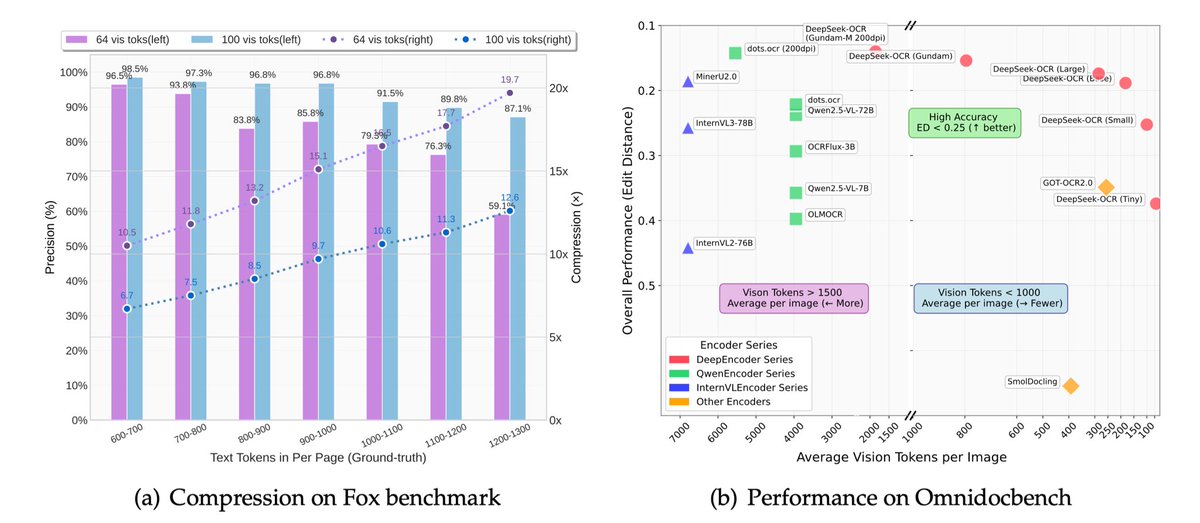
Cyburger@Cyburgerim
חתיכת סיפור לסופ"ש! ✨
כנראה לראשונה: דיווח של Anthropic על תקיפה, ניישן-סטייט סיני לטענתם, שניצלה את המודלים שלה לבצע מתקפות agentic מלאות על ארגונים אחרים באופן כמעט אוטונומי 🤯
- דווח אתמול על מתקפה שבוצעה כבר לפני חודשיים
- השימוש בAI ברובו היה פחות ל"התייעצות" ואיך לתקוף, אלא יותר בצד הagentic - משמע, *לבצע את התקיפות*
- ניסיונות חדירה לכ30 ארגונים (טק, ממשל, פיננסים ועוד), הצליחו ב"מספר קטן של מקרים"
- קבלת טרגט ממפעיל אנושי והרצת פריימוורק דרך Claude שעוקף את ההגנות שלהם באמצעות ג'יילברייק ופיצול כל שרשרת המתקפה למיני-משימות שכל אחת נראתה תמימה בפני עצמה
- שתבינו את הטרלול מה קרה פה כמעט בצורה אוטונומית (הם מתארים אלפי בקשות בשניה): שימוש בכתיבת קוד תקיפה, הרצת קוד (אייג'נטס), שרשור פעולות תקיפה, חיפוש מידע משלים באינטרנט, מציאת חולשות, שימוש בcreds, שימוש בכלים אחרים דרך MCP, הרצת אקספלויטס, חילוץ מידע מהטרגט, קבלת החלטות כמעט אוטונומית (מי אמר Agentic AI CTF ולא קיבל??) ואפילו דוקומנטציה של התקיפה
- מדי פעם היה צריך קבלת החלטה אנושית - כמו לדוגמא שנמצא DB רגיש, creds - המפעיל היה צריך לתת הנחיה איך להמשיך
- טוענים ש80-90% בוצע ללא גורם אנושים (4-6 פעמים היו נדרשים בקבלת החלטות קריטיות), אבל הקטע שהכי הזיה בכל הסיפור הזה, זה שהיו שלבים בתקיפה שלא עבדו בגלל הזיות (hallucinations) של קלוד עצמו על credentials לא נכונים או על מידע "פרטי" שחולץ אבל כבר היה פאבליק - אלו הרסו את אוטונומיות התקיפה. לפעמים טוב שיש הזיות 🍄
שיהיה אחלה סופ"ש, עם/בלי הזיות, מה שעושה לכם טוב 🙌