تغريدة مثبتة
Alignment Lab AI
7.2K posts


Alignment Lab AI
@alignment_lab
Devoted to addressing alignment. We develop state of the art open sourced AI. https://t.co/oANsMnut7V https://t.co/6aJDLUvuU5
Your Digital Ecosystem انضم Nisan 2023
4K يتبع12.5K المتابعون
Alignment Lab AI أُعيد تغريده

Learning to write kernels might be the highest-ROI activity for displaced SWEs:
→ prereq: reasonable engineering ablity
→ six to twelve months of study
→ millions of dollars, mark zuckerberg showing up at your house to hire you, etc.
i wish this were an exaggeration
English
Particularly in terms of quantization of features to effective regimes, there's a very large amount of that explicitly operating on actual measurements of entropy unsupervised for the purpose of allowing a maximally efficient representation to emerge, because the computational substrate is itself still dominated by the entropy costs as a primary consideration
English

The other problem with this paper is that discretization is treated here as black box which only mysterious "mapmaker" can do. But discretization happens constantly in nature. Sedimentation creates separate rock layers, cells are discretized by membranes, \
Séb Krier@sebkrier
An excellent paper for anyone interested in rigorous physicalist argument against computational functionalism. Alex is a fantastic, careful thinker and influenced my views a lot; we're working on a broader blog post breaking these concepts down, stay tuned! 🐙
English

absolutely disagree, even if we stopped with just what we have now it would take years forr society and for the delpoyment of it to really be appreciable with the scale, the current stopgap is just how long it takes people to understand, not whats avaliable as currently known/extant implementation
English

If AI progress stopped now, it would be a normal technology. One-off 5-10% productivity growth. Some routine white collar tasks automated. We chat to AI tools a lot. But no big economic or scientific acceleration. Ergo we don't have AGI.
English
Alignment Lab AI أُعيد تغريده

Need more Claude, need more Codex, need more OpenCode or Pi? Gemini, Kimi? You got this
English
until i read this paper i was losing my mind not able to figure out wh this architecture i had was outperforming everything else so hard (fully constructing mostly reasonable sentences out of bytes in a few minutes at 5m parameters) after reading the paper and doing some analysis and ablations, its because i was using 768d model and 256 vocab (plus some other stuff to do with num params to dim) that avoided the bottleneck they mention almost entirely by acident
English

@pmddomingos if only performance were the only thing that kept it in the frontier labs
English

And then the RL bubble burst, saving trillions of dollars.
Yulu Gan@yule_gan
Simply adding Gaussian noise to LLMs (one step—no iterations, no learning rate, no gradients) and ensembling them can achieve performance comparable to or even better than standard GRPO/PPO on math reasoning, coding, writing, and chemistry tasks. We call this algorithm RandOpt. To verify that this is not limited to specific models, we tested it on Qwen, Llama, OLMo3, and VLMs. What's behind this? We find that in the Gaussian search neighborhood around pretrained LLMs, diverse task experts are densely distributed — a regime we term Neural Thickets. Paper: arxiv.org/pdf/2603.12228 Code: github.com/sunrainyg/Rand… Website: thickets.mit.edu
English
@stalkermustang yes, absolutely that is exactly how bad things *have been*
pretty rough
English

Ok serious question. That's like the 10th META paper, where the top models used are o1 and o3, outdated by more than 8 months. What's going on?
Do they know Claude 4.x and GPT5.x exist?
Are things really that bad, as if the company would gate the access to the frontier models for researchers?
@giffmana wtf
Yixin Liu@YixinLiu17
Introducing Examining Reasoning LLMs-as-Judges in Non-Verifiable LLM Post-Training LLM alignment in non-verifiable domains is hard because there is often no clear ground-truth reward. A natural idea is to use reasoning LLM judges inside the RL training loop — but do they actually work better than standard judges? We study this question in a controlled setup with a gold-standard judge, and find that reasoning judges train much stronger policies under gold evaluation, while non-reasoning judges are much more prone to reward hacking. But there is also a catch: these reasoning-judge-trained policies can learn highly effective adversarial strategies. In our study, a Llama-3.1-8B policy trained with a Qwen3-4B reasoning judge reaches 89.6% on the creative writing subset of Arena-Hard-V2, close to o3 (92.4%). 📚 Paper: arxiv.org/abs/2603.12246 See details below 👇 🧵1/N
English
so it turns out
the fast inv sqrt trick from Quake III Arena, (according to the internet from either or both of Greg Walsh and @ID_AA_Carmack )
entirely critical for some work im doing building linear models out of pretrained nonlinear ones.
rmsnorm and softmax both would have gone unsolved if not for it.
the unlock here is extremely op, im stoked
English
@nthngdy this is getting me so hard in the confirmation bias right now, this explains a ton!
English

