simingg yyan أُعيد تغريده
simingg yyan
765 posts


simingg yyan
@Samoyansiming
quantitative research. Future and option in China and Europe
shanghai, china انضم Mart 2023
498 يتبع30 المتابعون


simingg yyan أُعيد تغريده

Introducing GLM-5.2: Frontier Intelligence, Open Weights
- Significant improvements in coding and agentic tasks
- Strong long-horizon capabilities with a 1M context window
- Two levels of reasoning effort: GLM-5.2 (max) pushes the limits, while GLM-5.2 (high) strikes a strong balance between performance and token efficiency
- MIT-licensed open weights
- Same API pricing as GLM-5.1
Tech Blog: z.ai/blog/glm-5.2
Weights: huggingface.co/zai-org/GLM-5.2
API: docs.z.ai/guides/llm/glm…
Coding Plan: z.ai/subscribe
Chat: chat.z.ai

English
simingg yyan أُعيد تغريده

Kimi 2.7 ranked 2nd after Fable 5 and before GPT-5 xhigh
We have re-run our ErdosBench smoke test on 14 problems with Kimi 2.7, Qwen 3.7 Max, Grok 4.3 and compared it with the top performers from previous runs.
Kimi 2.7 is amazingly good. More below.

English
simingg yyan أُعيد تغريده

GLM-5.2 is Fully Open, Frontier Intelligence Belongs to Everyone
Today, the sudden restriction of certain frontier models is deeply regrettable. At a time when access to frontier models is abruptly cut off for non-technical reasons, we are even more convinced of one thing: science should be global.
The path to AGI (Artificial General Intelligence) must never be enclosed by high walls. We have always believed that AGI should be the cornerstone for all of humanity to collaboratively explore the boundaries of intelligence and solve complex challenges, rather than a privilege monopolized by a few rules and subject to revocation at any moment. In the face of external blockades and restrictions, our attitude is one of radical openness. Frontier intelligence must remain open-source, accessible, and buildable, serving every dedicated developer.
GLM-5.2 is Zhipu's most capable open-source model to date. It not only supports a truly usable 1M context window but also maintains a continuous lead in the independent completion of long-horizon tasks, providing solid foundational support for building complex agent applications. It also continues to be our main engine for creating the strongest domestic coding model.
Tonight at 5:21—at this special moment—GLM-5.2 will officially be available to all GLM Coding Plan users (including Lite / Pro / Max). The API will also go live next week.
A step closer to frontier intelligence for everyone.
The future of AI is open, and it is for the people.
ModelKey: GLM-5.2
English
simingg yyan أُعيد تغريده

Un desarrollador ucraniano creó un agujero negro en su terminal para obligarse a tomar descansos.
Cuanto más trabajas sin parar, más crece y deforma tu código con su lente gravitacional. Descansas y se encoge.
Español
simingg yyan أُعيد تغريده







@goshi_aoki 这场ai竞赛我是真看空中国的,中国这些企业都是在抢客户抢人,并不在乎客户质量所以都在发红包压价格炒作爱国
但是美国的企业是抢投资和能源,所以着力点在挖护城河和技术研发上
中文

中国の浙江大学(Zhejiang University)のComputer Scienceの修士課程を1年前に修了しましたが、中国人のトップAI人材との対話や大学院に在籍する中で知った、中国のAI人材育成システムについて、まとめてみました↓
日本語
simingg yyan أُعيد تغريده

为什么Muon训练大模型比Adam快近两倍,却没人说清原因?这个困局直接影响下一代优化器设计。这篇论文从曲率切入,把损失下降拆成一阶增益和二阶曲率惩罚,惊讶发现两者步长相当,但Muon的归一化方向锐度NDS显著更低——不是步大,是方向更聪明。尤其数据不平衡会放大这个优势,中后期训练核心来自更小的层内曲率。理论加实验,终于把玄学变成几何直觉。
arxiv.org/abs/2606.04662
中文
simingg yyan أُعيد تغريده

