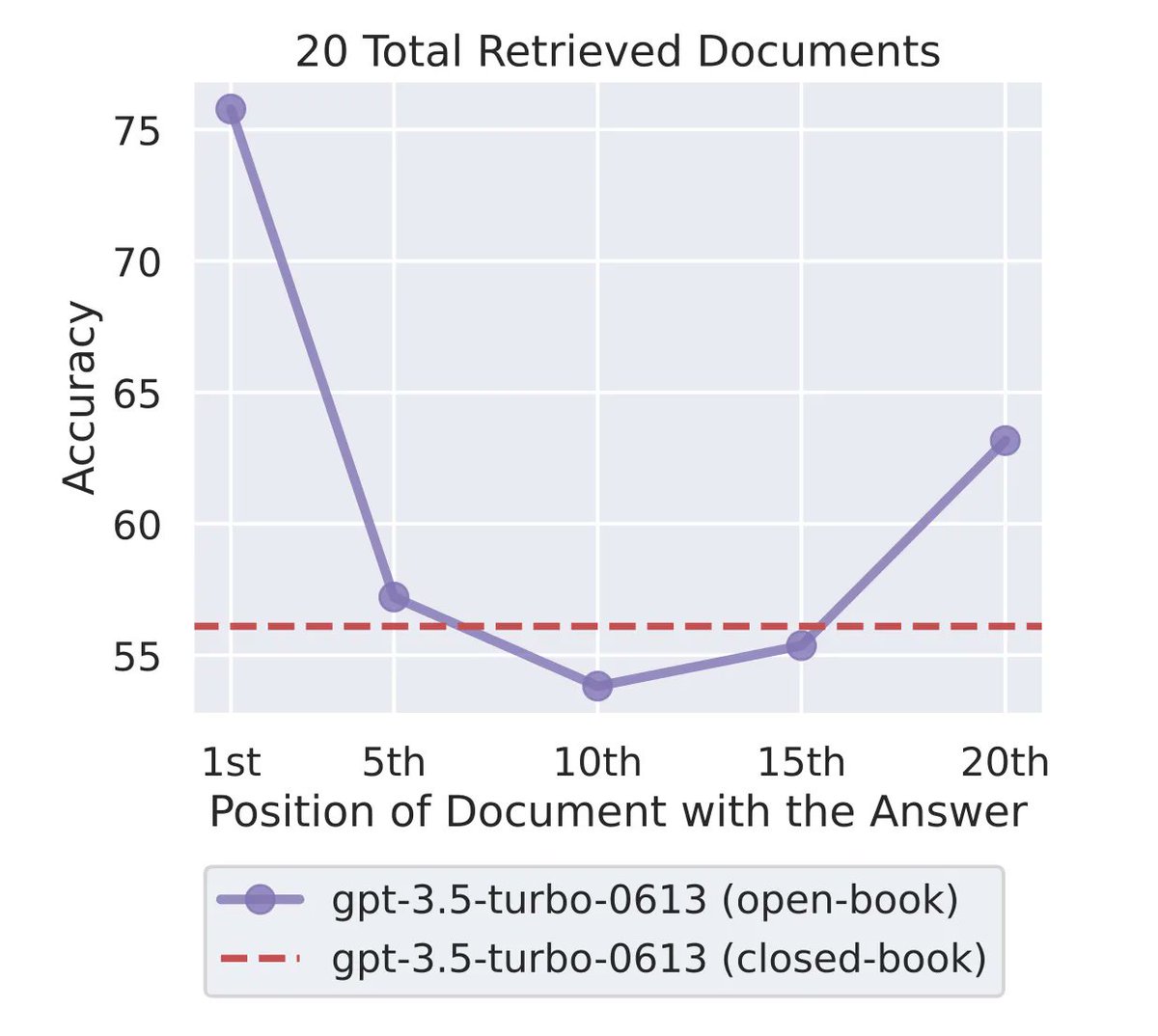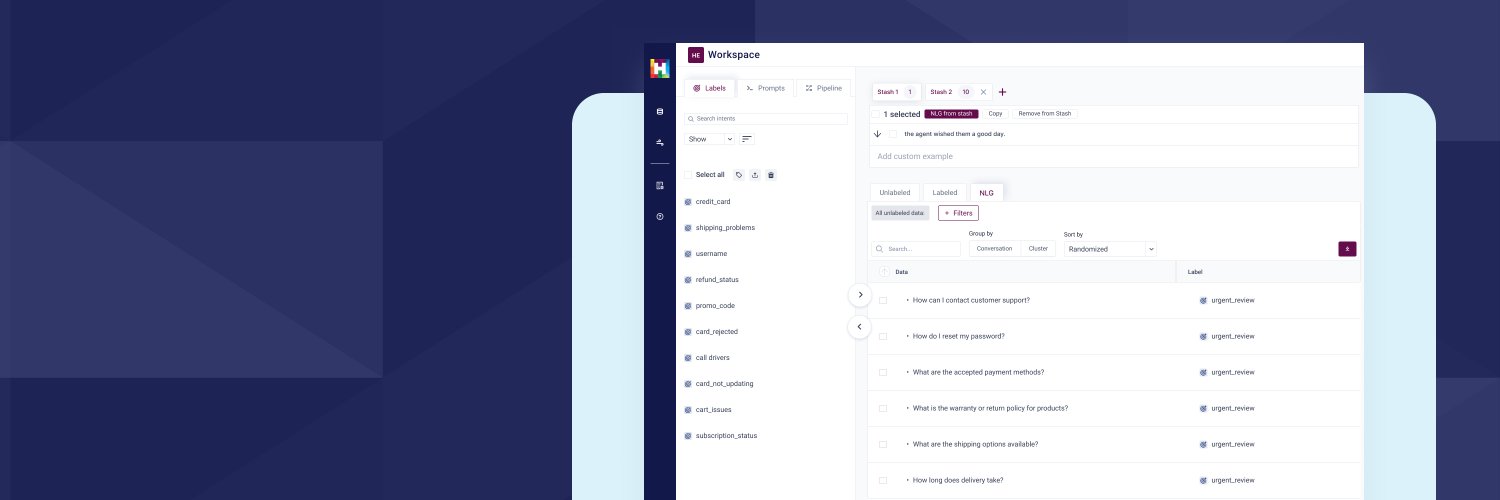

Our partnership with @googlecloud will help bring GenAI into enterprise workflows with easy integrations to #CCAI, #BigQuery, #Dialogflow, and #VertexAI.
More collaborative, more reliable, less technical, and less time-consuming. 🤝
youtube.com/watch?v=-cY7EM…
YouTube
English