🧵New paper: "Lost in Backpropagation: The LM Head is a Gradient Bottleneck"
The output layer of LLMs destroys 95-99% of your training signal during backpropagation, and this significantly slows down pretraining 👇

English
@sebkrier is this paper operating on the premise that what happens inside of a computer is *not* happening in reality/subject to thermodynamic constraints?
English
@sebkrier ive read this twice now, i dont get where it identifies which party is which and why, and what the delta is between a compression algorithm producing a codebook of class labels like a rANS, or me definitely learning language from my parents?
English

An excellent paper for anyone interested in rigorous physicalist argument against computational functionalism. Alex is a fantastic, careful thinker and influenced my views a lot; we're working on a broader blog post breaking these concepts down, stay tuned! 🐙

Alexander Lerchner@AlexLerchner
🧵1/4 The debate over AI sentience is caught in an "AI welfare trap." My new preprint argues computational functionalism rests on a category error: the Abstraction Fallacy. AI can simulate consciousness, but cannot instantiate it. philpapers.org/rec/LERTAF
English
@sebkrier It's genuinely crazy, people have no idea how efficient the tech actually is, no one ever really considers what something like mohrs law running for so long actually means
You can only double something so many times before it gets entirely out of hand
English
Every day I notice inefficient processes that could be automated, yet won't be for a while bc of bureaucracy, legacy infra, misaligned incentives, inertia & status quo bias. Eventually competition forces it but it's so slow! "What could be, completely burdened by what has been."
English
Alignment Lab AI أُعيد تغريده

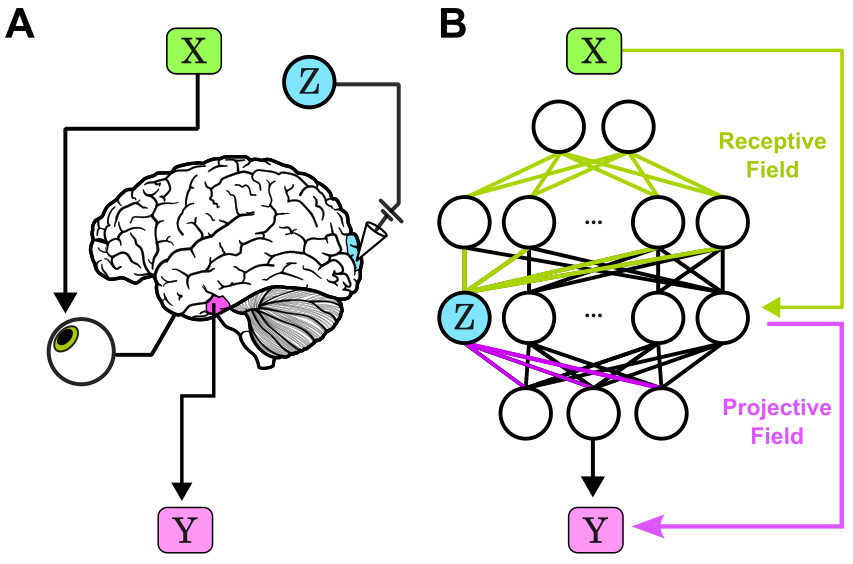
Trying to interpret how a neural-network does what it does? Activations tell you if a neuron responded. Contributions tell you if a neuron mattered!
New paper from myself, @Zaki_Alaoui1, @sunnyliu1220 , @SuryaGanguli, and Steve Baccus: arxiv.org/abs/2603.06557
English
Alignment Lab AI أُعيد تغريده


@alignment_lab @servamind Great lineup—interested in the computational cognition + encoding angle. Will catch the recording if available.
English
IN A FEW HOURS GUYS, DONT MISS IT
if youre interested in computational cognition, data agnostic lossless universal encoding, and ai native infra that touches both, @servamind is droppng huge secrets!
Servamind@servamind
Watch Andrew Coward Discuss Types of Memory in our Lessons from Biology for AI series before our X space tomorrow at 4pm PST!
English
Alignment Lab AI أُعيد تغريده