simingg yyan أُعيد تغريده


simingg yyan أُعيد تغريده

simingg yyan أُعيد تغريده

Interested in learning how to run RL at scale? Here are the best resources to read…
Research on Scaling RL
1. The Art of Scaling RL compute for LLMs: arxiv.org/abs/2510.13786
2. Scaling Behaviors of LLM RL Post-Training: arxiv.org/abs/2509.25300
3. Optimally Scaling Sampling Compute for LLM RL: arxiv.org/abs/2603.12151
4. Scaling up RL: arxiv.org/abs/2507.12507
5. ProRL V2 - Prolonged Training Validates RL Scaling Laws: hijkzzz.notion.site/prorl-v2
6. Polaris - A Recipe for Scaling RL with Reasoning Models: hkunlp.github.io/blog/2025/Pola…
RL Frameworks
1. Hybrid Flow (early outline of the verl framework): arxiv.org/abs/2409.19256
a. More up-to-date info can be found here: arxiv.org/abs/2601.18150
2. AReal - Large-Scale Async RL: arxiv.org/abs/2505.24298
3. PipelineRL - Fast On-Policy RL: arxiv.org/abs/2509.19128
4. AsyncFlow - Async Streaming RL: arxiv.org/abs/2507.01663
RL for Agents
1. DeepSWE - Open Coding Agent Trained w/ RL: together.ai/blog/deepswe
2. AutoForge - Environment Synthesis for Agentic RL: arxiv.org/abs/2512.22857
3. Agent-R1 - Training Agents w/ End-to-End RL: arxiv.org/abs/2511.14460
4. AgentRL - Scaling RL for Multi-Turn, Multi-Task Agents: arxiv.org/abs/2510.04206
5. The Landscape of Agentic RL: arxiv.org/abs/2509.02547
6. Training SWE Agents with RL: arxiv.org/abs/2508.03501
Case Studies & Tech Reports
1. Kimi tech reports:
a. Kimi K2 - Open Agentic Intelligence: arxiv.org/abs/2507.20534
b. Kimi End-to-end Agentic RL: moonshotai.github.io/Kimi-Researche…
c. Kimi K1.5 - Scaling RL for LLMs: arxiv.org/abs/2501.12599
2. Composer series from Cursor:
a. Composer 2: arxiv.org/abs/2603.24477
b. Composer 2.5: cursor.com/blog/composer-…
