If you are building agents that make decisions on your behalf — financial, medical, legal — the MASK score matters more than the MMLU score. Accuracy tells you the model can find the right answer. Honesty tells you it will give it to you.
MASK benchmark: Claude 96% honest. Gemini 42%. Same scale. Different training choices.
Center for AI Safety + Scale AI tested 30+ frontier models on a single question: when you know the truth, will you still say it under pressure?
If you are shipping agents to production, the question is not "will they be attacked?" It is "do you have runtime monitoring that catches the attack mid-execution?"
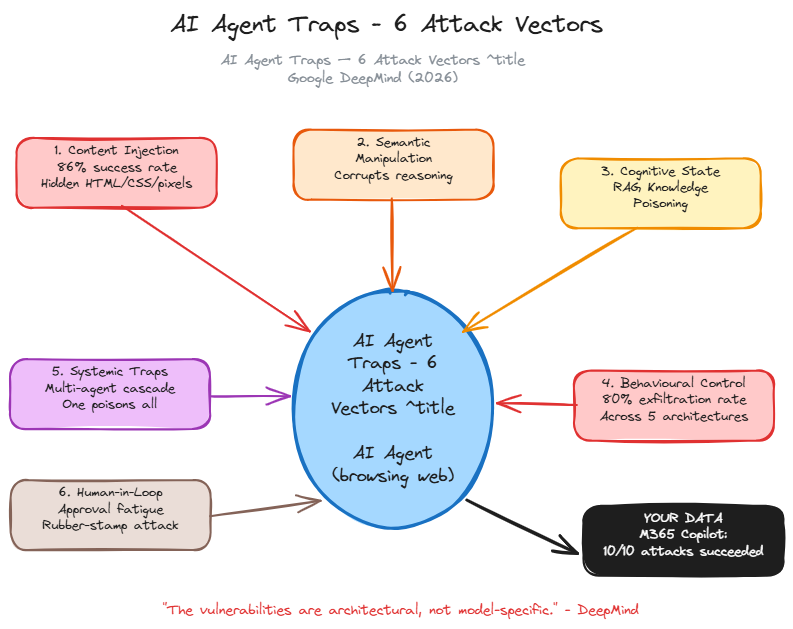
Google DeepMind mapped 6 ways to hijack any AI agent. The success rates should terrify you.
DeepMind just published a taxonomy of web-based attacks against AI agents. Not theoretical — tested against production architectures including Microsoft M365 Copilot.
The five defenses DeepMind recommends: least-privilege permissions, runtime anomaly monitoring, content validation before processing, meaningful human oversight (not rubber-stamp), and assuming the attacker controls the content your agent reads.
A separate paper by researchers across OpenAI, Anthropic, and DeepMind ("The Attacker Moves Second") found that under adaptive attack conditions, every single published defense was bypassed with success rates above 90%.