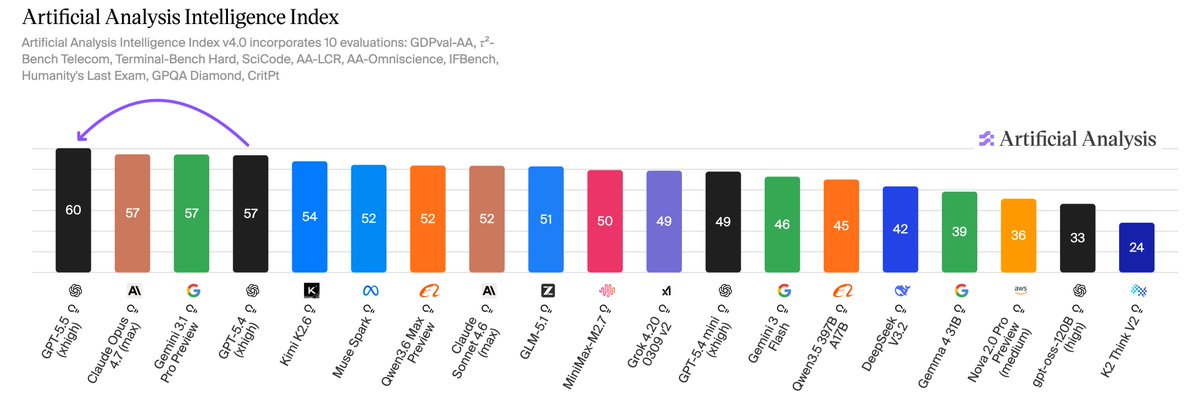
Yaser Martinez أُعيد تغريده

openai built a model that HIDES personal data in text so nothing leaks
i flipped it INSIDE OUT
same 1.5B weights, same label taxonomy, but instead of masks you get structured spans, name, email, phone, bank account, address, secrets, char offsets and all
point it at logs, dumps, stolen inboxes and it just... returns every private thing in the pile

English