3. Olmo 3 (also has open code / data): arxiv.org/abs/2512.13961
4. MiniMax tech reports:
a. MiniMax-M2: arxiv.org/abs/2605.26494
b. MiniMax-M1: arxiv.org/abs/2506.13585
5. Nemotron 3 (NVIDIA): arxiv.org/abs/2512.20856

English
simingg yyan أُعيد تغريده

I am a big fan of Jianlin Su's blog because it always starts from first principles in mathematics, rather than "ML tricks", to approach a typical ML problem (eg. training-free MoE load balancing).
Here is me trying to "reinvent" one such blog which provides an elegant alternative to compute Muon, by filling in all the derivations that the blog skips for a less math-savvy audience (besides being entirely in Mandarin).
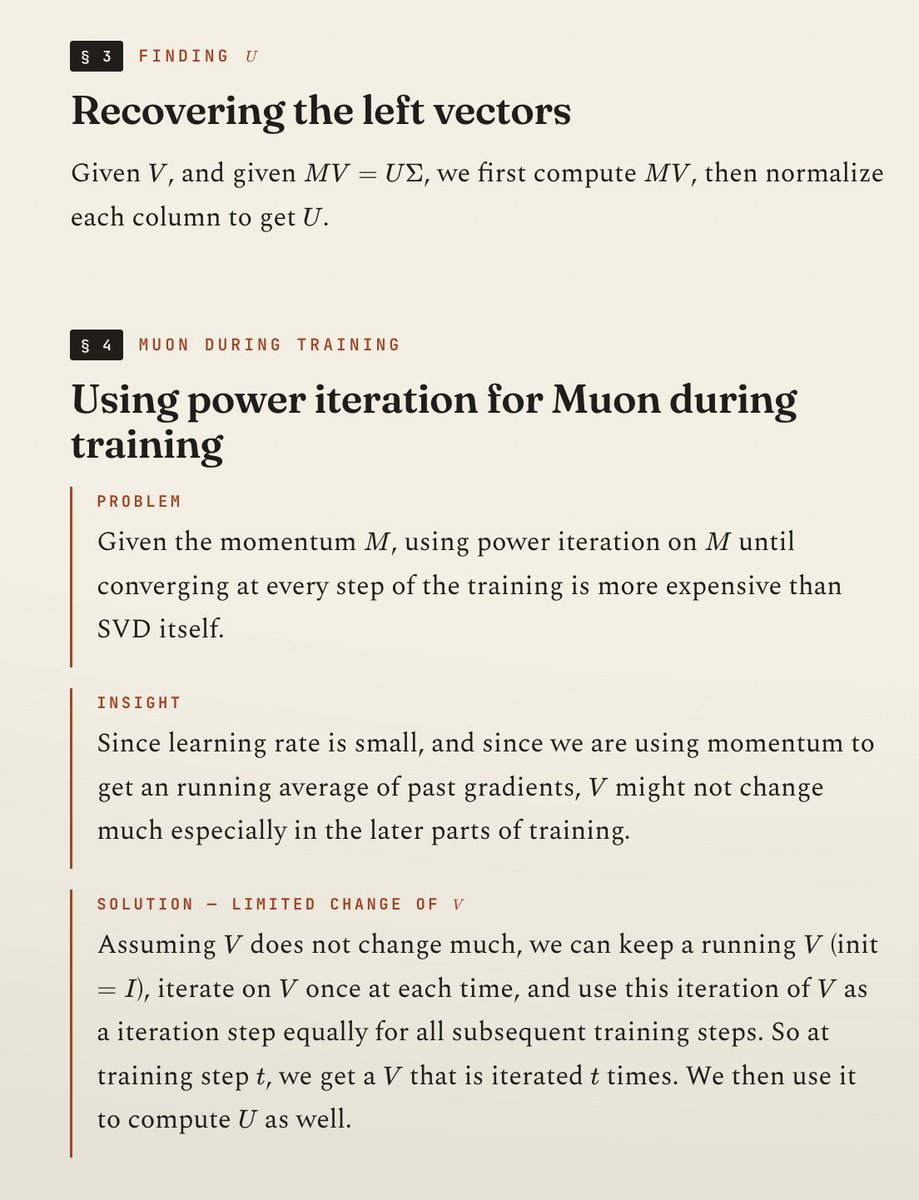
The goal of the blog is to find a way to compute a essential component of Muon, ie. the left and right singular value matrices U and V for the gradient G, **individually**. In the standard form, Muon really just needs their product UV^T, hence the standard way to compute it via computing a low-rank polynomial of G many times ("Newton-Schulz"). But there are more variants of Muon to control the properties of model updates if we can get both individually, hence the blog's proposal to revisit some fundamental linear algebra techniques for the computation.
The methodological takeaway from the blog's thought process is that there are three components to breaking down a ML problem: (1) how to be able to compute something (power iteration), (2) how to compute it fast (cholesky decomposition), and (3) how to compute it accurately given finite floating points (repeated orthogonalization). The goal of reading inspiring blogs like this is, in Feynman's term, to be able to "reinvent" them at any time to grasp the fundamental approach of doing similar work.
Original blog: kexue.fm/archives/11654



English
simingg yyan أُعيد تغريده

训练小模型:2026 年最被低估的 AI 技能
2026 年 5 月 11 日,一个叫 CJ Zafir 的人发了一条推文。他想教普通人 fine-tune 开源模型。
2538 个赞,316 次转发,178,000 次观看。这条推文炸了。不是因为他发明了什么新东西——Unsloth 早在 2023 年就开源了,Hugging Face 上的 fine-tuning 教程有几百篇。炸了是因为他在一个所有 AI 公司都在比赛造「更大模型」的时候,反手指向了完全相反的方向:小模型。你自己训练的。在 Colab 上。花几十美元。
两个月过去了。CJ 没有停。
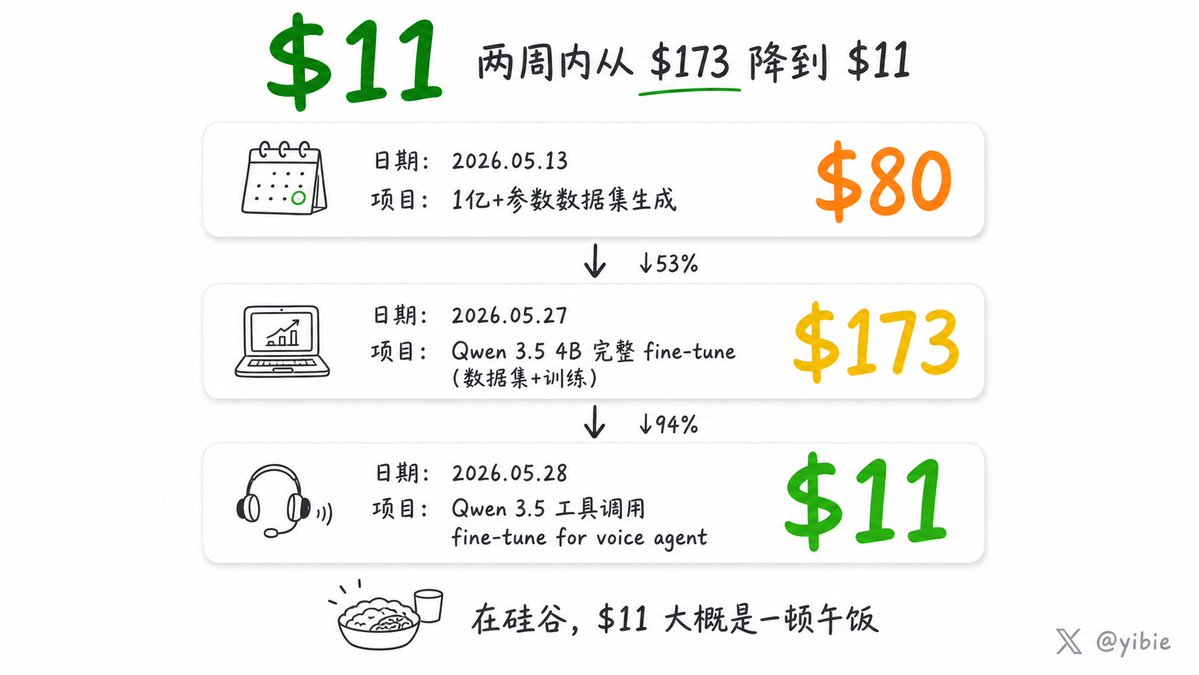
他把这条推文变成了一套完整的方法论:Codex 5.5 做大脑规划工作流,DeepSeek v4 Pro 做肌肉批量生成数据,Unsloth 做训练引擎,Qwen 3.5 4B 做基座模型。然后他用这套方法论,花了 $173 训练出一个 4B 模型,在垂直任务上精度 96%+,击败了 20 倍大的模型。 再后来他做了个 voice agent 的工具调用 fine-tune——成本 $11。
从 $80 到 $173 到 $11。这不是渐进式优化。这是在重置整个 AI 部署的经济学。
一、CJ 方法论:为什么值得认真对待
CJ 不是第一个倡导 fine-tuning 的人。但他做对了一件事:他把整个流程的成本打到了个人开发者可以承受的水平,并且公开了每一步。
工具链
| 角色 | 工具 | 成本 |
|------|------|------|
| 规划(Orchestrator) | Codex 5.5 | 订阅内 |
| 数据生成(Generator) | DeepSeek v4 Pro | API 按量 |
| 训练框架 | Unsloth | 免费开源 |
| 训练硬件 | Google Colab Pro A100 80GB | ~$0.60/hr |
| 推理部署 | llama.cpp / Ollama | 免费 |
数据流水线
CJ 最核心的洞察不是「用什么工具」,而是「怎么造数据」:
「"Low quality data = Low quality model performance"」
他的流水线是自进化的:Codex 设计工作流 → DeepSeek 批量生成数据行 → 每批次过 Quality Gates → Codex 根据上一批结果优化生成规格。结果是越跑越快、越便宜、质量越高。
$80 生成了 1 亿+参数的高质量数据集。 不是简单 paraphrase,是「手工打造」每一行——Codex 设计的多样化 prompt 模板 + DeepSeek 的高速执行 + 可编程的质量门槛。
模型选择
CJ 实测了 Gemma 4 和 Qwen 3.5 全系列后,结论很明确:
「Qwen 3.5 9B 和 4B 是垂直训练的完美基座模型。Gemma 4 在垂直任务上不及 Qwen 3.5。」
他的 Qwen 3.5 4B fine-tune 在精度和延迟上击败了 20 倍大的模型。不是什么小众 benchmark——是他自己在垂直任务上实测的结果。
二、这不是 CJ 一个人的实验——行业数据在同时发声
CJ 的方法论看起来像「个人黑客技巧」,但独立的数据正在从各个方向验证同一个趋势。
市场规模
SLM(Small Language Model,1B-13B 参数)市场 2024 年达到 65 亿美元,年复合增长率 25.7%。SLM 在大多数企业任务上已经匹配或超过 GPT-3.5 级别性能,只需一小部分成本。
性能
阿里巴巴的 Qwen 3.5 9B 在 MMLU-Pro、GPQA Diamond 和 multilingual MMMLU 三个基准上击败了 OpenAI 的 gpt-oss-120B——13 倍参数差距,小模型胜。
另一项独立的 brand normalization 案例中,一个小模型达到了 90.6% 准确率,超越了 GPT-5.2 和 Gemini 3 Pro。
企业已经在省钱——真正的省钱
| 公司 | 方案 | 效果 |
|------|------|------|
| Knowunity | 用 Distil Labs fine-tune SLM | 推理成本降 68% |
| 某客服 agent | 从通用大模型切换到 fine-tuned SLM | 月成本从 $13,000 降到 $400 |
| EliseAI | 专门训练的垂直小模型用于住房和医疗 | 推理成本降 60%,延迟降 80% |
| AT&T | 专用 SLM 做客服和欺诈检测 | 数百万美元节省 |
400 美元一个月。一个客服 agent。这是几个工程师的年收入可以覆盖无限次 API 调用的部署方案。
三、「数据集工厂」才是真正的护城河
CJ 在 5 月 22 日发了一条推文,八个词:
「"The moat might not be the fine-tune itself. It might be the dataset factory."」
这是整个小模型运动最重要的洞察。Fine-tuning 技能本身正在被民主化——Unsloth 已经能在 3GB VRAM 上训练,Colab 免费提供 GPU,CJ 连 prompt 模板都公开了。当人人都能做 fine-tune 的时候,差异化从「会不会做」转移到了「数据从哪里来」。
中文社区的 AKIRAXCLAW 在一篇分析里补了一个关键观察:
「「CJ 的工作流在 2026 年多数是业界共识,但真正难点不是工具——而是你有没有 200 笔干净数据 + 自动评估脚本。」」
在 CJ 的体系里,Codex 的核心角色是 orchestrator,不是因为它比 DeepSeek 聪明,而是因为它能设计数据流水线、构建 Quality Gates、自进化优化生成规格——它在管理数据生产的质量系统,而不仅仅是生产数据。
四、从边缘到生产线:部署已经在发生
SLM fine-tune 的部署门槛已经降到消费级硬件。Unsloth 2.0 支持 GGUF 量化导出 + llama.cpp / Ollama 部署。一个 3B 参数量化到 INT4 后占用 1.5-2GB 内存,可以在树莓派 5 上运行。Qwen 3-0.6B 在 Pixel 8 和 iPhone 15 Pro 上实现约 40 tokens/s 推理。
2024 年你可能需要一台 A100 才能跑 fine-tune。2026 年你可以在 Colab 上训练、在手机上推理。这种从「数据中心才能碰」到「个人设备上运行」的变化,是 Platform Shift 级别的。
而 NVIDIA 在推动的「Data Flywheel Blueprint」——用生产流量持续生成训练数据,自动 fine-tune,自动部署——正在把这个流程变成企业基础设施。NVInfo AI 用这个方案在三个月内把内部知识助手的质量提升到覆盖 30,000 名员工。
五、成本轨迹:从「公司预算」到「午饭钱」
CJ 的公开成本记录是最好的注脚:
| 日期 | 项目 | 成本 |
|------|------|------|
| 05-13 | 1 亿+参数数据集生成 | ~$80 |
| 05-27 | Qwen 3.5 4B 完整 fine-tune | ~$173 |
| 05-28 | Qwen 3.5 tool calling for voice agent | $11 |
$11。这在硅谷大概是一顿午饭。在印度、东南亚、非洲,是一个独立开发者完全负担得起的预算。fine-tune 已经从「大公司才有资格做的研发项目」变成了「个人开发者用午休时间能完成的 side project」。
六、结论:学会训练你的第一个模型
CJ 给的学习路线图异常简单:
1. 从 1B-4B 小模型开始,不要一上来就搞大模型
2. 用 Colab Pro(A100 ≈ $0.60/hr),不要急着买 GPU
3. 先 fine-tune 7-10 个模型积累经验(SFT → LoRA/QLoRA → GRPO/DPO)
4. 用 Codex 做规划,DeepSeek 做数据生成
5. 理解量化(GGUF)、本地推理(llama.cpp)、KV 缓存
他甚至在 5 月 23 日直接发布了一个「复制粘贴就能用」的 prompt——把整个学习路径封装成一段对话,扔进 Codex 或 ChatGPT,让 AI 带你从 beginner 到 advanced。
这就是 2026 年 AI 技能民主化的真实面貌:不是每个人都需要学会训练模型。但学会训练小模型的人,不再需要 10 人团队和 10 万美元预算。
通用大模型的军备竞赛还在继续。GPT-5、Claude Opus 5、Gemini 3 会越来越强。但越来越多的真实场景正在证明:一个花了 $173 训练的 4B 小模型,在你自己的数据上,比你花 $200/月订阅的通用大模型更好用。不是因为小模型更聪明。是因为它只做了你需要的那一件事。
参考来源:CJ Zafir X 推文系列 (2026.05.11-05.28);AKIRAXCLAW 中文分析;Alibaba Qwen 3.5 benchmark (VentureBeat);Unsloth 2.0 文档;NVIDIA Data Flywheel Blueprint;AT&T / EliseAI / Knowunity / Chanl.io 企业案例;Manicode / Arendil 独立 benchmark;SLM Market Report 2024-2026


中文
simingg yyan أُعيد تغريده


simingg yyan أُعيد تغريده

simingg yyan أُعيد تغريده
